 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Optimal Filter for Linear Gaussian Time-invariant Systems
Mar 09, 2021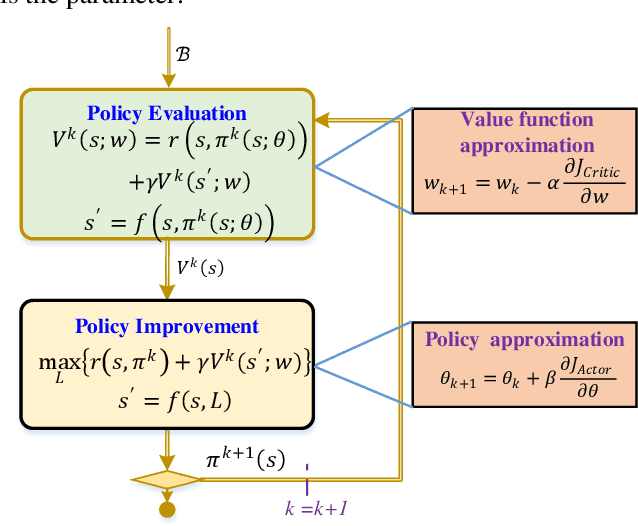
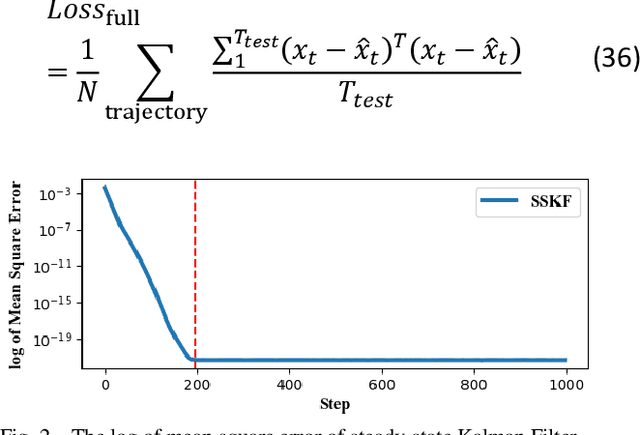

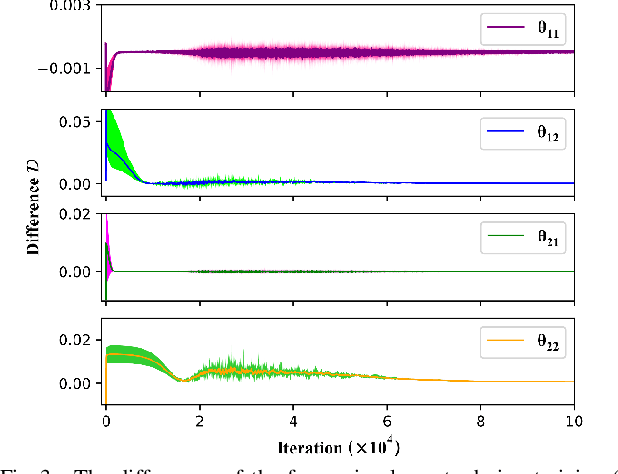
State estimation is critical to control systems, especially when the states cannot be directly measured. This paper presents an approximate optimal filter, which enables to use policy iteration technique to obtain the steady-state gain in linear Gaussian time-invariant systems. This design transforms the optimal filtering problem with minimum mean square error into an optimal control problem, called Approximate Optimal Filtering (AOF) problem. The equivalence holds given certain conditions about initial state distributions and policy formats, in which the system state is the estimation error, control input is the filter gain, and control objective function is the accumulated estimation error. We present a policy iteration algorithm to solve the AOF problem in steady-state. A classic vehicle state estimation problem finally evaluates the approximate filter. The results show that the policy converges to the steady-state Kalman gain, and its accuracy is within 2 %.