 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Analog Kolmogorov-Arnold Networks based on Reconfigurable Nonlinear-Processing Units
Feb 07, 2026Kolmogorov-Arnold Networks (KANs) shift neural computation from linear layers to learnable nonlinear edge functions, but implementing these nonlinearities efficiently in hardware remains an open challenge. Here we introduce a physical analog KAN architecture in which edge functions are realized in materia using reconfigurable nonlinear-processing units (RNPUs): multi-terminal nanoscale silicon devices whose input-output characteristics are tuned via control voltages. By combining multiple RNPUs into an edge processor and assembling these blocks into a reconfigurable analog KAN (aKAN) architecture with integrated mixed-signal interfacing, we establish a realistic system-level hardware implementation that enables compact KAN-style regression and classification with programmable nonlinear transformations. Using experimentally calibrated RNPU models and hardware measurements, we demonstrate accurate function approximation across increasing task complexity while requiring fewer or comparable trainable parameters than multilayer perceptrons (MLPs). System-level estimates indicate an energy per inference of $\sim$250 pJ and an end-to-end inference latency of $\sim$600 ns for a representative workload, corresponding to a $\sim$10$^{2}$-10$^{3}\times$ reduction in energy accompanied by a $\sim$10$\times$ reduction in area compared to a digital fixed-point MLP at similar approximation error. These results establish RNPUs as scalable, hardware-native nonlinear computing primitives and identify analog KAN architectures as a realistic silicon-based pathway toward energy-, latency-, and footprint-efficient analog neural-network hardware, particularly for edge inference.
In-Materia Speech Recognition
Oct 14, 2024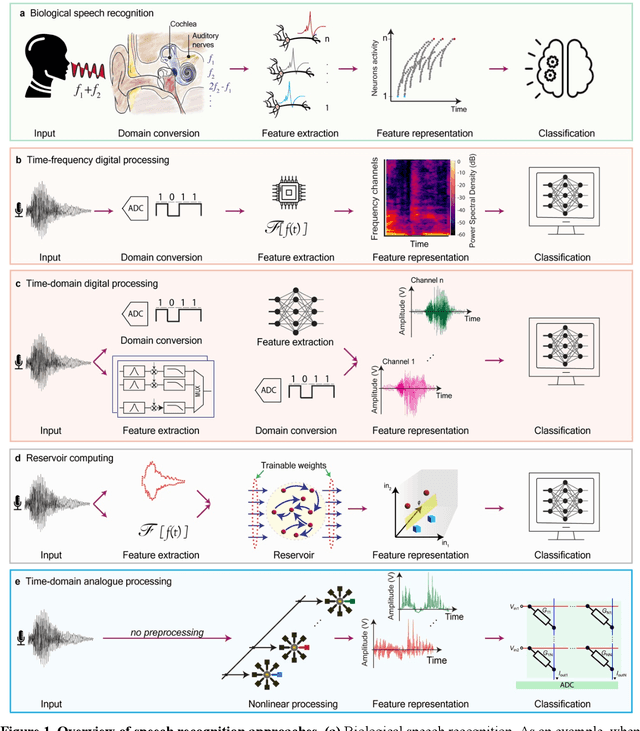
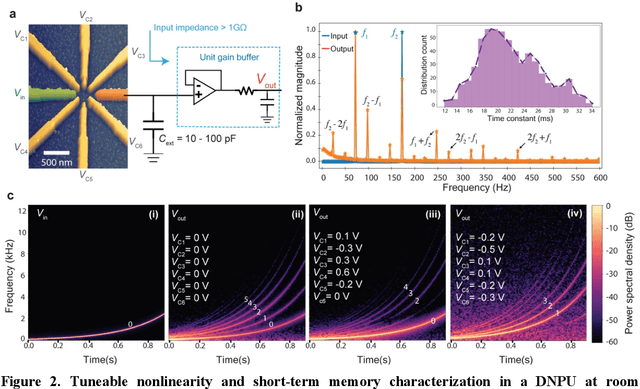
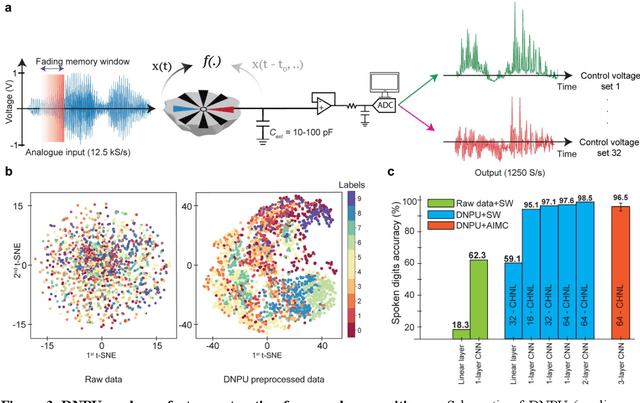
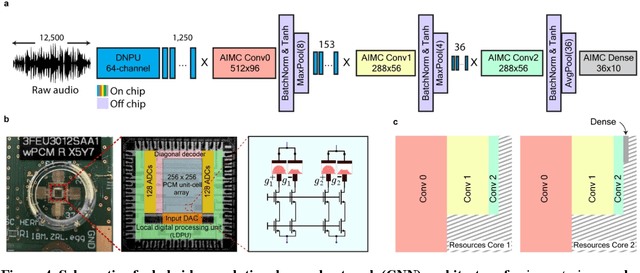
With the rise of decentralized computing, as in the Internet of Things, autonomous driving, and personalized healthcare, it is increasingly important to process time-dependent signals at the edge efficiently: right at the place where the temporal data are collected, avoiding time-consuming, insecure, and costly communication with a centralized computing facility (or cloud). However, modern-day processors often cannot meet the restrained power and time budgets of edge systems because of intrinsic limitations imposed by their architecture (von Neumann bottleneck) or domain conversions (analogue-to-digital and