 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Dec 31, 2023

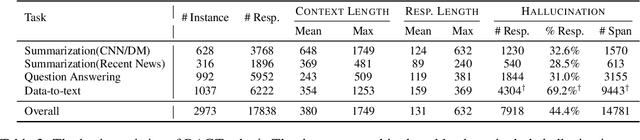

Retrieval-augmented generation (RAG) has become a main technique for alleviating hallucinations in large language models (LLMs). Despite the integration of RAG, LLMs may still present unsupported or contradictory claims to the retrieved contents. In order to develop effective hallucination prevention strategies under RAG, it is important to create benchmark datasets that can measure the extent of hallucination. This paper presents RAGTruth, a corpus tailored for analyzing word-level hallucinations in various domains and tasks within the standard RAG frameworks for LLM applications. RAGTruth comprises nearly 18,000 naturally generated responses from diverse LLMs using RAG. These responses have undergone meticulous manual annotations at both the individual cases and word levels, incorporating evaluations of hallucination intensity. We not only benchmark hallucination frequencies across different LLMs, but also critically assess the effectiveness of several existing hallucination detection methodologies. Furthermore, we show that using a high-quality dataset such as RAGTruth, it is possible to finetune a relatively small LLM and achieve a competitive level of performance in hallucination detection when compared to the existing prompt-based approaches using state-of-the-art large language models such as GPT-4.
Plum: Prompt Learning using Metaheuristic
Nov 14, 2023



Since the emergence of large language models, prompt learning has become a popular method for optimizing and customizing these models. Special prompts, such as Chain-of-Thought, have even revealed previously unknown reasoning capabilities within these models. However, the progress of discovering effective prompts has been slow, driving a desire for general prompt optimization methods. Unfortunately, few existing prompt learning methods satisfy the criteria of being truly "general", i.e., automatic, discrete, black-box, gradient-free, and interpretable all at once. In this paper, we introduce metaheuristics, a branch of discrete non-convex optimization methods with over 100 options, as a promising approach to prompt learning. Within our paradigm, we test six typical methods: hill climbing, simulated annealing, genetic algorithms with/without crossover, tabu search, and harmony search, demonstrating their effectiveness in black-box prompt learning and Chain-of-Thought prompt tuning. Furthermore, we show that these methods can be used to discover more human-understandable prompts that were previously unknown, opening the door to a cornucopia of possibilities in prompt optimization. We release all the codes in \url{https://github.com/research4pan/Plum}.
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Apr 13, 2023



Generative foundation models are susceptible to implicit biases that can arise from extensive unsupervised training data. Such biases can produce suboptimal samples, skewed outcomes, and unfairness, with potentially significant repercussions. Consequently, aligning these models with human ethics and preferences is an essential step toward ensuring their responsible and effective deployment in real-world applications. Prior research has primarily employed Reinforcement Learning from Human Feedback (RLHF) as a means of addressing this problem, wherein generative models are fine-tuned using RL algorithms guided by a human-feedback-informed reward model. However, the inefficiencies and instabilities associated with RL algorithms frequently present substantial obstacles to the successful alignment of generative models, necessitating the development of a more robust and streamlined approach. To this end, we introduce a new framework, Reward rAnked FineTuning (RAFT), designed to align generative models more effectively. Utilizing a reward model and a sufficient number of samples, our approach selects the high-quality samples, discarding those that exhibit undesired behavior, and subsequently assembles a streaming dataset. This dataset serves as the basis for aligning the generative model and can be employed under both offline and online settings. Notably, the sample generation process within RAFT is gradient-free, rendering it compatible with black-box generators. Through extensive experiments, we demonstrate that our proposed algorithm exhibits strong performance in the context of both large language models and diffusion models.