 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent in Materio
Paper and Code
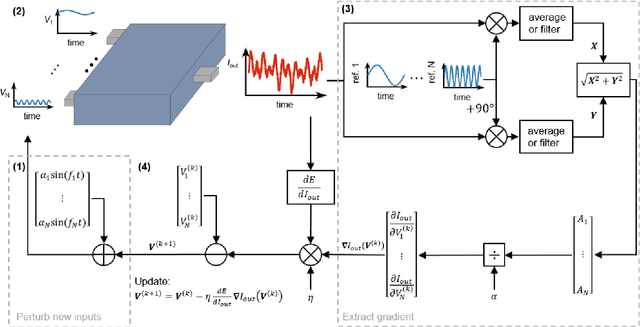
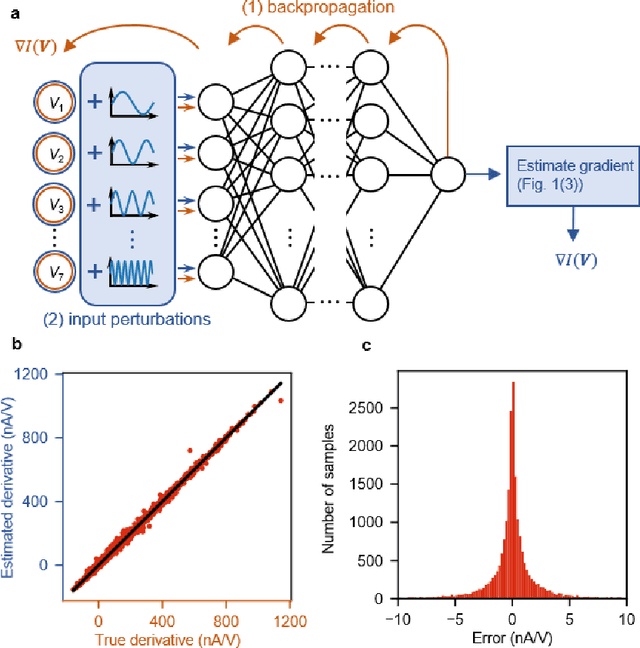
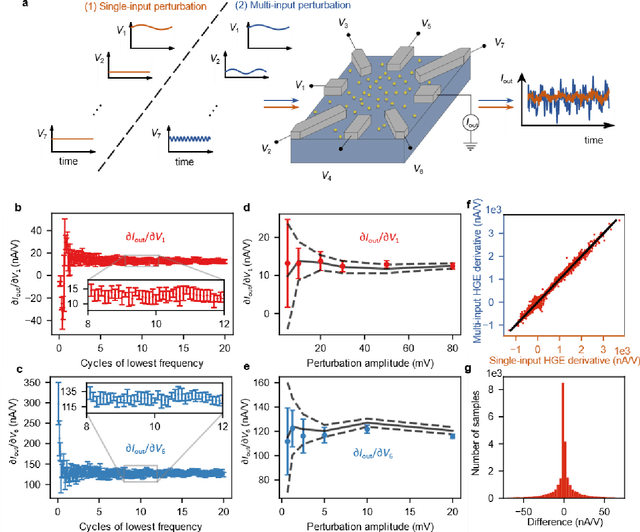
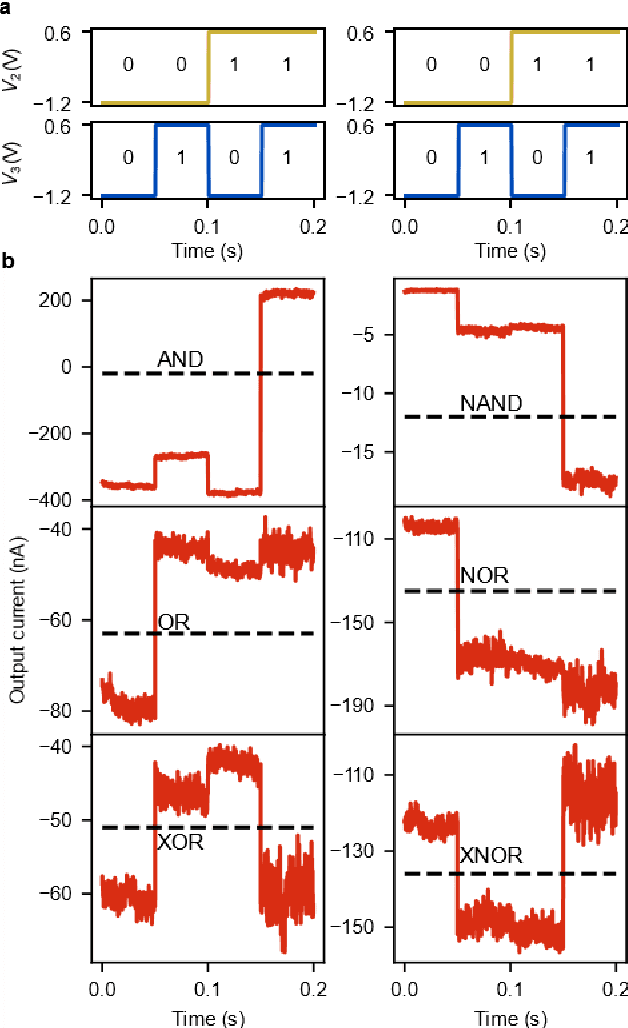
Deep learning, a multi-layered neural network approach inspired by the brain, has revolutionized machine learning. One of its key enablers has been backpropagation, an algorithm that computes the gradient of a loss function with respect to the weights in the neural network model, in combination with its use in gradient descent. However, the implementation of deep learning in digital computers is intrinsically wasteful, with energy consumption becoming prohibitively high for many applications. This has stimulated the development of specialized hardware, ranging from neuromorphic CMOS integrated circuits and integrated photonic tensor cores to unconventional, material-based computing systems. The learning process in these material systems, taking place, e.g., by artificial evolution or surrogate neural network modelling, is still a complicated and time-consuming process. Here, we demonstrate an efficient and accurate homodyne gradient extraction method for performing gradient descent on the loss function directly in the material system. We demonstrate the method in our recently developed dopant network processing units, where we readily realize all Boolean gates. This shows that gradient descent can in principle be fully implemented in materio using simple electronics, opening up the way to autonomously learning material systems.