time-to-frequency). Here, we propose an edge temporal-signal processor based on two in-materia computing systems for both feature extraction and classification, reaching a software-level accuracy of 96.2% for the TI-46-Word speech-recognition task. First, a nonlinear, room-temperature dopant-network-processing-unit (DNPU) layer realizes analogue, time-domain feature extraction from the raw audio signals, similar to the human cochlea. Second, an analogue in-memory computing (AIMC) chip, consisting of memristive crossbar arrays, implements a compact neural network trained on the extracted features for classification. With the DNPU feature extraction consuming 100s nW and AIMC-based classification having the potential for less than 10 fJ per multiply-accumulate operation, our findings offer a promising avenue for advancing the compactness, efficiency, and performance of heterogeneous smart edge processors through in-materia computing hardware.
Critical nonlinear aspects of hopping transport for reconfigurable logic in disordered dopant networks
Dec 26, 2023Nonlinear behavior in the hopping transport of interacting charges enables reconfigurable logic in disordered dopant network devices, where voltages applied at control electrodes tune the relation between voltages applied at input electrodes and the current measured at an output electrode. From kinetic Monte Carlo simulations we analyze the critical nonlinear aspects of variable-range hopping transport for realizing Boolean logic gates in these devices on three levels. First, we quantify the occurrence of individual gates for random choices of control voltages. We find that linearly inseparable gates such as the XOR gate are less likely to occur than linearly separable gates such as the AND gate, despite the fact that the number of different regions in the multidimensional control voltage space for which AND or XOR gates occur is comparable. Second, we use principal component analysis to characterize the distribution of the output current vectors for the (00,10,01,11) logic input combinations in terms of eigenvectors and eigenvalues of the output covariance matrix. This allows a simple and direct comparison of the behavior of different simulated devices and a comparison to experimental devices. Third, we quantify the nonlinearity in the distribution of the output current vectors necessary for realizing Boolean functionality by introducing three nonlinearity indicators. The analysis provides a physical interpretation of the effects of changing the hopping distance and temperature and is used in a comparison with data generated by a deep neural network trained on a physical device.
