 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAS-X: Neural Adaptive Smoothing via Twisting
Aug 28, 2023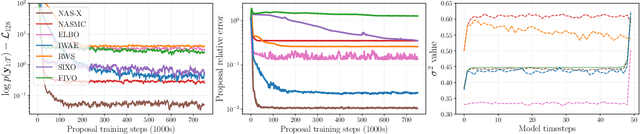
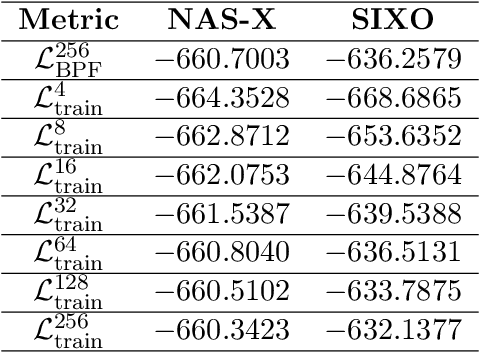
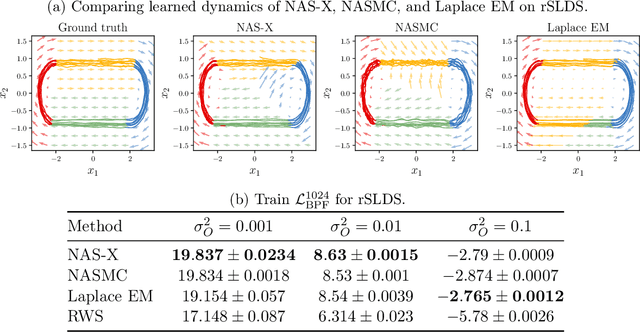

We present Neural Adaptive Smoothing via Twisting (NAS-X), a method for learning and inference in sequential latent variable models based on reweighted wake-sleep (RWS). NAS-X works with both discrete and continuous latent variables, and leverages smoothing SMC to fit a broader range of models than traditional RWS methods. We test NAS-X on discrete and continuous tasks and find that it substantially outperforms previous variational and RWS-based methods in inference and parameter recovery.
SIXO: Smoothing Inference with Twisted Objectives
Jun 20, 2022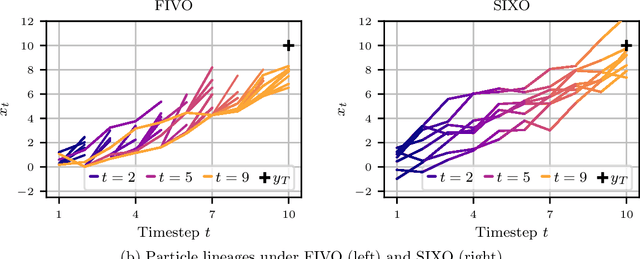

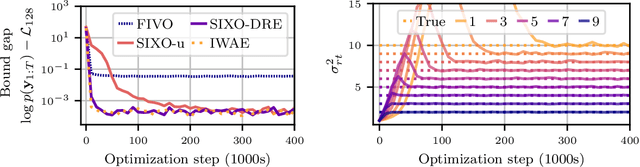
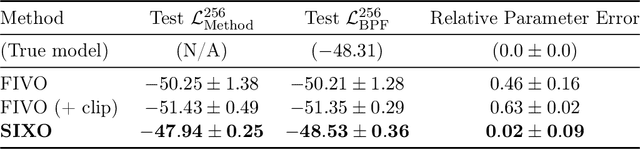
Sequential Monte Carlo (SMC) is an inference algorithm for state space models that approximates the posterior by sampling from a sequence of target distributions. The target distributions are often chosen to be the filtering distributions, but these ignore information from future observations, leading to practical and theoretical limitations in inference and model learning. We introduce SIXO, a method that instead learns targets that approximate the smoothing distributions, incorporating information from all observations. The key idea is to use density ratio estimation to fit functions that warp the filtering distributions into the smoothing distributions. We then use SMC with these learned targets to define a variational objective for model and proposal learning. SIXO yields provably tighter log marginal lower bounds and offers significantly more accurate posterior inferences and parameter estimates in a variety of domains.
Evaluating Predictive Distributions: Does Bayesian Deep Learning Work?
