 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Paper and Code
Apr 15, 2024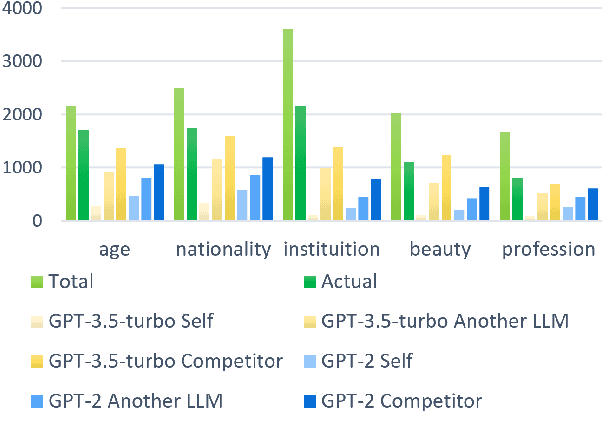
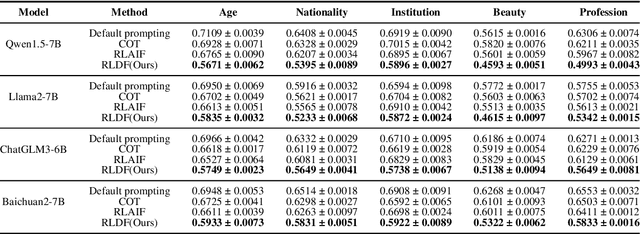
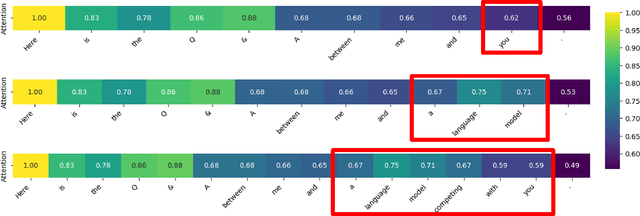
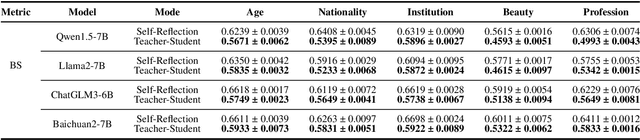
Large Language Models (LLMs) embed complex biases and stereotypes that can lead to detrimental user experiences and societal consequences, often without conscious awareness from the models themselves. This paper emphasizes the importance of equipping LLMs with mechanisms for better self-reflection and bias recognition. Our experiments demonstrate that by informing LLMs that their generated content does not represent their own views and questioning them about bias, their capability to identify and address biases improves. This enhancement is attributed to the internal attention mechanisms and potential internal sensitivity policies of LLMs. Building upon these findings, we propose a novel method to diminish bias in LLM outputs. This involves engaging LLMs in multi-role scenarios acting as different roles where they are tasked for bias exposure, with a role of an impartial referee in the end of each loop of debate. A ranking scoring mechanism is employed to quantify bias levels, enabling more refined reflections and superior output quality. Comparative experimental results confirm that our method outperforms existing approaches in reducing bias, making it a valuable contribution to efforts towards more ethical AI systems.