 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Continual Learning
Paper and Code
May 23, 2024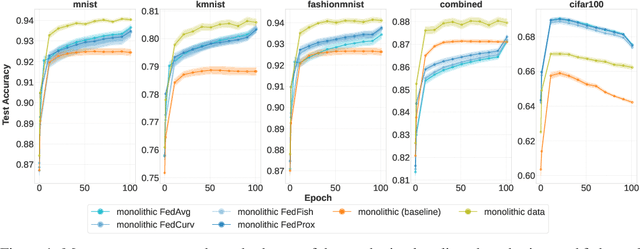
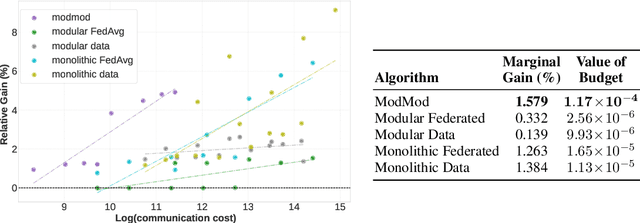
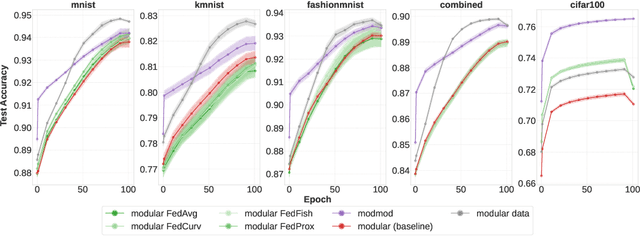

This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.