Oct 09, 2021
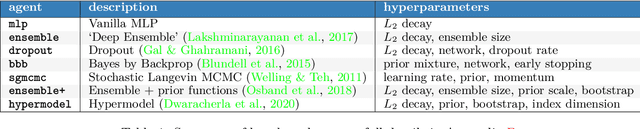
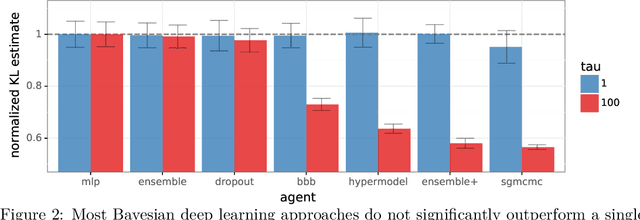
Posterior predictive distributions quantify uncertainties ignored by point estimates. This paper introduces \textit{The Neural Testbed}, which provides tools for the systematic evaluation of agents that generate such predictions. Crucially, these tools assess not only the quality of marginal predictions per input, but also joint predictions given many inputs. Joint distributions are often critical for useful uncertainty quantification, but they have been largely overlooked by the Bayesian deep learning community. We benchmark several approaches to uncertainty estimation using a neural-network-based data generating process. Our results reveal the importance of evaluation beyond marginal predictions. Further, they reconcile sources of confusion in the field, such as why Bayesian deep learning approaches that generate accurate marginal predictions perform poorly in sequential decision tasks, how incorporating priors can be helpful, and what roles epistemic versus aleatoric uncertainty play when evaluating performance. We also present experiments on real-world challenge datasets, which show a high correlation with testbed results, and that the importance of evaluating joint predictive distributions carries over to real data. As part of this effort, we opensource The Neural Testbed, including all implementations from this paper.
Energy-Inspired Models: Learning with Sampler-Induced Distributions
Oct 31, 2019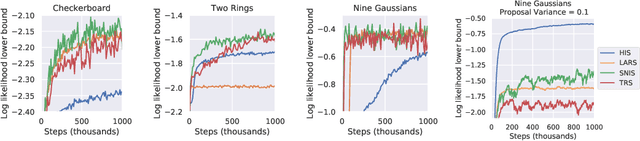
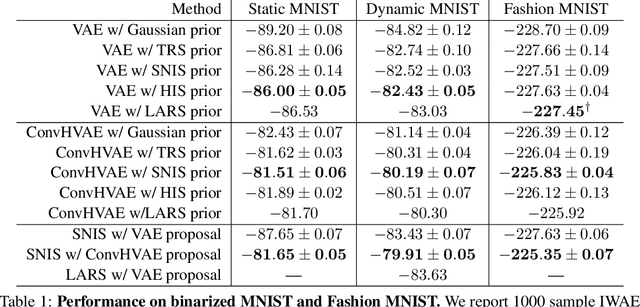
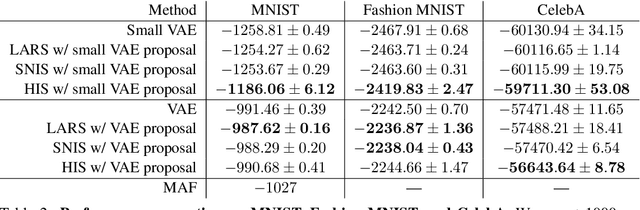
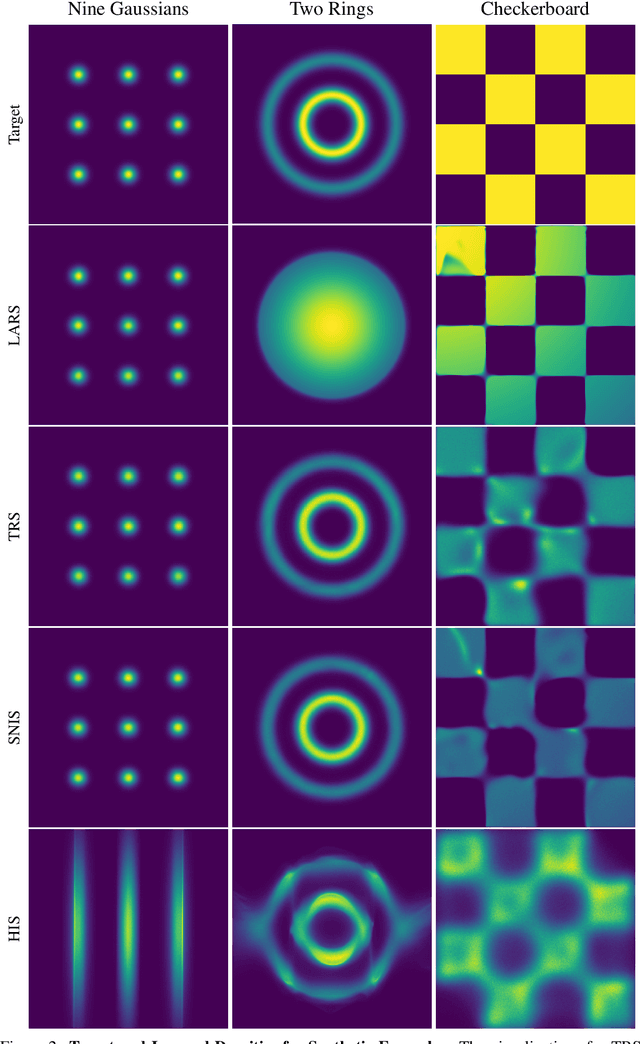
Energy-based models (EBMs) are powerful probabilistic models, but suffer from intractable sampling and density evaluation due to the partition function. As a result, inference in EBMs relies on approximate sampling algorithms, leading to a mismatch between the model and inference. Motivated by this, we consider the sampler-induced distribution as the model of interest and maximize the likelihood of this model. This yields a class of energy-inspired models (EIMs) that incorporate learned energy functions while still providing exact samples and tractable log-likelihood lower bounds. We describe and evaluate three instantiations of such models based on truncated