 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Let's Eat Grandma": When Punctuation Matters in Sentence Representation for Sentiment Analysis
Paper and Code
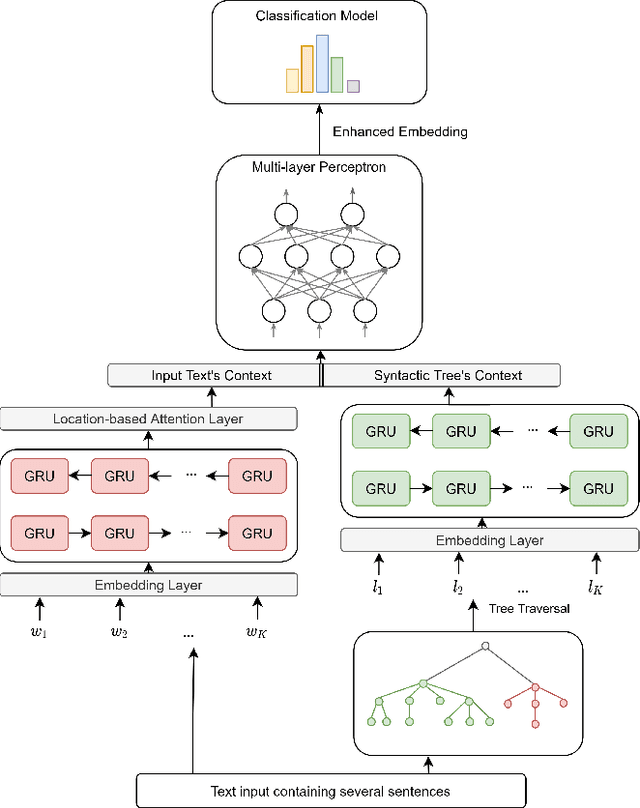

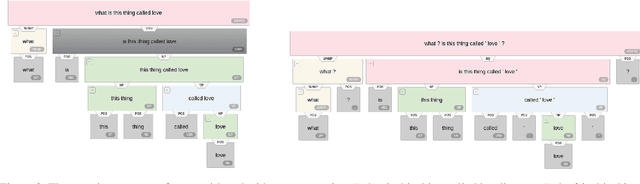
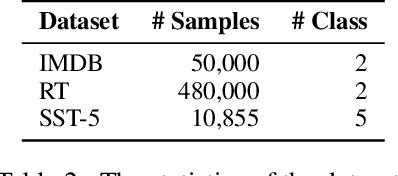
Neural network-based embeddings have been the mainstream approach for creating a vector representation of the text to capture lexical and semantic similarities and dissimilarities. In general, existing encoding methods dismiss the punctuation as insignificant information; consequently, they are routinely eliminated in the pre-processing phase as they are shown to improve task performance. In this paper, we hypothesize that punctuation could play a significant role in sentiment analysis and propose a novel representation model to improve syntactic and contextual performance. We corroborate our findings by conducting experiments on publicly available datasets and verify that our model can identify the sentiments more accurately over other state-of-the-art baseline methods.