 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Spiking Attention: Accelerating Attention with Stochastic Computing in Spiking Networks
Paper and Code
Feb 14, 2024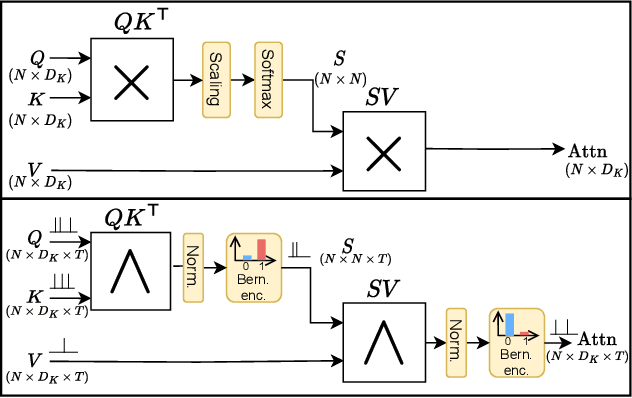
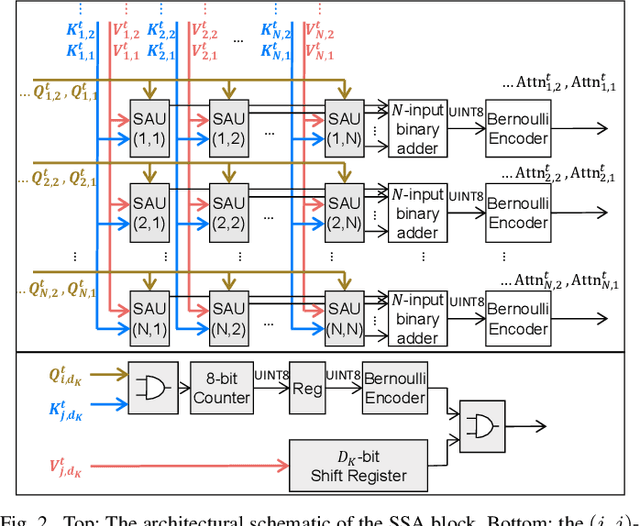

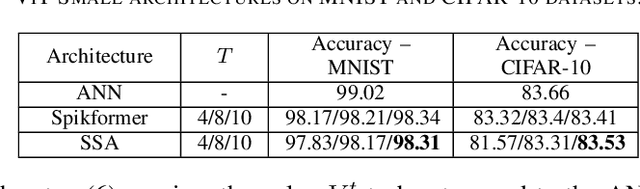
Spiking Neural Networks (SNNs) have been recently integrated into Transformer architectures due to their potential to reduce computational demands and to improve power efficiency. Yet, the implementation of the attention mechanism using spiking signals on general-purpose computing platforms remains inefficient. In this paper, we propose a novel framework leveraging stochastic computing (SC) to effectively execute the dot-product attention for SNN-based Transformers. We demonstrate that our approach can achieve high classification accuracy ($83.53\%$) on CIFAR-10 within 10 time steps, which is comparable to the performance of a baseline artificial neural network implementation ($83.66\%$). We estimate that the proposed SC approach can lead to over $6.3\times$ reduction in computing energy and $1.7\times$ reduction in memory access costs for a digital CMOS-based ASIC design. We experimentally validate our stochastic attention block design through an FPGA implementation, which is shown to achieve $48\times$ lower latency as compared to a GPU implementation, while consuming $15\times$ less power.