rejection sampling, self-normalized importance sampling, and Hamiltonian importance sampling. These models outperform or perform comparably to the recently proposed Learned Accept/Reject Sampling algorithm and provide new insights on ranking Noise Contrastive Estimation and Contrastive Predictive Coding. Moreover, EIMs allow us to generalize a recent connection between multi-sample variational lower bounds and auxiliary variable variational inference. We show how recent variational bounds can be unified with EIMs as the variational family.
Doubly Reparameterized Gradient Estimators for Monte Carlo Objectives
Oct 09, 2018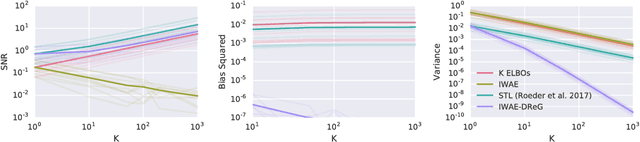
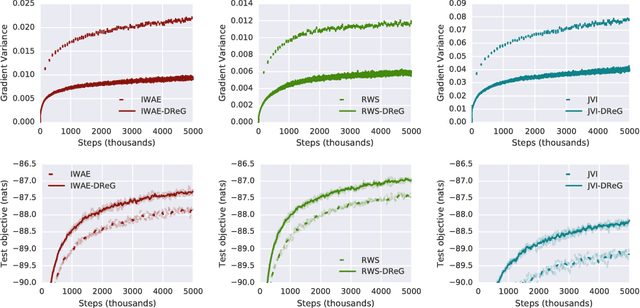
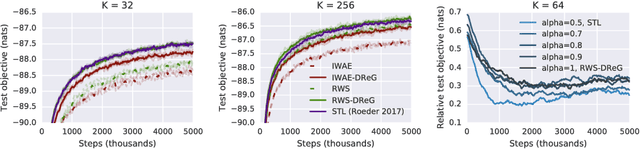
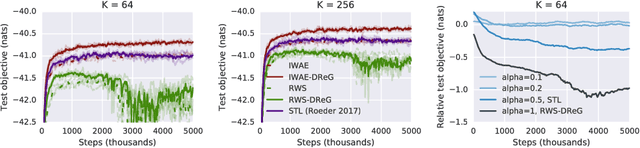
Deep latent variable models have become a popular model choice due to the scalable learning algorithms introduced by (Kingma & Welling, 2013; Rezende et al., 2014). These approaches maximize a variational lower bound on the intractable log likelihood of the observed data. Burda et al. (2015) introduced a multi-sample variational bound, IWAE, that is at least as tight as the standard variational lower bound and becomes increasingly tight as the number of samples increases. Counterintuitively, the typical inference network gradient estimator for the IWAE bound performs poorly as the number of samples increases (Rainforth et al., 2018; Le et al., 2018). Roeder et al. (2017) propose an improved gradient estimator, however, are unable to show it is unbiased. We show that it is in fact biased and that the bias can be estimated efficiently with a second application of the reparameterization trick. The doubly reparameterized gradient (DReG) estimator does not suffer as the number of samples increases, resolving the previously raised issues. The same idea can be used to improve many recently introduced training techniques for latent variable models. In particular, we show that this estimator reduces the variance of the IWAE gradient, the reweighted wake-sleep update (RWS) (Bornschein & Bengio, 2014), and the jackknife variational inference (JVI) gradient (Nowozin, 2018). Finally, we show that this computationally efficient, unbiased drop-in gradient estimator translates to improved performance for all three objectives on several modeling tasks.