A kinetic Monte Carlo Approach for Boolean Logic Functionality in Gold Nanoparticle Networks
Dec 07, 2023
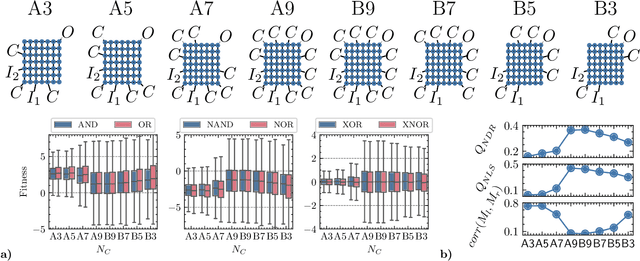
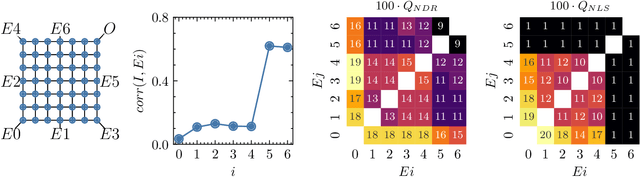
Nanoparticles interconnected by insulating organic molecules exhibit nonlinear switching behavior at low temperatures. By assembling these switches into a network and manipulating charge transport dynamics through surrounding electrodes, the network can be reconfigurably functionalized to act as any Boolean logic gate. This work introduces a kinetic Monte Carlo-based simulation tool, applying established principles of single electronics to model charge transport dynamics in nanoparticle networks. We functionalize nanoparticle networks as Boolean logic gates and assess their quality using a fitness function. Based on the definition of fitness, we derive new metrics to quantify essential nonlinear properties of the network, including negative differential resistance and nonlinear separability. These nonlinear properties are crucial not only for functionalizing the network as Boolean logic gates but also when our networks are functionalized for brain-inspired computing applications in the future. We address fundamental questions about the dependence of fitness and nonlinear properties on system size, number of surrounding electrodes, and electrode positioning. We assert the overall benefit of having more electrodes, with proximity to the network's output being pivotal for functionality and nonlinearity. Additionally, we demonstrate a optimal system size and argue for breaking symmetry in electrode positioning to favor nonlinear properties.
