 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAMBA: A Bimodal Adversarial Multi-Round Black-Box Jailbreak Attacker for LVLMs
Dec 08, 2024



LVLMs are widely used but vulnerable to illegal or unethical responses under jailbreak attacks. To ensure their responsible deployment in real-world applications, it is essential to understand their vulnerabilities. There are four main issues in current work: single-round attack limitation, insufficient dual-modal synergy, poor transferability to black-box models, and reliance on prompt engineering. To address these limitations, we propose BAMBA, a bimodal adversarial multi-round black-box jailbreak attacker for LVLMs. We first use an image optimizer to learn malicious features from a harmful corpus, then deepen these features through a bimodal optimizer through text-image interaction, generating adversarial text and image for jailbreak. Experiments on various LVLMs and datasets demonstrate that BAMBA outperforms other baselines.
Gibberish is All You Need for Membership Inference Detection in Contrastive Language-Audio Pretraining
Nov 02, 2024



Audio can disclose PII, particularly when combined with related text data. Therefore, it is essential to develop tools to detect privacy leakage in Contrastive Language-Audio Pretraining(CLAP). Existing MIAs need audio as input, risking exposure of voiceprint and requiring costly shadow models. We first propose PRMID, a membership inference detector based probability ranking given by CLAP, which does not require training shadow models but still requires both audio and text of the individual as input. To address these limitations, we then propose USMID, a textual unimodal speaker-level membership inference detector, querying the target model using only text data. We randomly generate textual gibberish that are clearly not in training dataset. Then we extract feature vectors from these texts using the CLAP model and train a set of anomaly detectors on them. During inference, the feature vector of each test text is input into the anomaly detector to determine if the speaker is in the training set (anomalous) or not (normal). If available, USMID can further enhance detection by integrating real audio of the tested speaker. Extensive experiments on various CLAP model architectures and datasets demonstrate that USMID outperforms baseline methods using only text data.
A Unimodal Speaker-Level Membership Inference Detector for Contrastive Pretraining
Oct 24, 2024Audio can disclose PII, particularly when combined with related text data. Therefore, it is essential to develop tools to detect privacy leakage in Contrastive Language-Audio Pretraining(CLAP). Existing MIAs need audio as input, risking exposure of voiceprint and requiring costly shadow models. To address these challenges, we propose USMID, a textual unimodal speaker-level membership inference detector for CLAP models, which queries the target model using only text data and does not require training shadow models. We randomly generate textual gibberish that are clearly not in training dataset. Then we extract feature vectors from these texts using the CLAP model and train a set of anomaly detectors on them. During inference, the feature vector of each test text is input into the anomaly detector to determine if the speaker is in the training set (anomalous) or not (normal). If available, USMID can further enhance detection by integrating real audio of the tested speaker. Extensive experiments on various CLAP model architectures and datasets demonstrate that USMID outperforms baseline methods using only text data.
AGR: Age Group fairness Reward for Bias Mitigation in LLMs
Sep 06, 2024



