 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Ensemble Distillation for Domain Generalization
Nov 25, 2022Domain generalization is the task of learning models that generalize to unseen target domains. We propose a simple yet effective method for domain generalization, named cross-domain ensemble distillation (XDED), that learns domain-invariant features while encouraging the model to converge to flat minima, which recently turned out to be a sufficient condition for domain generalization. To this end, our method generates an ensemble of the output logits from training data with the same label but from different domains and then penalizes each output for the mismatch with the ensemble. Also, we present a de-stylization technique that standardizes features to encourage the model to produce style-consistent predictions even in an arbitrary target domain. Our method greatly improves generalization capability in public benchmarks for cross-domain image classification, cross-dataset person re-ID, and cross-dataset semantic segmentation. Moreover, we show that models learned by our method are robust against adversarial attacks and image corruptions.
Learning to Generate Novel Classes for Deep Metric Learning
Jan 04, 2022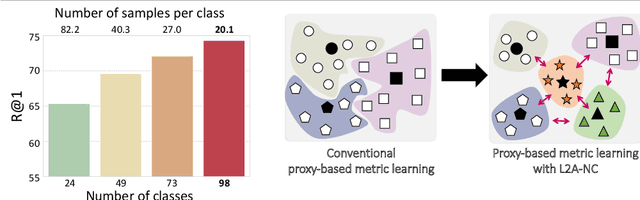
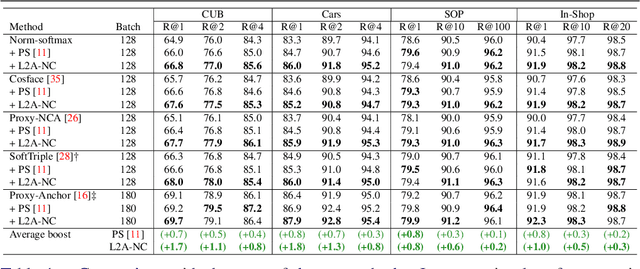
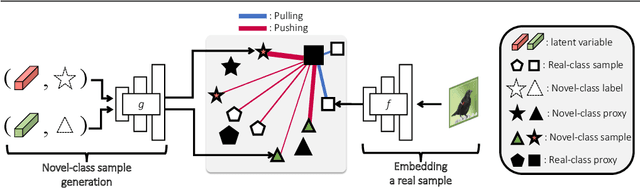
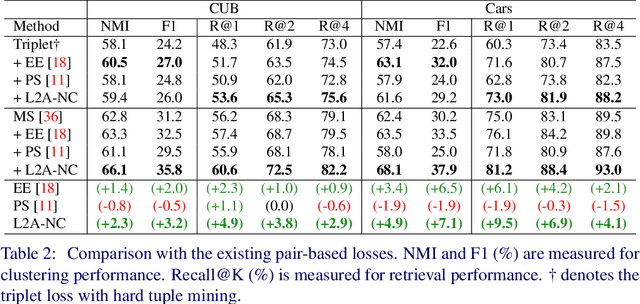
Deep metric learning aims to learn an embedding space where the distance between data reflects their class equivalence, even when their classes are unseen during training. However, the limited number of classes available in training precludes generalization of the learned embedding space. Motivated by this, we introduce a new data augmentation approach that synthesizes novel classes and their embedding vectors. Our approach can provide rich semantic information to an embedding model and improve its generalization by augmenting training data with novel classes unavailable in the original data. We implement this idea by learning and exploiting a conditional generative model, which, given a class label and a noise, produces a random embedding vector of the class. Our proposed generator allows the loss to use richer class relations by augmenting realistic and diverse classes, resulting in better generalization to unseen samples. Experimental results on public benchmark datasets demonstrate that our method clearly enhances the performance of proxy-based losses.