 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiskit Machine Learning: an open-source library for quantum machine learning tasks at scale on quantum hardware and classical simulators
May 23, 2025

We present Qiskit Machine Learning (ML), a high-level Python library that combines elements of quantum computing with traditional machine learning. The API abstracts Qiskit's primitives to facilitate interactions with classical simulators and quantum hardware. Qiskit ML started as a proof-of-concept code in 2019 and has since been developed to be a modular, intuitive tool for non-specialist users while allowing extensibility and fine-tuning controls for quantum computational scientists and developers. The library is available as a public, open-source tool and is distributed under the Apache version 2.0 license.
Mitigating exponential concentration in covariant quantum kernels for subspace and real-world data
Dec 10, 2024Fidelity quantum kernels have shown promise in classification tasks, particularly when a group structure in the data can be identified and exploited through a covariant feature map. In fact, there exist classification problems on which covariant kernels provide a provable advantage, thus establishing a separation between quantum and classical learners. However, their practical application poses two challenges: on one side, the group structure may be unknown and approximate in real-world data, and on the other side, scaling to the `utility' regime (above 100 qubits) is affected by exponential concentration. In this work, we address said challenges by applying fidelity kernels to real-world data with unknown structure, related to the scheduling of a fleet of electric vehicles, and to synthetic data generated from the union of subspaces, which is then close to many relevant real-world datasets. Furthermore, we propose a novel error mitigation strategy specifically tailored for fidelity kernels, called Bit Flip Tolerance (BFT), to alleviate the exponential concentration in our utility-scale experiments. Our multiclass classification reaches accuracies comparable to classical SVCs up to 156 qubits, thus constituting the largest experimental demonstration of quantum machine learning on IBM devices to date. For the real-world data experiments, the effect of the proposed BFT becomes manifest on 40+ qubits, where mitigated accuracies reach 80%, in line with classical, compared to 33% without BFT. Through the union-of-subspace synthetic dataset with 156 qubits, we demonstrate a mitigated accuracy of 80%, compared to 83% of classical models, and 37% of unmitigated quantum, using a test set of limited size.
Deep Learning to Scale up Time Series Traffic Prediction
Nov 29, 2019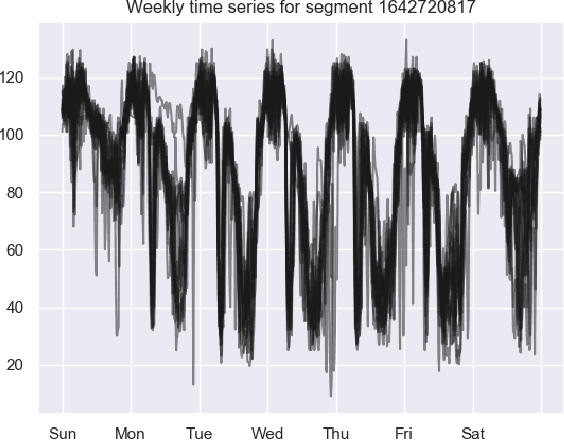
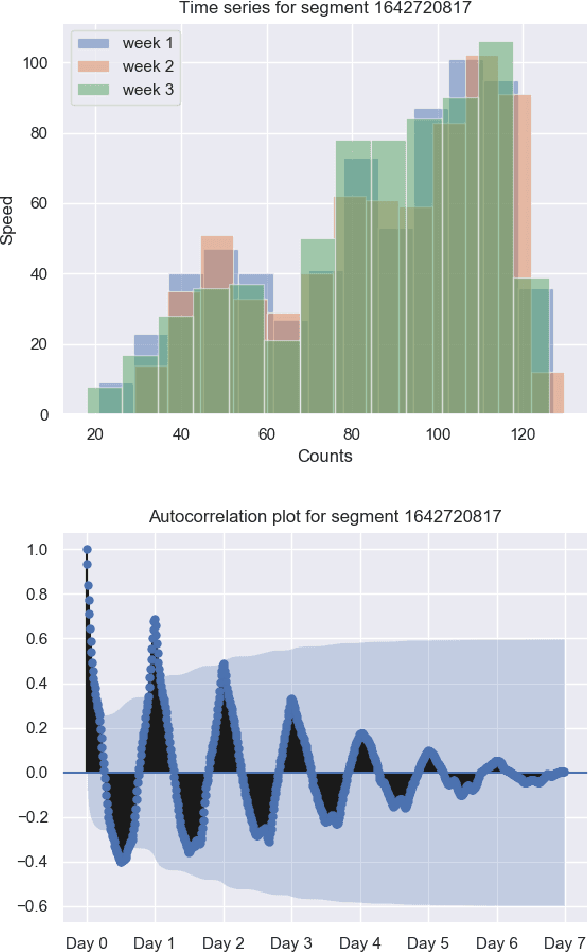
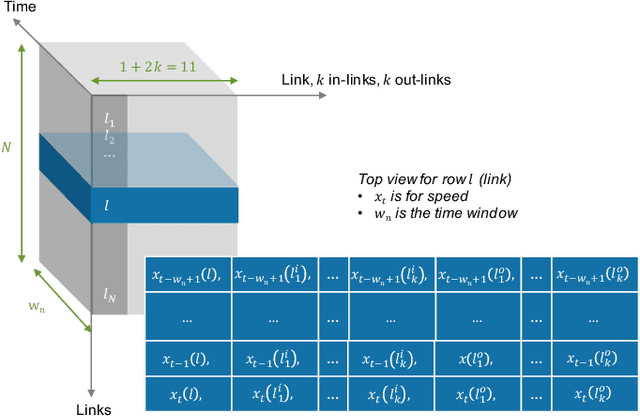
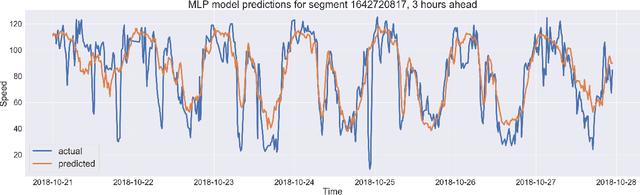
The transport literature is dense regarding short-term traffic predictions, up to the scale of 1 hour, yet less dense for long-term traffic predictions. The transport literature is also sparse when it comes to city-scale traffic predictions, mainly because of low data availability. The main question we try to answer in this work is to which extent the approaches used for short-term prediction at a link level can be scaled up for long-term prediction at a city scale. We investigate a city-scale traffic dataset with 14 weeks of speed observations collected every 15 minutes over 1098 segments in the hypercenter of Los Angeles, California. We look at a variety of machine learning and deep learning predictors for link-based predictions, and investigate ways to make such predictors scale up for larger areas, with brute force, clustering, and model design approaches. In particular we propose a novel deep learning spatio-temporal predictor inspired from recent works on recommender systems. We discuss the potential of including spatio-temporal features into the predictors, and conclude that modelling such features can be helpful for long-term predictions, while simpler predictors achieve very satisfactory performance for link-based and short-term forecasting. The trade-off is discussed not only in terms of prediction accuracy vs prediction horizon but also in terms of training time and model sizing.