 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021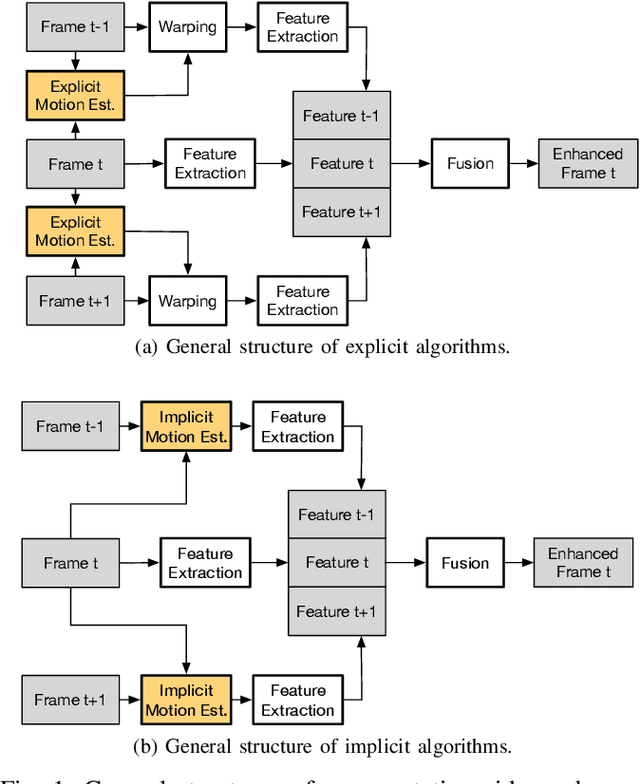

