 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch Chat: Real Time Generative AI and Generative Computing for Tennis
Sep 16, 2025We present Match Chat, a real-time, agent-driven assistant designed to enhance the tennis fan experience by delivering instant, accurate responses to match-related queries. Match Chat integrates Generative Artificial Intelligence (GenAI) with Generative Computing (GenComp) techniques to synthesize key insights during live tennis singles matches. The system debuted at the 2025 Wimbledon Championships and the 2025 US Open, where it provided about 1 million users with seamless access to streaming and static data through natural language queries. The architecture is grounded in an Agent-Oriented Architecture (AOA) combining rule engines, predictive models, and agents to pre-process and optimize user queries before passing them to GenAI components. The Match Chat system had an answer accuracy of 92.83% with an average response time of 6.25 seconds under loads of up to 120 requests per second (RPS). Over 96.08% of all queries were guided using interactive prompt design, contributing to a user experience that prioritized clarity, responsiveness, and minimal effort. The system was designed to mask architectural complexity, offering a frictionless and intuitive interface that required no onboarding or technical familiarity. Across both Grand Slam deployments, Match Chat maintained 100% uptime and supported nearly 1 million unique users, underscoring the scalability and reliability of the platform. This work introduces key design patterns for real-time, consumer-facing AI systems that emphasize speed, precision, and usability that highlights a practical path for deploying performant agentic systems in dynamic environments.
Automated Meta Prompt Engineering for Alignment with the Theory of Mind
May 13, 2025We introduce a method of meta-prompting that jointly produces fluent text for complex tasks while optimizing the similarity of neural states between a human's mental expectation and a Large Language Model's (LLM) neural processing. A technique of agentic reinforcement learning is applied, in which an LLM as a Judge (LLMaaJ) teaches another LLM, through in-context learning, how to produce content by interpreting the intended and unintended generated text traits. To measure human mental beliefs around content production, users modify long form AI-generated text articles before publication at the US Open 2024 tennis Grand Slam. Now, an LLMaaJ can solve the Theory of Mind (ToM) alignment problem by anticipating and including human edits within the creation of text from an LLM. Throughout experimentation and by interpreting the results of a live production system, the expectations of human content reviewers had 100% of alignment with AI 53.8% of the time with an average iteration count of 4.38. The geometric interpretation of content traits such as factualness, novelty, repetitiveness, and relevancy over a Hilbert vector space combines spatial volume (all trait importance) with vertices alignment (individual trait relevance) enabled the LLMaaJ to optimize on Human ToM. This resulted in an increase in content quality by extending the coverage of tennis action. Our work that was deployed at the US Open 2024 has been used across other live events within sports and entertainment.
Study of Feature Importance for Quantum Machine Learning Models
Feb 25, 2022



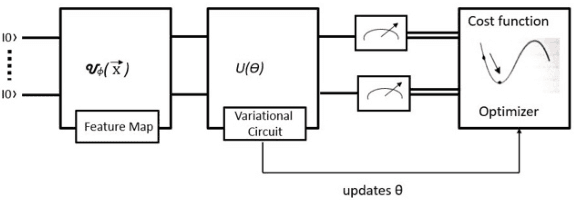
Predictor importance is a crucial part of data preprocessing pipelines in classical and quantum machine learning (QML). This work presents the first study of its kind in which feature importance for QML models has been explored and contrasted against their classical machine learning (CML) equivalents. We developed a hybrid quantum-classical architecture where QML models are trained and feature importance values are calculated from classical algorithms on a real-world dataset. This architecture has been implemented on ESPN Fantasy Football data using Qiskit statevector simulators and IBM quantum hardware such as the IBMQ Mumbai and IBMQ Montreal systems. Even though we are in the Noisy Intermediate-Scale Quantum (NISQ) era, the physical quantum computing results are promising. To facilitate current quantum scale, we created a data tiering, model aggregation, and novel validation methods. Notably, the feature importance magnitudes from the quantum models had a much higher variation when contrasted to classical models. We can show that equivalent QML and CML models are complementary through diversity measurements. The diversity between QML and CML demonstrates that both approaches can contribute to a solution in different ways. Within this paper we focus on Quantum Support Vector Classifiers (QSVC), Variational Quantum Circuit (VQC), and their classical counterparts. The ESPN and IBM fantasy football Trade Assistant combines advanced statistical analysis with the natural language processing of Watson Discovery to serve up personalized trade recommendations that are fair. Here, player valuation data of each player has been considered and this work can be extended to calculate the feature importance of other QML models such as Quantum Boltzmann machines.
