 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDopant Network Processing Units: Towards Efficient Neural-network Emulators with High-capacity Nanoelectronic Nodes
Paper and Code
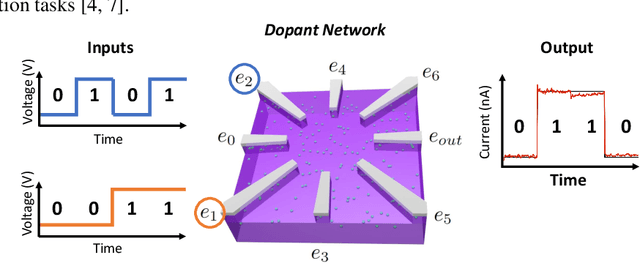
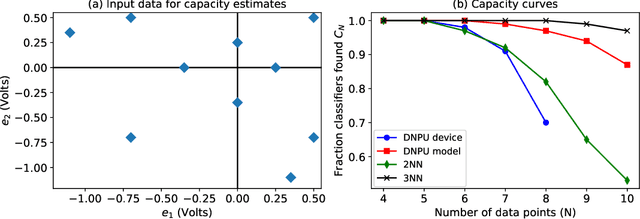
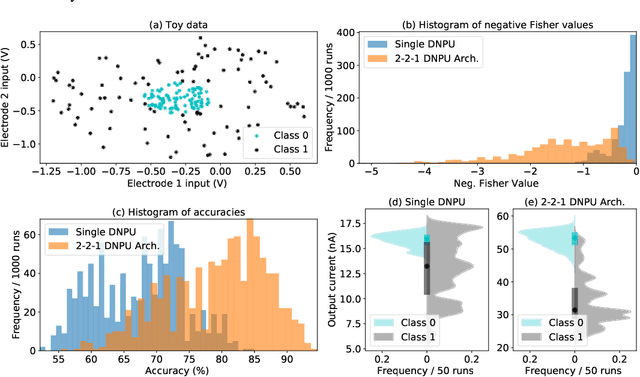
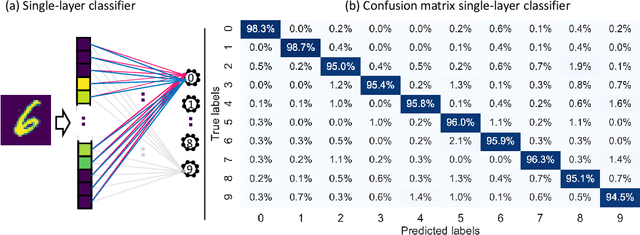
The rapidly growing computational demands of deep neural networks require novel hardware designs. Recently, tunable nanoelectronic devices were developed based on hopping electrons through a network of dopant atoms in silicon. These "Dopant Network Processing Units" (DNPUs) are highly energy-efficient and have potentially very high throughput. By adapting the control voltages applied to its terminals, a single DNPU can solve a variety of linearly non-separable classification problems. However, using a single device has limitations due to the implicit single-node architecture. This paper presents a promising novel approach to neural information processing by introducing DNPUs as high-capacity neurons and moving from a single to a multi-neuron framework. By implementing and testing a small multi-DNPU classifier in hardware, we show that feed-forward DNPU networks improve the performance of a single DNPU from 77% to 94% test accuracy on a binary classification task with concentric classes on a plane. Furthermore, motivated by the integration of DNPUs with memristor arrays, we study the potential of using DNPUs in combination with linear layers. We show by simulation that a single-layer MNIST classifier with only 10 DNPUs achieves over 96% test accuracy. Our results pave the road towards hardware neural-network emulators that offer atomic-scale information processing with low latency and energy consumption.