 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Distraction Undermines Moral Reasoning in Vision-Language Models
Mar 17, 2026Moral reasoning is fundamental to safe Artificial Intelligence (AI), yet ensuring its consistency across modalities becomes critical as AI systems evolve from text-based assistants to embodied agents. Current safety techniques demonstrate success in textual contexts, but concerns remain about generalization to visual inputs. Existing moral evaluation benchmarks rely on textonly formats and lack systematic control over variables that influence moral decision-making. Here we show that visual inputs fundamentally alter moral decision-making in state-of-the-art (SOTA) Vision-Language Models (VLMs), bypassing text-based safety mechanisms. We introduce Moral Dilemma Simulation (MDS), a multimodal benchmark grounded in Moral Foundation Theory (MFT) that enables mechanistic analysis through orthogonal manipulation of visual and contextual variables. The evaluation reveals that the vision modality activates intuition-like pathways that override the more deliberate and safer reasoning patterns observed in text-only contexts. These findings expose critical fragilities where language-tuned safety filters fail to constrain visual processing, demonstrating the urgent need for multimodal safety alignment.
The NeurIPS 2022 Neural MMO Challenge: A Massively Multiagent Competition with Specialization and Trade
Nov 07, 2023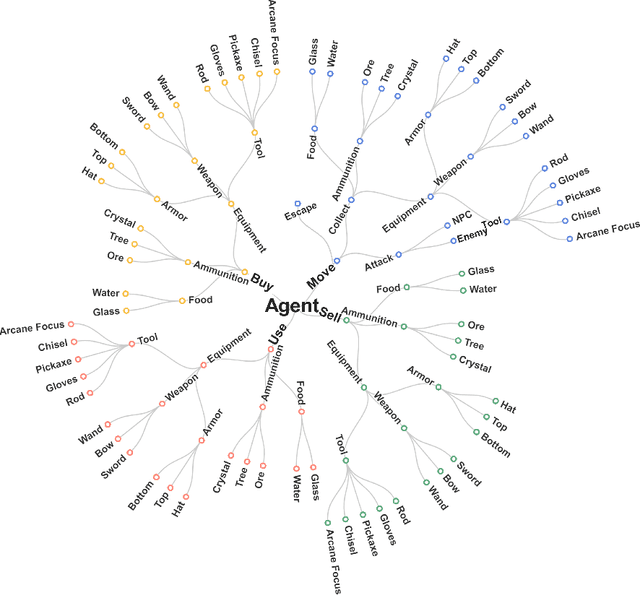



In this paper, we present the results of the NeurIPS-2022 Neural MMO Challenge, which attracted 500 participants and received over 1,600 submissions. Like the previous IJCAI-2022 Neural MMO Challenge, it involved agents from 16 populations surviving in procedurally generated worlds by collecting resources and defeating opponents. This year's competition runs on the latest v1.6 Neural MMO, which introduces new equipment, combat, trading, and a better scoring system. These elements combine to pose additional robustness and generalization challenges not present in previous competitions. This paper summarizes the design and results of the challenge, explores the potential of this environment as a benchmark for learning methods, and presents some practical reinforcement learning training approaches for complex tasks with sparse rewards. Additionally, we have open-sourced our baselines, including environment wrappers, benchmarks, and visualization tools for future research.
