 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Analog Kolmogorov-Arnold Networks based on Reconfigurable Nonlinear-Processing Units
Feb 07, 2026Kolmogorov-Arnold Networks (KANs) shift neural computation from linear layers to learnable nonlinear edge functions, but implementing these nonlinearities efficiently in hardware remains an open challenge. Here we introduce a physical analog KAN architecture in which edge functions are realized in materia using reconfigurable nonlinear-processing units (RNPUs): multi-terminal nanoscale silicon devices whose input-output characteristics are tuned via control voltages. By combining multiple RNPUs into an edge processor and assembling these blocks into a reconfigurable analog KAN (aKAN) architecture with integrated mixed-signal interfacing, we establish a realistic system-level hardware implementation that enables compact KAN-style regression and classification with programmable nonlinear transformations. Using experimentally calibrated RNPU models and hardware measurements, we demonstrate accurate function approximation across increasing task complexity while requiring fewer or comparable trainable parameters than multilayer perceptrons (MLPs). System-level estimates indicate an energy per inference of $\sim$250 pJ and an end-to-end inference latency of $\sim$600 ns for a representative workload, corresponding to a $\sim$10$^{2}$-10$^{3}\times$ reduction in energy accompanied by a $\sim$10$\times$ reduction in area compared to a digital fixed-point MLP at similar approximation error. These results establish RNPUs as scalable, hardware-native nonlinear computing primitives and identify analog KAN architectures as a realistic silicon-based pathway toward energy-, latency-, and footprint-efficient analog neural-network hardware, particularly for edge inference.
In-Materia Speech Recognition
Oct 14, 2024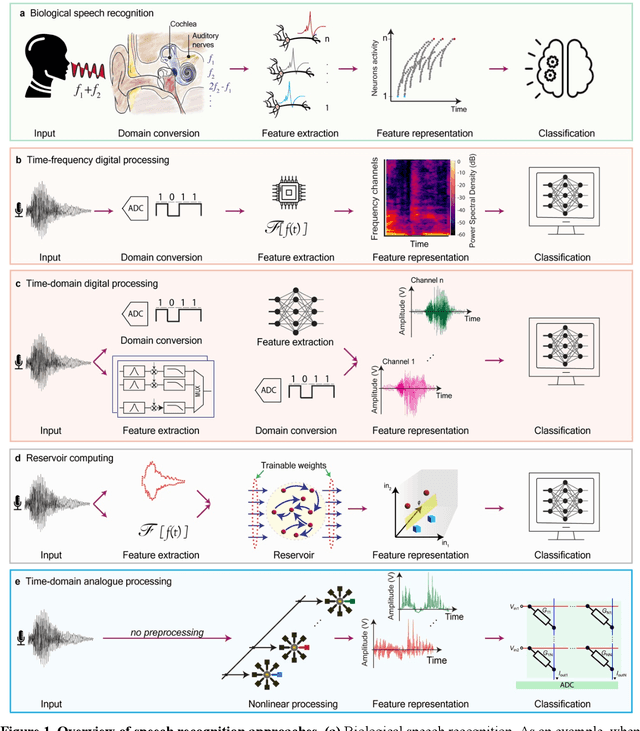
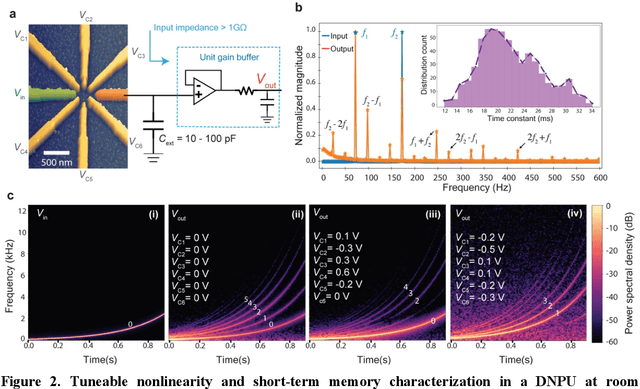
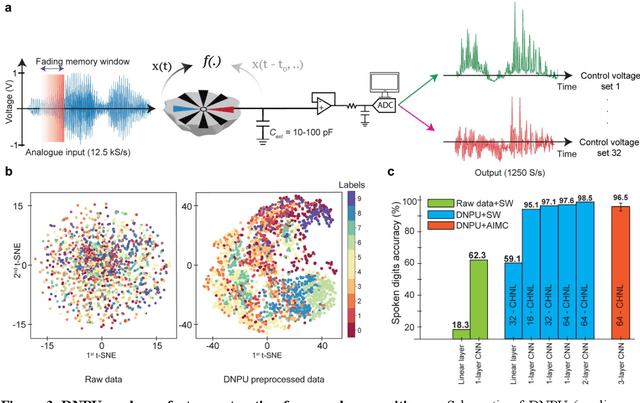
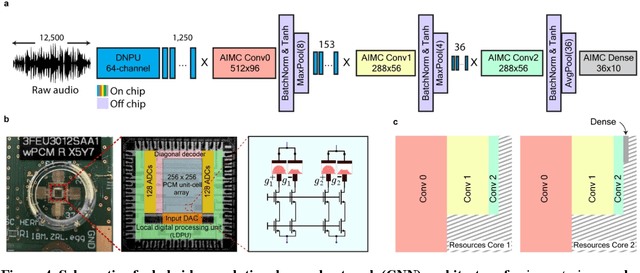
With the rise of decentralized computing, as in the Internet of Things, autonomous driving, and personalized healthcare, it is increasingly important to process time-dependent signals at the edge efficiently: right at the place where the temporal data are collected, avoiding time-consuming, insecure, and costly communication with a centralized computing facility (or cloud). However, modern-day processors often cannot meet the restrained power and time budgets of edge systems because of intrinsic limitations imposed by their architecture (von Neumann bottleneck) or domain conversions (analogue-to-digital and time-to-frequency). Here, we propose an edge temporal-signal processor based on two in-materia computing systems for both feature extraction and classification, reaching a software-level accuracy of 96.2% for the TI-46-Word speech-recognition task. First, a nonlinear, room-temperature dopant-network-processing-unit (DNPU) layer realizes analogue, time-domain feature extraction from the raw audio signals, similar to the human cochlea. Second, an analogue in-memory computing (AIMC) chip, consisting of memristive crossbar arrays, implements a compact neural network trained on the extracted features for classification. With the DNPU feature extraction consuming 100s nW and AIMC-based classification having the potential for less than 10 fJ per multiply-accumulate operation, our findings offer a promising avenue for advancing the compactness, efficiency, and performance of heterogeneous smart edge processors through in-materia computing hardware.