 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Fine-Tuning via Backprop-Free Zeroth-Order Optimization
Nov 14, 2025On-device fine-tuning is a critical capability for edge AI systems, which must support adaptation to different agentic tasks under stringent memory constraints. Conventional backpropagation (BP)-based training requires storing layer activations and optimizer states, a demand that can be only partially alleviated through checkpointing. In edge deployments in which the model weights must reside entirely in device memory, this overhead severely limits the maximum model size that can be deployed. Memory-efficient zeroth-order optimization (MeZO) alleviates this bottleneck by estimating gradients using forward evaluations alone, eliminating the need for storing intermediate activations or optimizer states. This enables significantly larger models to fit within on-chip memory, albeit at the cost of potentially longer fine-tuning wall-clock time. This paper first provides a theoretical estimate of the relative model sizes that can be accommodated under BP and MeZO training. We then numerically validate the analysis, demonstrating that MeZO exhibits accuracy advantages under on-device memory constraints, provided sufficient wall-clock time is available for fine-tuning.
Baseline Drift Tolerant Signal Encoding for ECG Classification with Deep Learning
Apr 26, 2024



Common artefacts such as baseline drift, rescaling, and noise critically limit the performance of machine learningbased automated ECG analysis and interpretation. This study proposes Derived Peak (DP) encoding, a non-parametric method that generates signed spikes corresponding to zero crossings of the signals first and second-order time derivatives. Notably, DP encoding is invariant to shift and scaling artefacts, and its implementation is further simplified by the absence of userdefined parameters. DP encoding was used to encode the 12-lead ECG data from the PTB-XL dataset (n=18,869 participants) and was fed to 1D-ResNet-18 models trained to identify myocardial infarction, conductive deficits and ST-segment abnormalities. Robustness to artefacts was assessed by corrupting ECG data with sinusoidal baseline drift, shift, rescaling and noise, before encoding. The addition of these artefacts resulted in a significant drop in accuracy for seven other methods from prior art, while DP encoding maintained a baseline AUC of 0.88 under drift, shift and rescaling. DP achieved superior performance to unencoded inputs in the presence of shift (AUC under 1mV shift: 0.91 vs 0.62), and rescaling artefacts (AUC 0.91 vs 0.79). Thus, DP encoding is a simple method by which robustness to common ECG artefacts may be improved for automated ECG analysis and interpretation.
Stochastic Spiking Attention: Accelerating Attention with Stochastic Computing in Spiking Networks
Feb 14, 2024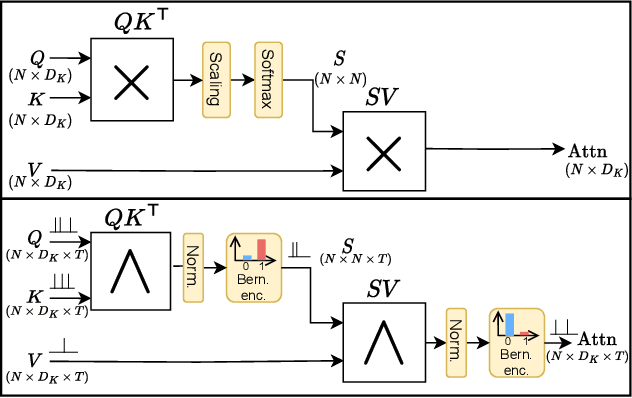
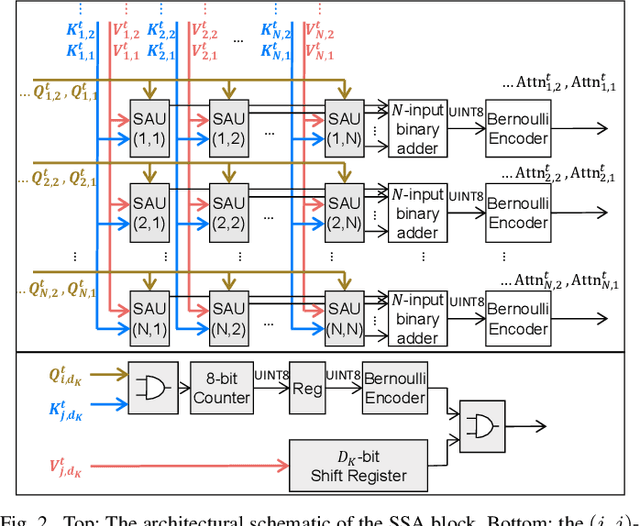