Gradient Descent in Materio
May 15, 2021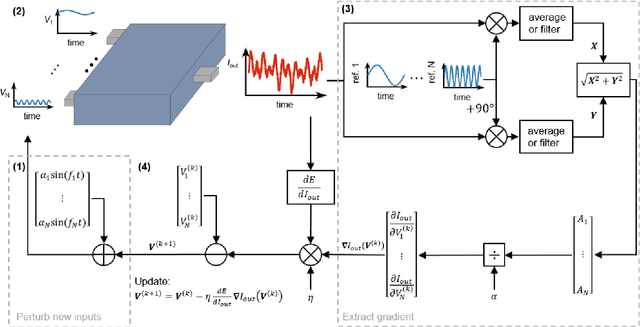
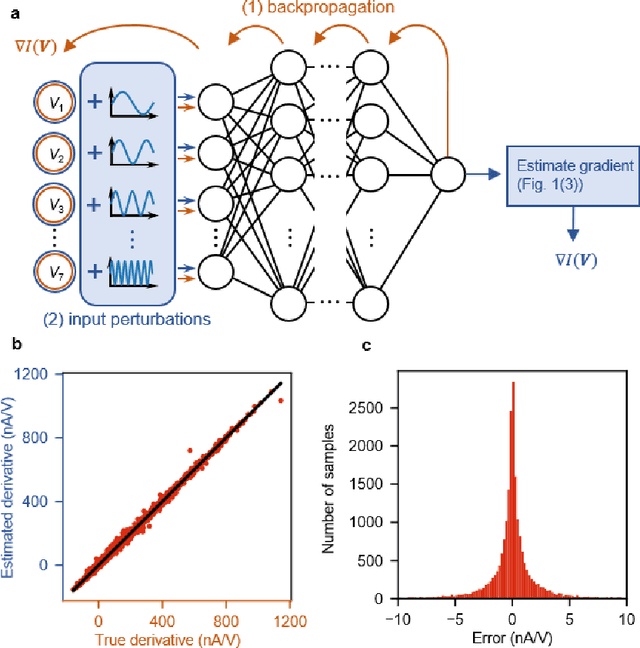
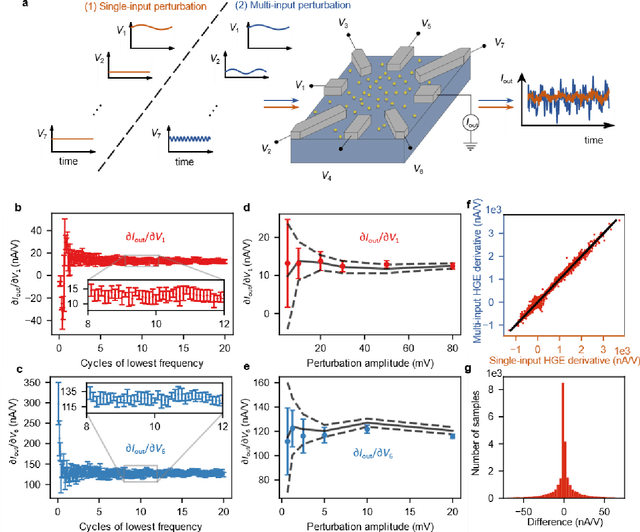
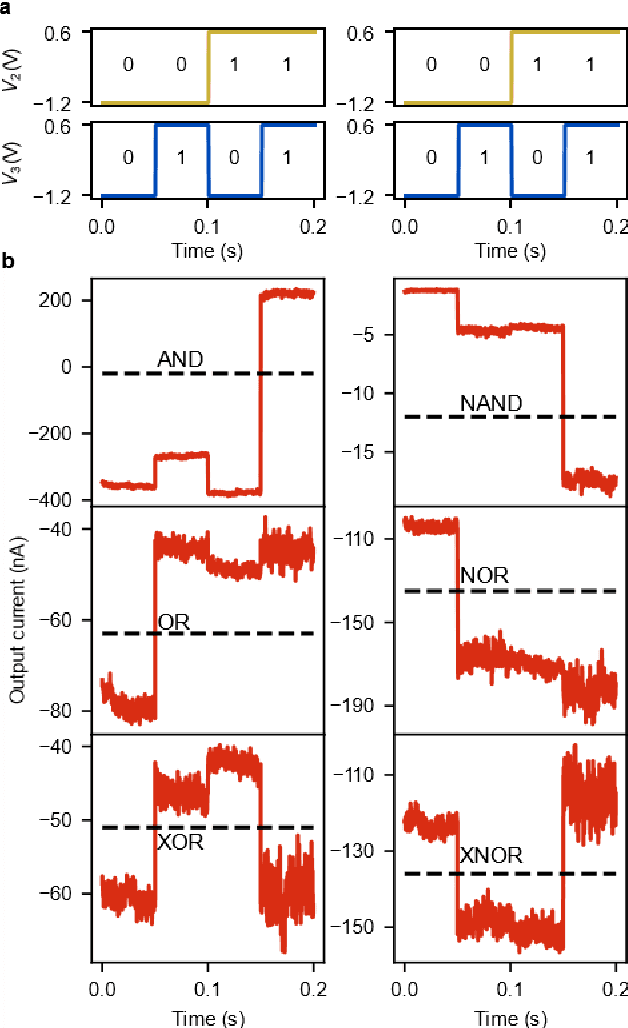
Deep learning, a multi-layered neural network approach inspired by the brain, has revolutionized machine learning. One of its key enablers has been backpropagation, an algorithm that computes the gradient of a loss function with respect to the weights in the neural network model, in combination with its use in gradient descent. However, the implementation of deep learning in digital computers is intrinsically wasteful, with energy consumption becoming prohibitively high for many applications. This has stimulated the development of specialized hardware, ranging from neuromorphic CMOS integrated circuits and integrated photonic tensor cores to unconventional, material-based computing systems. The learning process in these material systems, taking place, e.g., by artificial evolution or surrogate neural network modelling, is still a complicated and time-consuming process. Here, we demonstrate an efficient and accurate homodyne gradient extraction method for performing gradient descent on the loss function directly in the material system. We demonstrate the method in our recently developed dopant network processing units, where we readily realize all Boolean gates. This shows that gradient descent can in principle be fully implemented in materio using simple electronics, opening up the way to autonomously learning material systems.
