 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwarm Skills: A Portable, Self-Evolving Multi-Agent System Specification for Coordination Engineering
May 11, 2026As artificial intelligence engineering paradigms shift from single-agent Prompt and Context Engineering toward multi-agent \textbf{Coordination Engineering}, the ability to codify and systematically improve how multiple agents collaborate has emerged as a critical bottleneck. While single-agent skills can now be distributed as portable assets, multi-agent coordination protocols remain locked within framework-internal code or static configurations, preventing them from being shared across systems or autonomously improved over time. We propose \textbf{Swarm Skills}, a portable specification that extends the Anthropic Skills standard with multi-agent semantics. Swarm Skills turns multi-agent workflows into first-class, distributable assets that consist of roles, workflows, execution bounds, and a built-in semantic structure for self-evolution. To operationalize the specification's evolving nature, we present a companion self-evolution algorithm that automatically distills successful execution trajectories into new Swarm Skills and continuously patches existing ones based on multi-dimensional scoring (Effectiveness, Utilization, and Freshness), eliminating the need for human-in-the-loop oversight during the refinement process. Through an architectural compatibility analysis and a comprehensive qualitative case study using the open-source JiuwenSwarm reference implementation, we demonstrate how Swarm Skills achieves zero-adapter cross-agent portability via progressive disclosure, enabling agent teams to self-evolve their coordination strategies without framework lock-in.
Adaptive Dependency-aware Prompt Optimization Framework for Multi-Step LLM Pipeline
Dec 31, 2025Multi-step LLM pipelines invoke large language models multiple times in a structured sequence and can effectively solve complex tasks, but their performance heavily depends on the prompts used at each step. Jointly optimizing these prompts is difficult due to missing step-level supervision and inter-step dependencies. Existing end-to-end prompt optimization methods struggle under these conditions and often yield suboptimal or unstable updates. We propose ADOPT, an Adaptive Dependency-aware Prompt Optimization framework for multi-step LLM pipelines. ADOPT explicitly models the dependency between each LLM step and the final task outcome, enabling precise text-gradient estimation analogous to computing analytical derivatives. It decouples textual gradient estimation from gradient updates, reducing multi-prompt optimization to flexible single-prompt optimization steps, and employs a Shapley-based mechanism to adaptively allocate optimization resources. Experiments on real-world datasets and diverse pipeline structures show that ADOPT is effective and robust, consistently outperforming state-of-the-art prompt optimization baselines.
Pathformer: Recursive Path Query Encoding for Complex Logical Query Answering
Jun 21, 2024Complex Logical Query Answering (CLQA) over incomplete knowledge graphs is a challenging task. Recently, Query Embedding (QE) methods are proposed to solve CLQA by performing multi-hop logical reasoning. However, most of them only consider historical query context information while ignoring future information, which leads to their failure to capture the complex dependencies behind the elements of a query. In recent years, the transformer architecture has shown a strong ability to model long-range dependencies between words. The bidirectional attention mechanism proposed by the transformer can solve the limitation of these QE methods regarding query context. Still, as a sequence model, it is difficult for the transformer to model complex logical queries with branch structure computation graphs directly. To this end, we propose a neural one-point embedding method called Pathformer based on the tree-like computation graph, i.e., query computation tree. Specifically, Pathformer decomposes the query computation tree into path query sequences by branches and then uses the transformer encoder to recursively encode these path query sequences to obtain the final query embedding. This allows Pathformer to fully utilize future context information to explicitly model the complex interactions between various parts of the path query. Experimental results show that Pathformer outperforms existing competitive neural QE methods, and we found that Pathformer has the potential to be applied to non-one-point embedding space.
Rectified Meta-Learning from Noisy Labels for Robust Image-based Plant Disease Diagnosis
Mar 18, 2020
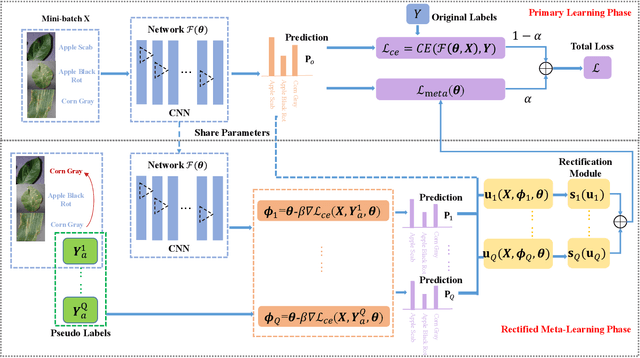


Plant diseases serve as one of main threats to food security and crop production. It is thus valuable to exploit recent advances of artificial intelligence to assist plant disease diagnosis. One popular approach is to transform this problem as a leaf image classification task, which can be then addressed by the powerful convolutional neural networks (CNNs). However, the performance of CNN-based classification approach depends on a large amount of high-quality manually labeled training data, which are inevitably introduced noise on labels in practice, leading to model overfitting and performance degradation. To overcome this problem, we propose a novel framework that incorporates rectified meta-learning module into common CNN paradigm to train a noise-robust deep network without using extra supervision information. The proposed method enjoys the following merits: i) A rectified meta-learning is designed to pay more attention to unbiased samples, leading to accelerated convergence and improved classification accuracy. ii) Our method is free on assumption of label noise distribution, which works well on various kinds of noise. iii) Our method serves as a plug-and-play module, which can be embedded into any deep models optimized by gradient descent based method. Extensive experiments are conducted to demonstrate the superior performance of our algorithm over the state-of-the-arts.