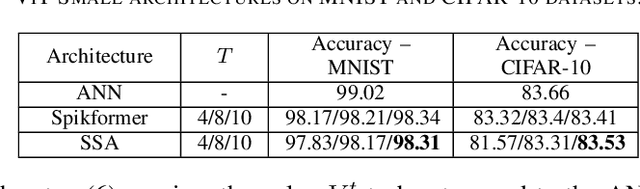
Spiking Neural Networks (SNNs) have been recently integrated into Transformer architectures due to their potential to reduce computational demands and to improve power efficiency. Yet, the implementation of the attention mechanism using spiking signals on general-purpose computing platforms remains inefficient. In this paper, we propose a novel framework leveraging stochastic computing (SC) to effectively execute the dot-product attention for SNN-based Transformers. We demonstrate that our approach can achieve high classification accuracy ($83.53\%$) on CIFAR-10 within 10 time steps, which is comparable to the performance of a baseline artificial neural network implementation ($83.66\%$). We estimate that the proposed SC approach can lead to over $6.3\times$ reduction in computing energy and $1.7\times$ reduction in memory access costs for a digital CMOS-based ASIC design. We experimentally validate our stochastic attention block design through an FPGA implementation, which is shown to achieve $48\times$ lower latency as compared to a GPU implementation, while consuming $15\times$ less power.
Bayesian Inference Accelerator for Spiking Neural Networks
Jan 27, 2024



Bayesian neural networks offer better estimates of model uncertainty compared to frequentist networks. However, inference involving Bayesian models requires multiple instantiations or sampling of the network parameters, requiring significant computational resources. Compared to traditional deep learning networks, spiking neural networks (SNNs) have the potential to reduce computational area and power, thanks to their event-driven and spike-based computational framework. Most works in literature either address frequentist SNN models or non-spiking Bayesian neural networks. In this work, we demonstrate an optimization framework for developing and implementing efficient Bayesian SNNs in hardware by additionally restricting network weights to be binary-valued to further decrease power and area consumption. We demonstrate accuracies comparable to Bayesian binary networks with full-precision Bernoulli parameters, while requiring up to $25\times$ less spikes than equivalent binary SNN implementations. We show the feasibility of the design by mapping it onto Zynq-7000, a lightweight SoC, and achieve a $6.5 \times$ improvement in GOPS/DSP while utilizing up to 30 times less power compared to the state-of-the-art.
Bayesian Inference on Binary Spiking Networks Leveraging Nanoscale Device Stochasticity
Feb 02, 2023Bayesian Neural Networks (BNNs) can overcome the problem of overconfidence that plagues traditional frequentist deep neural networks, and are hence considered to be a key enabler for reliable AI systems. However, conventional hardware realizations of BNNs are resource intensive, requiring the implementation of random number generators for synaptic sampling. Owing to their inherent stochasticity during programming and read operations, nanoscale memristive devices can be directly leveraged for sampling, without the need for additional hardware resources. In this paper, we introduce a novel Phase Change Memory (PCM)-based hardware implementation for BNNs with binary synapses. The proposed architecture consists of separate weight and noise planes, in which PCM cells are configured and operated to represent the nominal values of weights and to generate the required noise for sampling, respectively. Using experimentally observed PCM noise characteristics, for the exemplary Breast Cancer Dataset classification problem, we obtain hardware accuracy and expected calibration error matching that of an 8-bit fixed-point (FxP8) implementation, with projected savings of over 9$\times$ in terms of core area transistor count.