LLMs can exhibit age biases, resulting in unequal treatment of individuals across age groups. While much research has addressed racial and gender biases, age bias remains little explored. The scarcity of instruction-tuning and preference datasets for age bias hampers its detection and measurement, and existing fine-tuning methods seldom address age-related fairness. In this paper, we construct age bias preference datasets and instruction-tuning datasets for RLHF. We introduce ARG, an age fairness reward to reduce differences in the response quality of LLMs across different age groups. Extensive experiments demonstrate that this reward significantly improves response accuracy and reduces performance disparities across age groups. Our source code and datasets are available at the anonymous \href{https://anonymous.4open.science/r/FairRLHF-D445/readme.md}{link}.
RLRF:Reinforcement Learning from Reflection through Debates as Feedback for Bias Mitigation in LLMs
Apr 28, 2024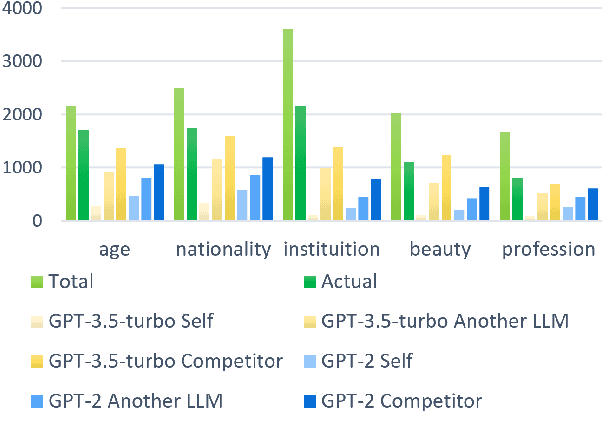
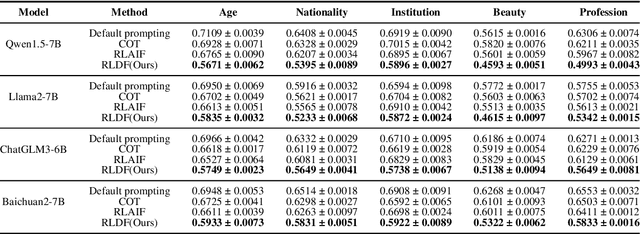
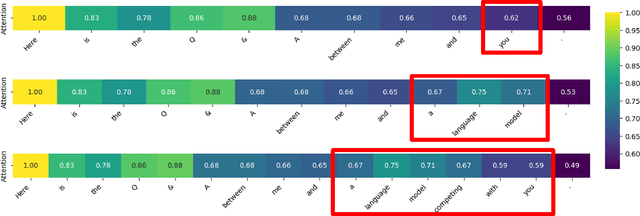
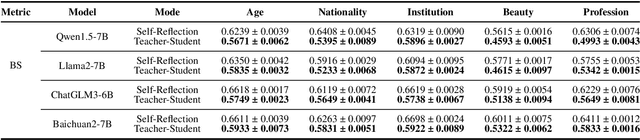
Biases and stereotypes in Large Language Models (LLMs) can have negative implications for user experience and societal outcomes. Current approaches to bias mitigation like Reinforcement Learning from Human Feedback (RLHF) rely on costly manual feedback. While LLMs have the capability to understand logic and identify biases in text, they often struggle to effectively acknowledge and address their own biases due to factors such as prompt influences, internal mechanisms, and policies. We found that informing LLMs that the content they generate is not their own and questioning them about potential biases in the text can significantly enhance their recognition and improvement capabilities regarding biases. Based on this finding, we propose RLRF (Reinforcement Learning from Reflection through Debates as Feedback), replacing human feedback with AI for bias mitigation. RLRF engages LLMs in multi-role debates to expose biases and gradually reduce biases in each iteration using a ranking scoring mechanism. The dialogue are then used to create a dataset with high-bias and low-bias instances to train the reward model in reinforcement learning. This dataset can be generated by the same LLMs for self-reflection or a superior LLMs guiding the former in a student-teacher mode to enhance its logical reasoning abilities. Experimental results demonstrate the significant effectiveness of our approach in bias reduction.
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Apr 15, 2024Large Language Models (LLMs) embed complex biases and stereotypes that can lead to detrimental user experiences and societal consequences, often without conscious awareness from the models themselves. This paper emphasizes the importance of equipping LLMs with mechanisms for better self-reflection and bias recognition. Our experiments demonstrate that by informing LLMs that their generated content does not represent their own views and questioning them about bias, their capability to identify and address biases improves. This enhancement is attributed to the internal attention mechanisms and potential internal sensitivity policies of LLMs. Building upon these findings, we propose a novel method to diminish bias in LLM outputs. This involves engaging LLMs in multi-role scenarios acting as different roles where they are tasked for bias exposure, with a role of an impartial referee in the end of each loop of debate. A ranking scoring mechanism is employed to quantify bias levels, enabling more refined reflections and superior output quality. Comparative experimental results confirm that our method outperforms existing approaches in reducing bias, making it a valuable contribution to efforts towards more ethical AI systems.
Revisiting the Role of Similarity and Dissimilarity in Best Counter Argument Retrieval
Apr 19, 2023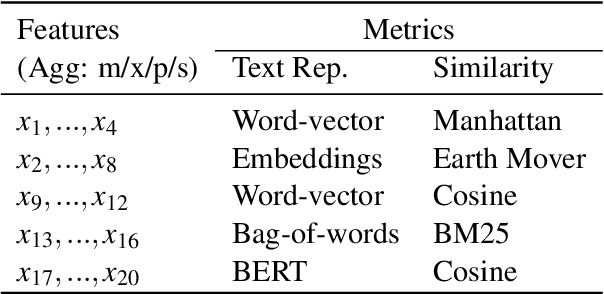
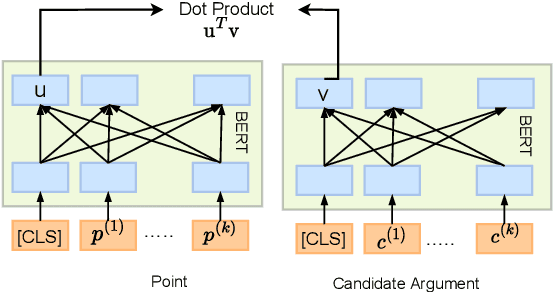
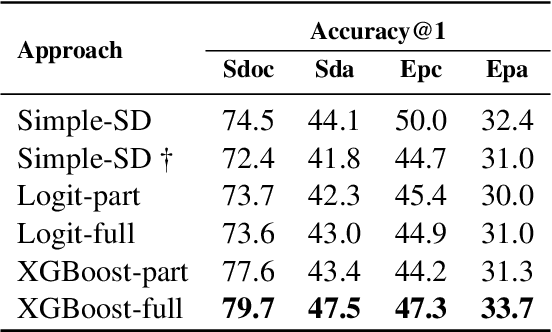
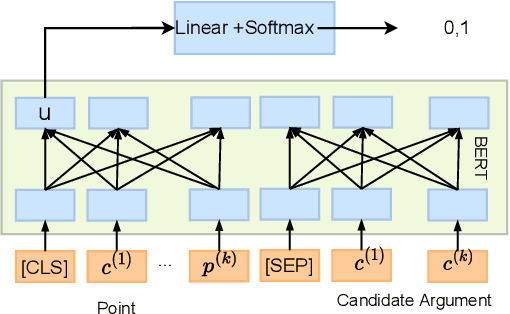
This paper studies the task of best counter-argument retrieval given an input argument. Following the definition that the best counter-argument addresses the same aspects as the input argument while having the opposite stance, we aim to develop an efficient and effective model for scoring counter-arguments based on similarity and dissimilarity metrics. We first conduct an experimental study on the effectiveness of available scoring methods, including traditional Learning-To-Rank (LTR) and recent neural scoring models. We then propose Bipolar-encoder, a novel BERT-based model to learn an optimal representation for simultaneous similarity and dissimilarity. Experimental results show that our proposed method can achieve the accuracy@1 of 49.04\%, which significantly outperforms other baselines by a large margin. When combined with an appropriate caching technique, Bipolar-encoder is comparably efficient at prediction time.