 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation
Paper and Code

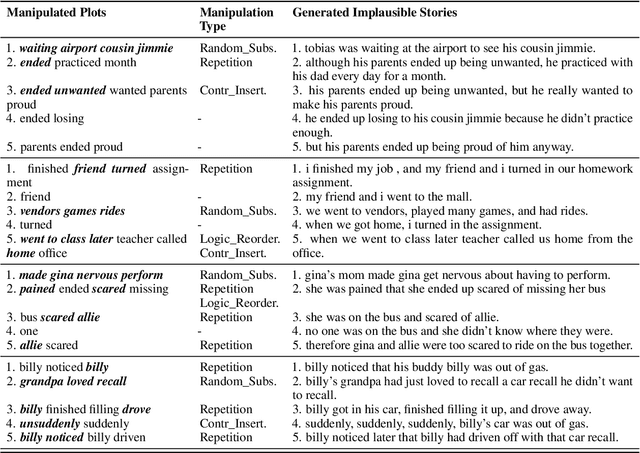
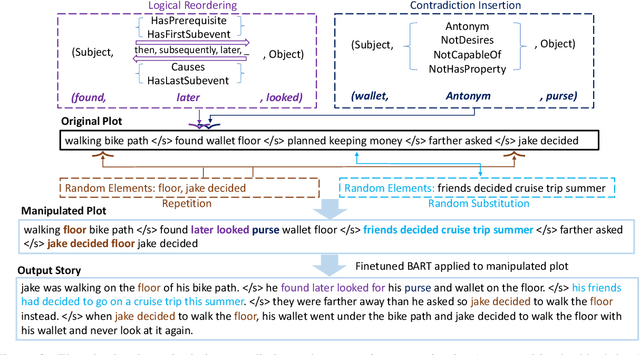
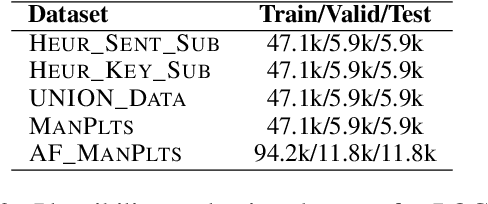
With the recent advances of open-domain story generation, the lack of reliable automatic evaluation metrics becomes an increasingly imperative issue that hinders the fast development of story generation. According to conducted researches in this regard, learnable evaluation metrics have promised more accurate assessments by having higher correlations with human judgments. A critical bottleneck of obtaining a reliable learnable evaluation metric is the lack of high-quality training data for classifiers to efficiently distinguish plausible and implausible machine-generated stories. Previous works relied on \textit{heuristically manipulated} plausible examples to mimic possible system drawbacks such as repetition, contradiction, or irrelevant content in the text level, which can be \textit{unnatural} and \textit{oversimplify} the characteristics of implausible machine-generated stories. We propose to tackle these issues by generating a more comprehensive set of implausible stories using {\em plots}, which are structured representations of controllable factors used to generate stories. Since these plots are compact and structured, it is easier to manipulate them to generate text with targeted undesirable properties, while at the same time maintain the grammatical correctness and naturalness of the generated sentences. To improve the quality of generated implausible stories, we further apply the adversarial filtering procedure presented by \citet{zellers2018swag} to select a more nuanced set of implausible texts. Experiments show that the evaluation metrics trained on our generated data result in more reliable automatic assessments that correlate remarkably better with human judgments compared to the baselines.