Reconfigurable Intelligent Surface & Edge -- An Introduction of an EM manipulation structure on obstacles' edge
Nov 03, 2023



Reconfigurable Intelligent Surface (RIS) or metasurface is one of the important enabling technologies in mobile cellular networks that can effectively enhance the signal coverage performance in obstructed regions, and it is generally deployed on surfaces different from obstacles to redirect electromagnetic (EM) waves by reflection, or covered on objects' surfaces to manipulate EM waves by refraction. In this paper, Reconfigurable Intelligent Surface & Edge (RISE) is proposed to extend RIS' abilities of reflection and refraction over surfaces to diffraction around obstacles' edge for better adaptation to specific coverage scenarios. Based on that, this paper analyzes the performance of several different deployment locations and EM manipulation structure designs for different coverage scenarios. Then a novel EM manipulation structure deployed at the obstacles' edge is proposed to achieve static EM environment modification. Simulations validate the preference of the schemes for different scenarios and the new structure achieves better coverage performance than other typical structures in the static scheme.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022



As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022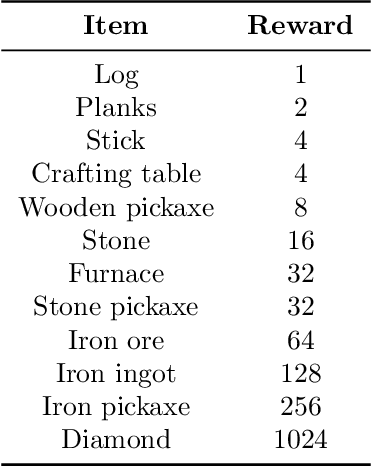
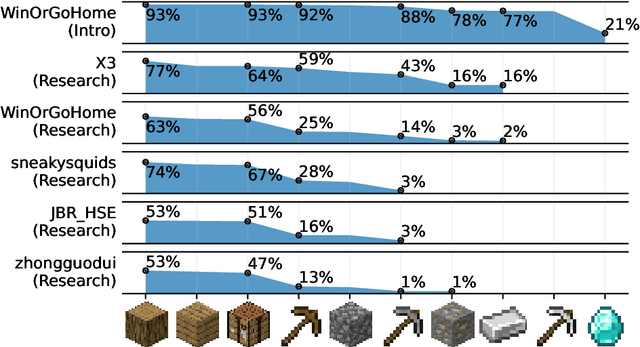
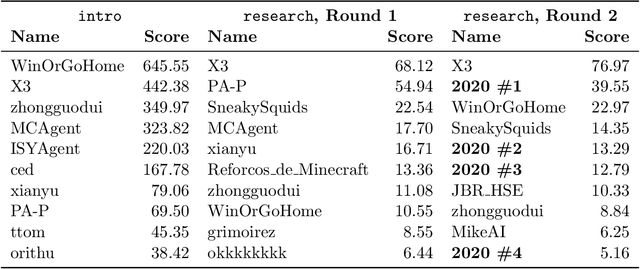
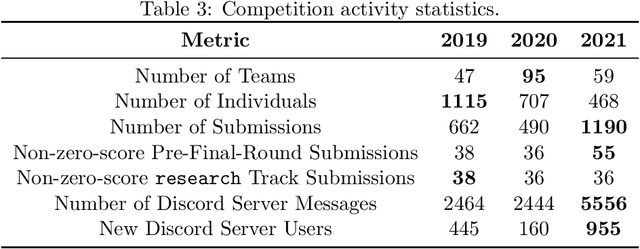
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Generative Adversarial Exploration for Reinforcement Learning
Jan 27, 2022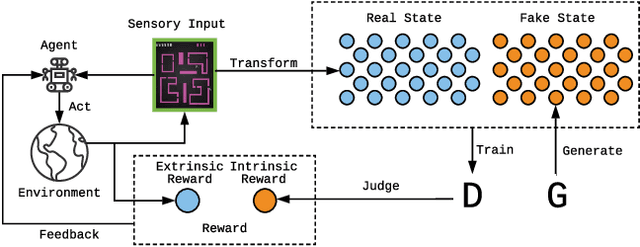
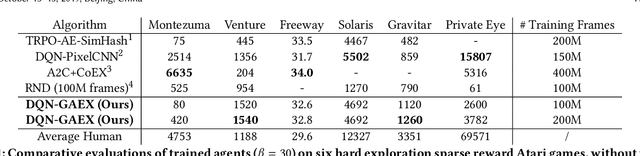
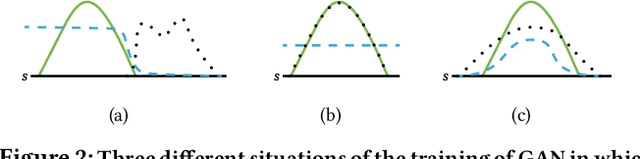
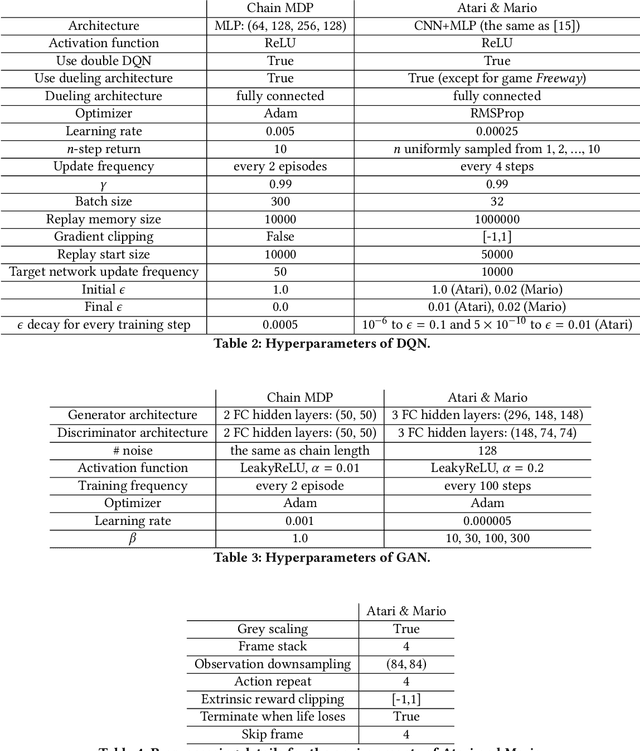
Exploration is crucial for training the optimal reinforcement learning (RL) policy, where the key is to discriminate whether a state visiting is novel. Most previous work focuses on designing heuristic rules or distance metrics to check whether a state is novel without considering such a discrimination process that can be learned. In this paper, we propose a novel method called generative adversarial exploration (GAEX) to