 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPT-V: A Contrastive Approach to Post-Training Quantization of Vision Transformers
Paper and Code
Nov 17, 2022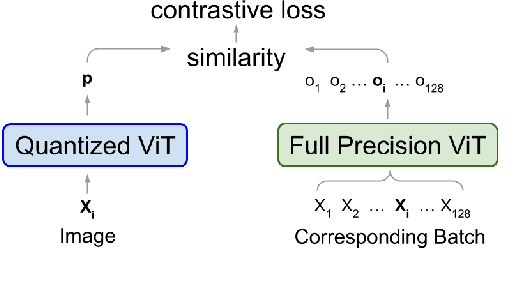
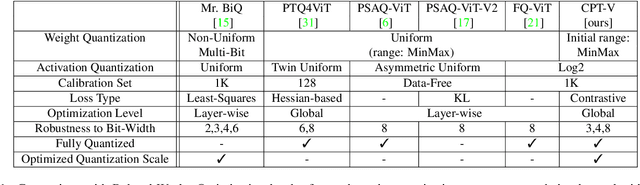
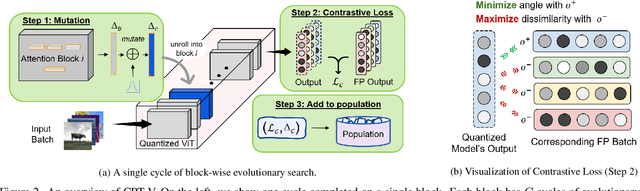
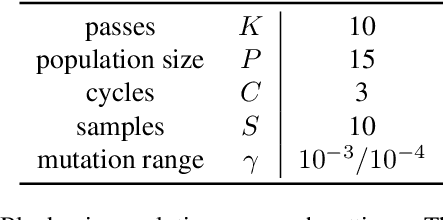
When considering post-training quantization, prior work has typically focused on developing a mixed precision scheme or learning the best way to partition a network for quantization. In our work, CPT-V, we look at a general way to improve the accuracy of networks that have already been quantized, simply by perturbing the quantization scales. Borrowing the idea of contrastive loss from self-supervised learning, we find a robust way to jointly minimize a loss function using just 1,000 calibration images. In order to determine the best performing quantization scale, CPT-V contrasts the features of quantized and full precision models in a self-supervised fashion. Unlike traditional reconstruction-based loss functions, the use of a contrastive loss function not only rewards similarity between the quantized and full precision outputs but also helps in distinguishing the quantized output from other outputs within a given batch. In addition, in contrast to prior works, CPT-V proposes a block-wise evolutionary search to minimize a global contrastive loss objective, allowing for accuracy improvement of existing vision transformer (ViT) quantization schemes. For example, CPT-V improves the top-1 accuracy of a fully quantized ViT-Base by 10.30%, 0.78%, and 0.15% for 3-bit, 4-bit, and 8-bit weight quantization levels. Extensive experiments on a variety of other ViT architectures further demonstrate its robustness in extreme quantization scenarios. Our code is available at <link>.