 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Novel Classes for Deep Metric Learning
Paper and Code
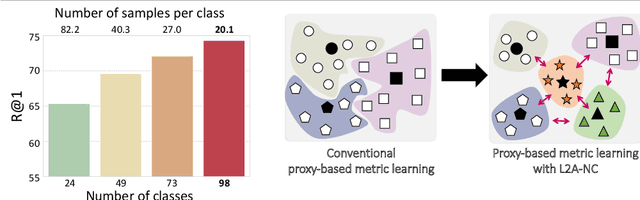
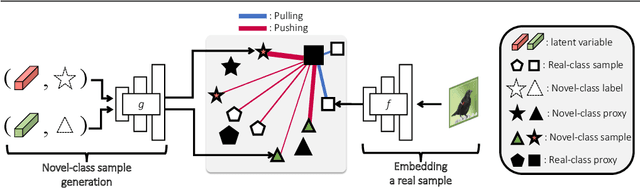
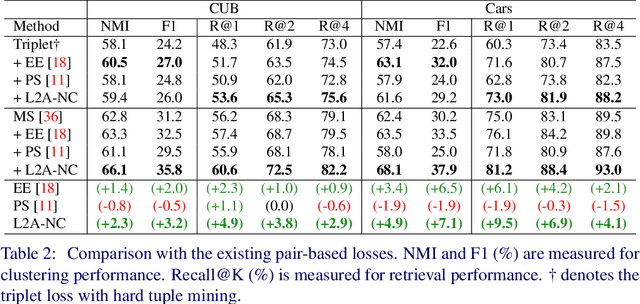
Deep metric learning aims to learn an embedding space where the distance between data reflects their class equivalence, even when their classes are unseen during training. However, the limited number of classes available in training precludes generalization of the learned embedding space. Motivated by this, we introduce a new data augmentation approach that synthesizes novel classes and their embedding vectors. Our approach can provide rich semantic information to an embedding model and improve its generalization by augmenting training data with novel classes unavailable in the original data. We implement this idea by learning and exploiting a conditional generative model, which, given a class label and a noise, produces a random embedding vector of the class. Our proposed generator allows the loss to use richer class relations by augmenting realistic and diverse classes, resulting in better generalization to unseen samples. Experimental results on public benchmark datasets demonstrate that our method clearly enhances the performance of proxy-based losses.