 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating exponential concentration in covariant quantum kernels for subspace and real-world data
Dec 10, 2024Fidelity quantum kernels have shown promise in classification tasks, particularly when a group structure in the data can be identified and exploited through a covariant feature map. In fact, there exist classification problems on which covariant kernels provide a provable advantage, thus establishing a separation between quantum and classical learners. However, their practical application poses two challenges: on one side, the group structure may be unknown and approximate in real-world data, and on the other side, scaling to the `utility' regime (above 100 qubits) is affected by exponential concentration. In this work, we address said challenges by applying fidelity kernels to real-world data with unknown structure, related to the scheduling of a fleet of electric vehicles, and to synthetic data generated from the union of subspaces, which is then close to many relevant real-world datasets. Furthermore, we propose a novel error mitigation strategy specifically tailored for fidelity kernels, called Bit Flip Tolerance (BFT), to alleviate the exponential concentration in our utility-scale experiments. Our multiclass classification reaches accuracies comparable to classical SVCs up to 156 qubits, thus constituting the largest experimental demonstration of quantum machine learning on IBM devices to date. For the real-world data experiments, the effect of the proposed BFT becomes manifest on 40+ qubits, where mitigated accuracies reach 80%, in line with classical, compared to 33% without BFT. Through the union-of-subspace synthetic dataset with 156 qubits, we demonstrate a mitigated accuracy of 80%, compared to 83% of classical models, and 37% of unmitigated quantum, using a test set of limited size.
A Survey of Classical And Quantum Sequence Models
Dec 15, 2023Our primary objective is to conduct a brief survey of various classical and quantum neural net sequence models, which includes self-attention and recurrent neural networks, with a focus on recent quantum approaches proposed to work with near-term quantum devices, while exploring some basic enhancements for these quantum models. We re-implement a key representative set of these existing methods, adapting an image classification approach using quantum self-attention to create a quantum hybrid transformer that works for text and image classification, and applying quantum self-attention and quantum recurrent neural networks to natural language processing tasks. We also explore different encoding techniques and introduce positional encoding into quantum self-attention neural networks leading to improved accuracy and faster convergence in text and image classification experiments. This paper also performs a comparative analysis of classical self-attention models and their quantum counterparts, helping shed light on the differences in these models and their performance.
Study of Feature Importance for Quantum Machine Learning Models
Feb 25, 2022



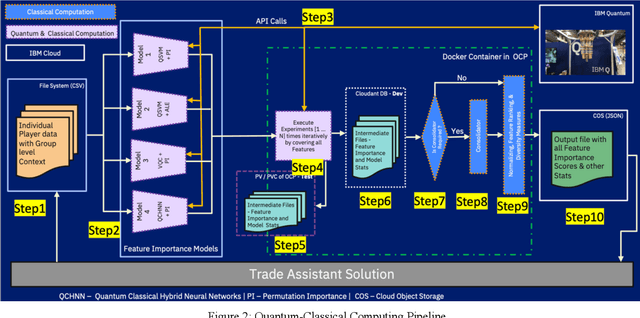
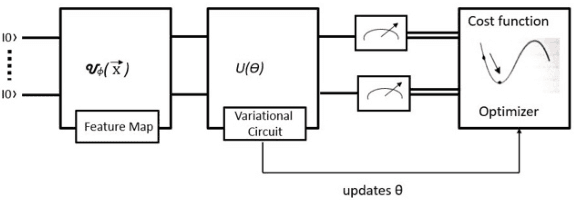
Predictor importance is a crucial part of data preprocessing pipelines in classical and quantum machine learning (QML). This work presents the first study of its kind in which feature importance for QML models has been explored and contrasted against their classical machine learning (CML) equivalents. We developed a hybrid quantum-classical architecture where QML models are trained and feature importance values are calculated from classical algorithms on a real-world dataset. This architecture has been implemented on ESPN Fantasy Football data using Qiskit statevector simulators and IBM quantum hardware such as the IBMQ Mumbai and IBMQ Montreal systems. Even though we are in the Noisy Intermediate-Scale Quantum (NISQ) era, the physical quantum computing results are promising. To facilitate current quantum scale, we created a data tiering, model aggregation, and novel validation methods. Notably, the feature importance magnitudes from the quantum models had a much higher variation when contrasted to classical models. We can show that equivalent QML and CML models are complementary through diversity measurements. The diversity between QML and CML demonstrates that both approaches can contribute to a solution in different ways. Within this paper we focus on Quantum Support Vector Classifiers (QSVC), Variational Quantum Circuit (VQC), and their classical counterparts. The ESPN and IBM fantasy football Trade Assistant combines advanced statistical analysis with the natural language processing of Watson Discovery to serve up personalized trade recommendations that are fair. Here, player valuation data of each player has been considered and this work can be extended to calculate the feature importance of other QML models such as Quantum Boltzmann machines.
Large Scale Diverse Combinatorial Optimization: ESPN Fantasy Football Player Trades
Nov 05, 2021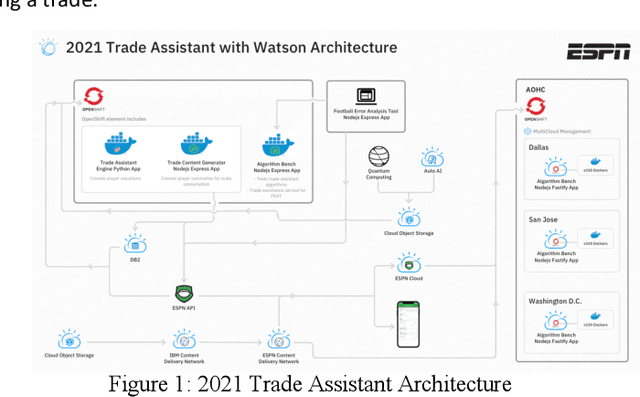

Even skilled fantasy football managers can be disappointed by their mid-season rosters as some players inevitably fall short of draft day expectations. Team managers can quickly discover that their team has a low score ceiling even if they start their best active players. A novel and diverse combinatorial optimization system proposes high volume and unique player trades between complementary teams to balance trade fairness. Several algorithms create the valuation of each fantasy football player with an ensemble of computing models: Quantum Support Vector Classifier with Permutation Importance (QSVC-PI), Quantum Support Vector Classifier with Accumulated Local Effects (QSVC-ALE), Variational Quantum Circuit with Permutation Importance (VQC-PI), Hybrid Quantum Neural Network with Permutation Importance (HQNN-PI), eXtreme Gradient Boosting Classifier (XGB), and Subject Matter Expert (SME) rules. The valuation of each player is personalized based on league rules, roster, and selections. The cost of trading away a player is related to a team's roster, such as the depth at a position, slot count, and position importance. Teams are paired together for trading based on a cosine dissimilarity score so that teams can offset their strengths and weaknesses. A knapsack 0-1 algorithm computes outgoing players for each team. Postprocessors apply analytics and deep learning models to measure 6 different objective measures about each trade. Over the 2020 and 2021 National Football League (NFL) seasons, a group of 24 experts from IBM and ESPN evaluated trade quality through 10 Football Error Analysis Tool (FEAT) sessions. Our system started with 76.9% of high-quality trades and was deployed for the 2021 season with 97.3% of high-quality trades. To increase trade quantity, our quantum, classical, and rules-based computing have 100% trade uniqueness. We use Qiskit's quantum simulators throughout our work.