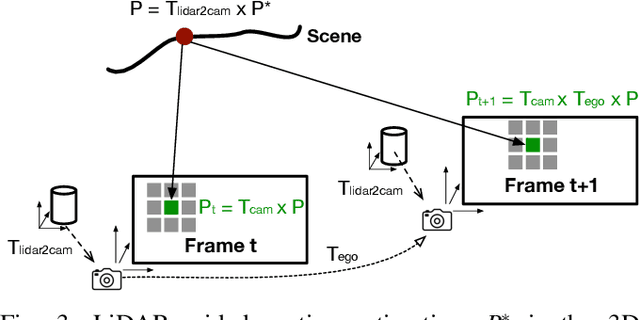

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 25, 2019

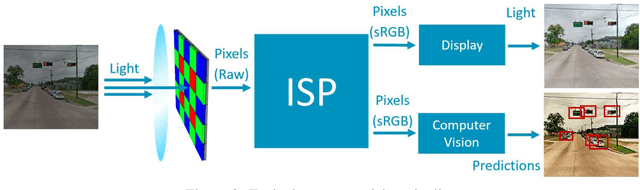
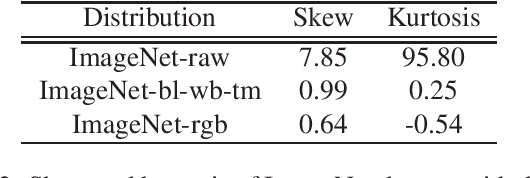
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning
Feb 27, 2019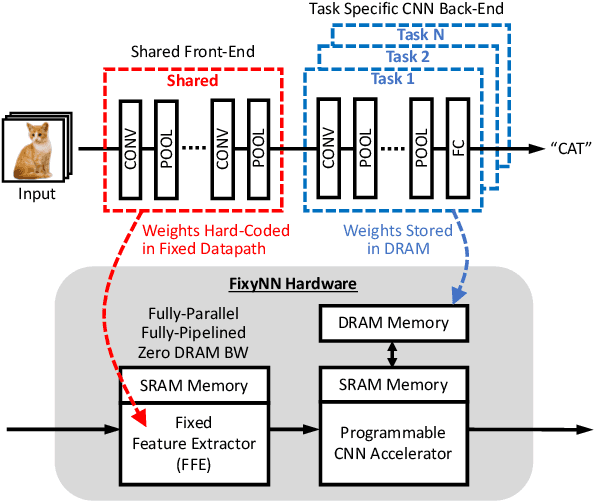
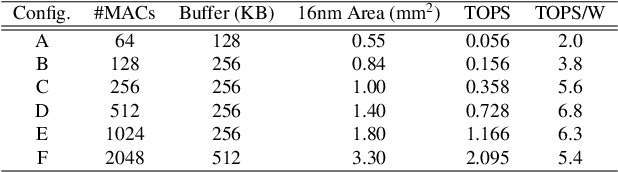
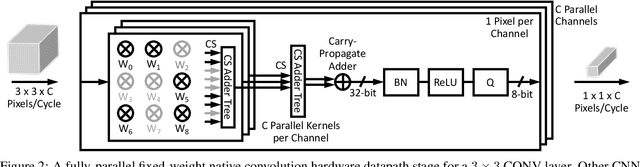
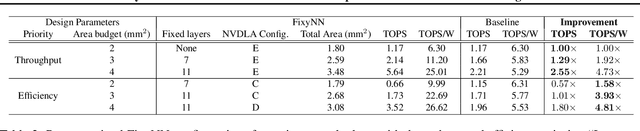
The computational demands of computer vision tasks based on state-of-the-art Convolutional Neural Network (CNN) image classification far exceed the energy budgets of mobile devices. This paper proposes FixyNN, which consists of a fixed-weight feature extractor that generates ubiquitous CNN features, and a conventional programmable CNN accelerator which processes a dataset-specific CNN. Image classification models for FixyNN are trained end-to-end via transfer learning, with the common feature extractor representing the transfered part, and the programmable part being learnt on the target dataset. Experimental results demonstrate FixyNN hardware can achieve very high energy efficiencies up to 26.6 TOPS/W ($4.81 \times$ better than iso-area programmable accelerator). Over a suite of six datasets we trained models via transfer learning with an accuracy loss of $<1\%$ resulting in up to 11.2 TOPS/W - nearly $2 \times$ more efficient than a conventional programmable CNN accelerator of the same area.
Energy Efficient Hardware for On-Device CNN Inference via Transfer Learning
Dec 04, 2018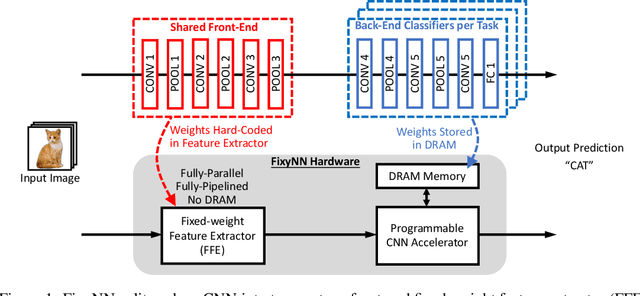

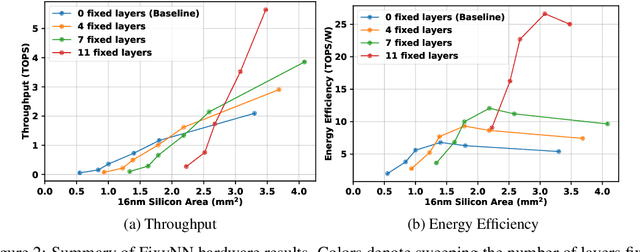
On-device CNN inference for real-time computer vision applications can result in computational demands that far exceed the energy budgets of mobile devices. This paper proposes FixyNN, a co-designed hardware accelerator platform which splits a CNN model into two parts: a set of layers that are fixed in the hardware platform as a front-end fixed-weight feature extractor, and the remaining layers which become a back-end classifier running on a conventional programmable CNN accelerator. The common front-end provides ubiquitous CNN features for all FixyNN models, while the back-end is programmable and specific to a given dataset. Image classification models for FixyNN are trained end-to-end via transfer learning, with front-end layers fixed for the shared feature extractor, and back-end layers fine-tuned for a specific task. Over a suite of six datasets, we trained models via transfer learning with an accuracy loss of <1%, resulting in a FixyNN hardware platform with nearly 2 times better energy efficiency than a conventional programmable CNN accelerator of the same silicon area (i.e. hardware cost).