 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
Paper and Code
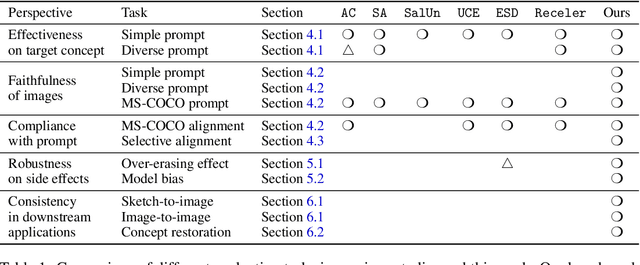

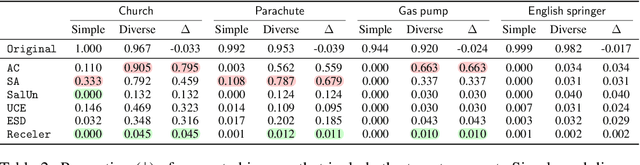
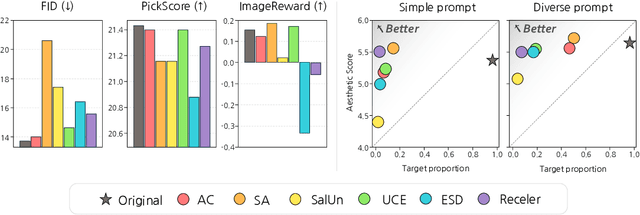
As text-to-image diffusion models become advanced enough for commercial applications, there is also increasing concern about their potential for malicious and harmful use. Model unlearning has been proposed to mitigate the concerns by removing undesired and potentially harmful information from the pre-trained model. So far, the success of unlearning is mainly measured by whether the unlearned model can generate a target concept while maintaining image quality. However, unlearning is typically tested under limited scenarios, and the side effects of unlearning have barely been studied in the current literature. In this work, we thoroughly analyze unlearning under various scenarios with five key aspects. Our investigation reveals that every method has side effects or limitations, especially in more complex and realistic situations. By releasing our comprehensive evaluation framework with the source codes and artifacts, we hope to inspire further research in this area, leading to more reliable and effective unlearning methods.