 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptual Codebook Learning for Vision-Language Models
Paper and Code
Jul 02, 2024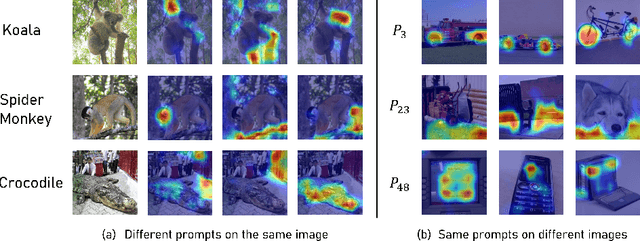
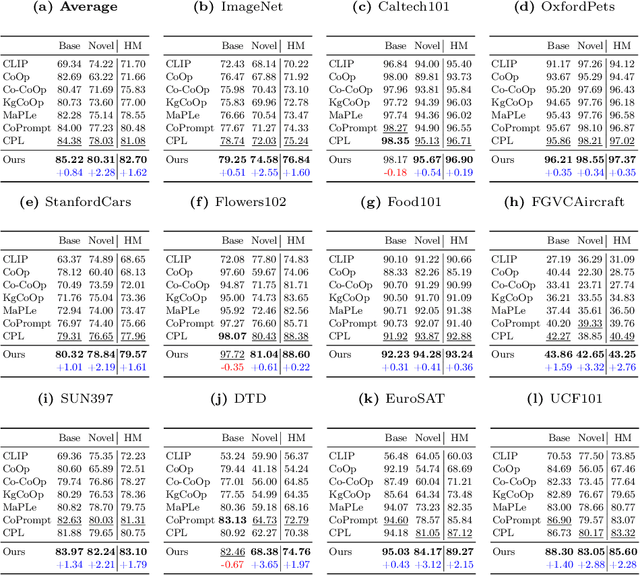
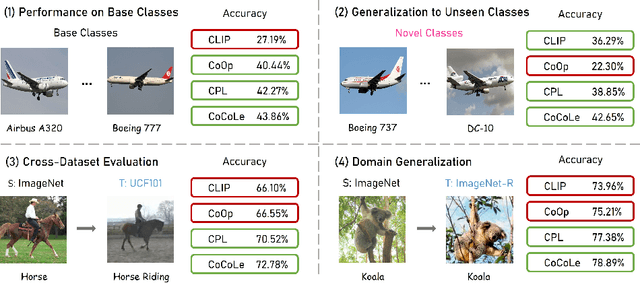
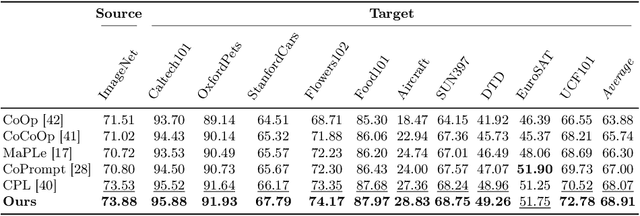
In this paper, we propose Conceptual Codebook Learning (CoCoLe), a novel fine-tuning method for vision-language models (VLMs) to address the challenge of improving the generalization capability of VLMs while fine-tuning them on downstream tasks in a few-shot setting. We recognize that visual concepts, such as textures, shapes, and colors are naturally transferable across domains and play a crucial role in generalization tasks. Motivated by this interesting finding, we learn a conceptual codebook consisting of visual concepts as keys and conceptual prompts as values, which serves as a link between the image encoder's outputs and the text encoder's inputs. Specifically, for a given image, we leverage the codebook to identify the most relevant conceptual prompts associated with the class embeddings to perform the classification. Additionally, we incorporate a handcrafted concept cache as a regularization to alleviate the overfitting issues in low-shot scenarios. We observe that this conceptual codebook learning method is able to achieve enhanced alignment between visual and linguistic modalities. Extensive experimental results demonstrate that our CoCoLe method remarkably outperforms the existing state-of-the-art methods across various evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization tasks. Detailed ablation studies further confirm the efficacy of each component in CoCoLe.