Dopant Network Processing Units: Towards Efficient Neural-network Emulators with High-capacity Nanoelectronic Nodes
Jul 24, 2020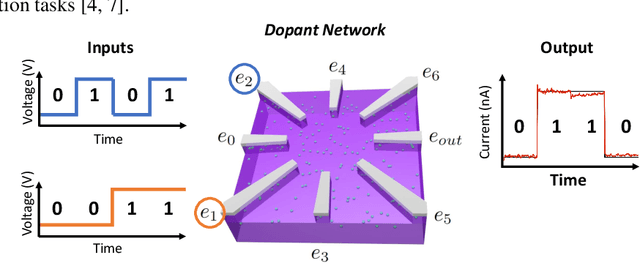
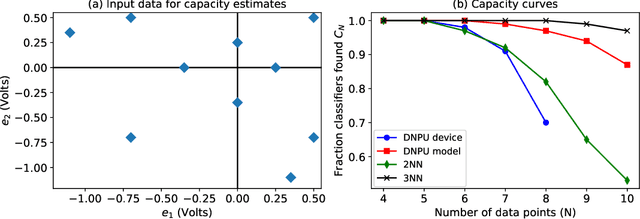
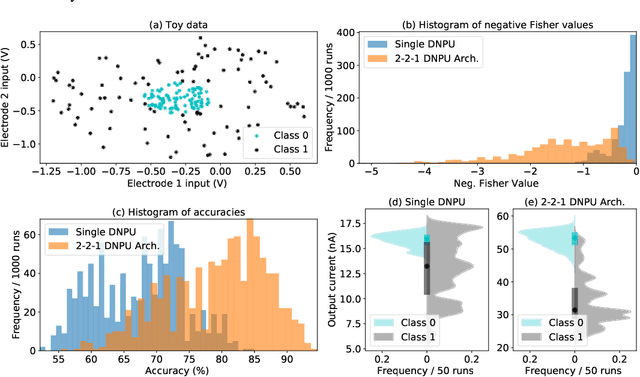
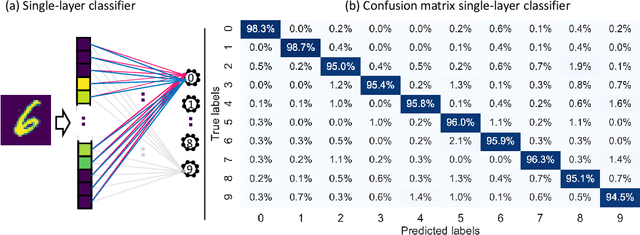
The rapidly growing computational demands of deep neural networks require novel hardware designs. Recently, tunable nanoelectronic devices were developed based on hopping electrons through a network of dopant atoms in silicon. These "Dopant Network Processing Units" (DNPUs) are highly energy-efficient and have potentially very high throughput. By adapting the control voltages applied to its terminals, a single DNPU can solve a variety of linearly non-separable classification problems. However, using a single device has limitations due to the implicit single-node architecture. This paper presents a promising novel approach to neural information processing by introducing DNPUs as high-capacity neurons and moving from a single to a multi-neuron framework. By implementing and testing a small multi-DNPU classifier in hardware, we show that feed-forward DNPU networks improve the performance of a single DNPU from 77% to 94% test accuracy on a binary classification task with concentric classes on a plane. Furthermore, motivated by the integration of DNPUs with memristor arrays, we study the potential of using DNPUs in combination with linear layers. We show by simulation that a single-layer MNIST classifier with only 10 DNPUs achieves over 96% test accuracy. Our results pave the road towards hardware neural-network emulators that offer atomic-scale information processing with low latency and energy consumption.