encourage exploration in RL via introducing an intrinsic reward output from a generative adversarial network, where the generator provides fake samples of states that help discriminator identify those less frequently visited states. Thus the agent is encouraged to visit those states which the discriminator is less confident to judge as visited. GAEX is easy to implement and of high training efficiency. In our experiments, we apply GAEX into DQN and the DQN-GAEX algorithm achieves convincing performance on challenging exploration problems, including the game Venture, Montezuma's Revenge and Super Mario Bros, without further fine-tuning on complicate learning algorithms. To our knowledge, this is the first work to employ GAN in RL exploration problems.
DropNAS: Grouped Operation Dropout for Differentiable Architecture Search
Jan 27, 2022Neural architecture search (NAS) has shown encouraging results in automating the architecture design. Recently, DARTS relaxes the search process with a differentiable formulation that leverages weight-sharing and SGD where all candidate operations are trained simultaneously. Our empirical results show that such procedure results in the co-adaption problem and Matthew Effect: operations with fewer parameters would be trained maturely earlier. This causes two problems: firstly, the operations with more parameters may never have the chance to express the desired function since those with less have already done the job; secondly, the system will punish those underperforming operations by lowering their architecture parameter, and they will get smaller loss gradients, which causes the Matthew Effect. In this paper, we systematically study these problems and propose a novel grouped operation dropout algorithm named DropNAS to fix the problems with DARTS. Extensive experiments demonstrate that DropNAS solves the above issues and achieves promising performance. Specifically, DropNAS achieves 2.26% test error on CIFAR-10, 16.39% on CIFAR-100 and 23.4% on ImageNet (with the same training hyperparameters as DARTS for a fair comparison). It is also observed that DropNAS is robust across variants of the DARTS search space. Code is available at https://github.com/wiljohnhong/DropNAS.