 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference
Paper and Code
May 16, 2020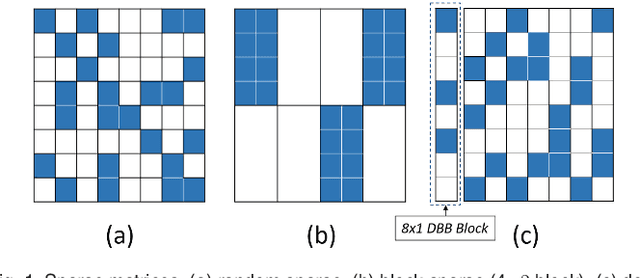
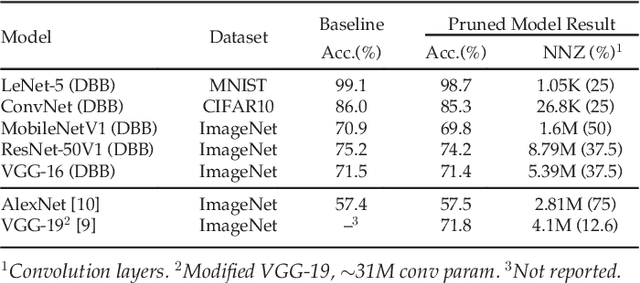
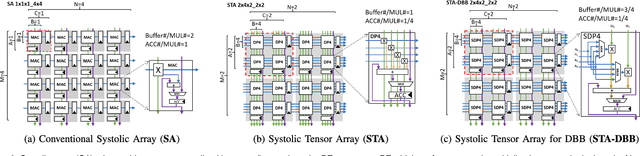

Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). The systolic array (SA) is a pipelined 2D array of processing elements (PEs), with very efficient local data movement, well suited to accelerating GEMM, and widely deployed in industry. In this work, we describe two significant improvements to the traditional SA architecture, to specifically optimize for CNN inference. Firstly, we generalize the traditional scalar PE, into a Tensor-PE, which gives rise to a family of new Systolic Tensor Array (STA) microarchitectures. The STA family increases intra-PE operand reuse and datapath efficiency, resulting in circuit area and power dissipation reduction of as much as 2.08x and 1.36x respectively, compared to the conventional SA at iso-throughput with INT8 operands. Secondly, we extend this design to support a novel block-sparse data format called density-bound block (DBB). This variant (STA-DBB) achieves a 3.14x and 1.97x improvement over the SA baseline at iso-throughput in area and power respectively, when processing specially-trained DBB-sparse models, while remaining fully backwards compatible with dense models.