 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Local Neural Regression for Low-Cost, Path Traced Lambertian Global Illumination
Oct 15, 2024Despite recent advances in hardware acceleration of ray tracing, real-time ray budgets remain stubbornly limited at a handful of samples per pixel (spp) on commodity hardware, placing the onus on denoising algorithms to achieve high visual quality for path traced global illumination. Neural network-based solutions give excellent result quality at the cost of increased execution time relative to hand-engineered methods, making them less suitable for deployment on resource-constrained systems. We therefore propose incorporating a neural network into a computationally-efficient local linear model-based denoiser, and demonstrate faithful single-frame reconstruction of global illumination for Lambertian scenes at very low sample counts (1spp) and for low computational cost. Other contributions include improving the quality and performance of local linear model-based denoising through a simplified mathematical treatment, and demonstration of the surprising usefulness of ambient occlusion as a guide channel. We also show how our technique is straightforwardly extensible to joint denoising and upsampling of path traced renders with reference to low-cost, rasterized guide channels.
Self-Compressing Neural Networks
Jan 31, 2023This work focuses on reducing neural network size, which is a major driver of neural network execution time, power consumption, bandwidth, and memory footprint. A key challenge is to reduce size in a manner that can be exploited readily for efficient training and inference without the need for specialized hardware. We propose Self-Compression: a simple, general method that simultaneously achieves two goals: (1) removing redundant weights, and (2) reducing the number of bits required to represent the remaining weights. This is achieved using a generalized loss function to minimize overall network size. In our experiments we demonstrate floating point accuracy with as few as 3% of the bits and 18% of the weights remaining in the network.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 25, 2019

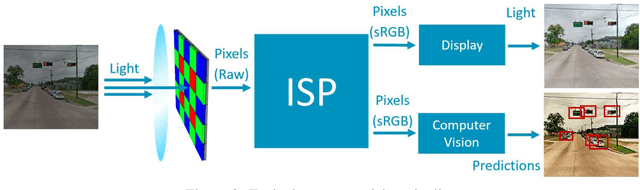
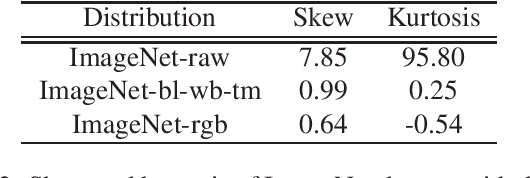
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.