Large Scale Diverse Combinatorial Optimization: ESPN Fantasy Football Player Trades
Nov 05, 2021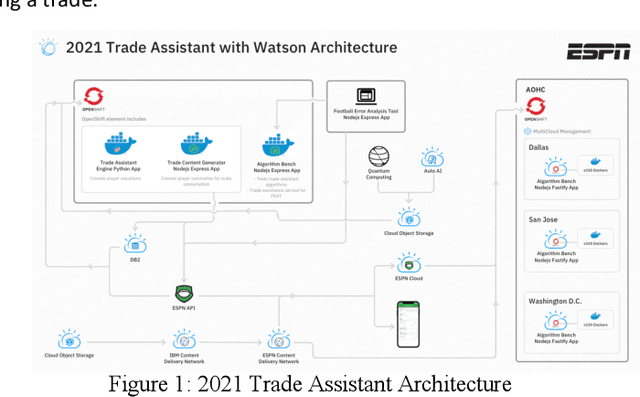

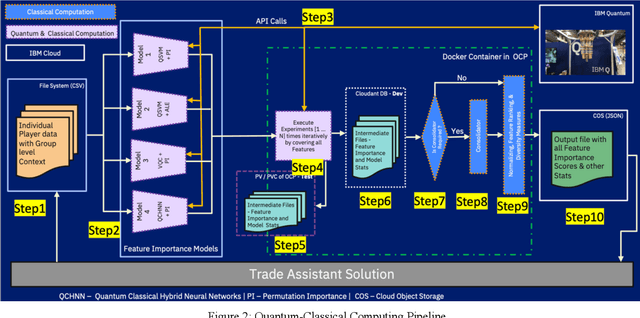
Even skilled fantasy football managers can be disappointed by their mid-season rosters as some players inevitably fall short of draft day expectations. Team managers can quickly discover that their team has a low score ceiling even if they start their best active players. A novel and diverse combinatorial optimization system proposes high volume and unique player trades between complementary teams to balance trade fairness. Several algorithms create the valuation of each fantasy football player with an ensemble of computing models: Quantum Support Vector Classifier with Permutation Importance (QSVC-PI), Quantum Support Vector Classifier with Accumulated Local Effects (QSVC-ALE), Variational Quantum Circuit with Permutation Importance (VQC-PI), Hybrid Quantum Neural Network with Permutation Importance (HQNN-PI), eXtreme Gradient Boosting Classifier (XGB), and Subject Matter Expert (SME) rules. The valuation of each player is personalized based on league rules, roster, and selections. The cost of trading away a player is related to a team's roster, such as the depth at a position, slot count, and position importance. Teams are paired together for trading based on a cosine dissimilarity score so that teams can offset their strengths and weaknesses. A knapsack 0-1 algorithm computes outgoing players for each team. Postprocessors apply analytics and deep learning models to measure 6 different objective measures about each trade. Over the 2020 and 2021 National Football League (NFL) seasons, a group of 24 experts from IBM and ESPN evaluated trade quality through 10 Football Error Analysis Tool (FEAT) sessions. Our system started with 76.9% of high-quality trades and was deployed for the 2021 season with 97.3% of high-quality trades. To increase trade quantity, our quantum, classical, and rules-based computing have 100% trade uniqueness. We use Qiskit's quantum simulators throughout our work.
Deep Artificial Intelligence for Fantasy Football Language Understanding
Nov 04, 2021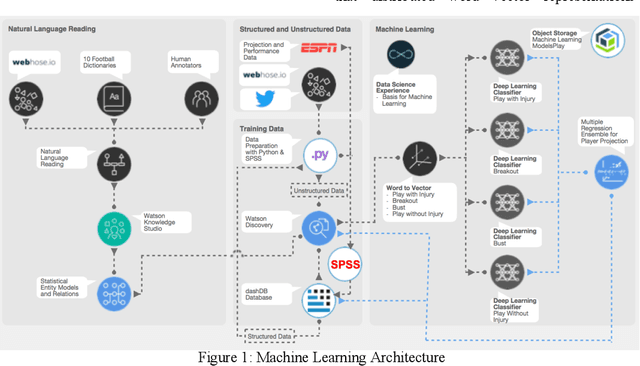
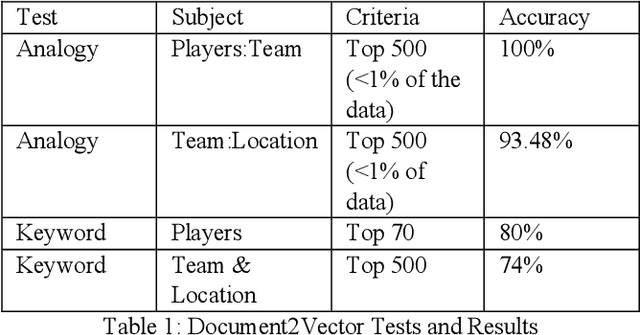
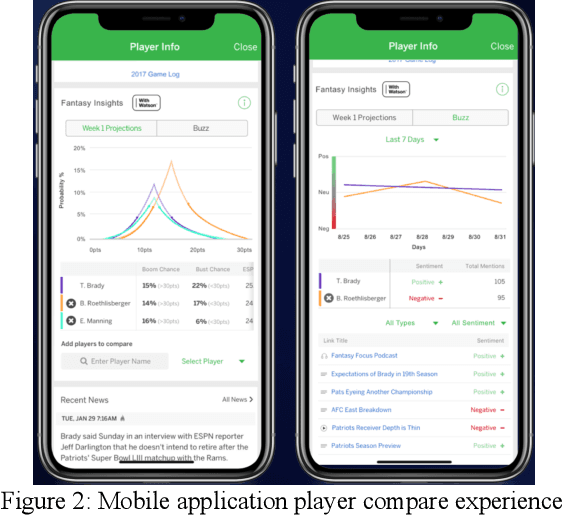
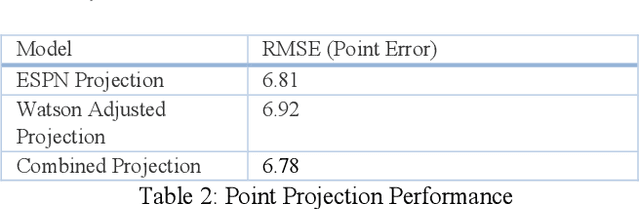
Fantasy sports allow fans to manage a team of their favorite athletes and compete with friends. The fantasy platform aligns the real-world statistical performance of athletes to fantasy scoring and has steadily risen in popularity to an estimated 9.1 million players per month with 4.4 billion player card views on the ESPN Fantasy Football platform from 2018-2019. In parallel, the sports media community produces news stories, blogs, forum posts, tweets, videos, podcasts and opinion pieces that are both within and outside the context of fantasy sports. However, human fantasy football players can only analyze an average of 3.9 sources of information. Our work discusses the results of a machine learning pipeline to manage an ESPN Fantasy Football team. The use of trained statistical entity detectors and document2vector models applied to over 100,000 news sources and 2.3 million articles, videos and podcasts each day enables the system to comprehend natural language with an analogy test accuracy of 100% and keyword test accuracy of 80%. Deep learning feedforward neural networks provide player classifications such as if a player will be a bust, boom, play with a hidden injury or play meaningful touches with a cumulative 72% accuracy. Finally, a multiple regression ensemble uses the deep learning output and ESPN projection data to provide a point projection for each of the top 500+ fantasy football players in 2018. The point projection maintained a RMSE of 6.78 points. The best fit probability density function from a set of 24 is selected to visualize score spreads. Within the first 6 weeks of the product launch, the total number of users spent a cumulative time of over 4.6 years viewing our AI insights. The training data for our models was provided by a 2015 to 2016 web archive from Webhose, ESPN statistics, and Rotowire injury reports. We used 2017 fantasy football data as a test set.