Filtering Variational Objectives
Nov 12, 2017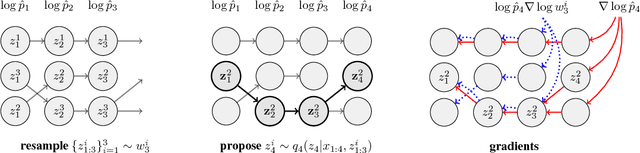
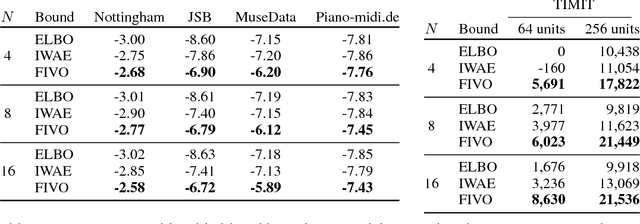
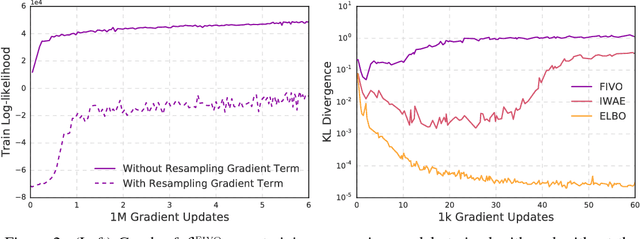
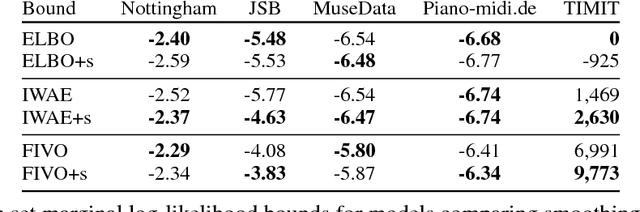
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter's estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model's sequential structure to form tighter bounds. We present results that relate the tightness of FIVO's bound to the variance of the particle filter's estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.
REBAR: Low-variance, unbiased gradient estimates for discrete latent variable models
Nov 06, 2017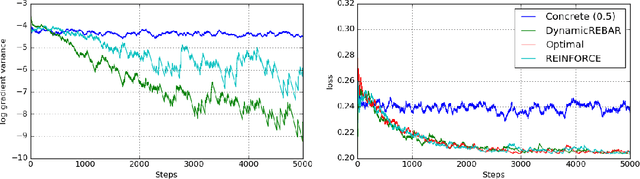

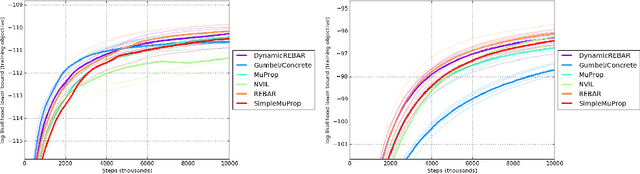
Learning in models with discrete latent variables is challenging due to high variance gradient estimators. Generally, approaches have relied on control variates to reduce the variance of the REINFORCE estimator. Recent work (Jang et al. 2016, Maddison et al. 2016) has taken a different approach, introducing a continuous relaxation of discrete variables to produce low-variance, but biased, gradient estimates. In this work, we combine the two approaches through a novel control variate that produces low-variance, \emph{unbiased} gradient estimates. Then, we introduce a modification to the continuous relaxation and show that the tightness of the relaxation can be adapted online, removing it as a hyperparameter. We show state-of-the-art variance reduction on several benchmark generative modeling tasks, generally leading to faster convergence to a better final log-likelihood.
Learning Hard Alignments with Variational Inference
Nov 01, 2017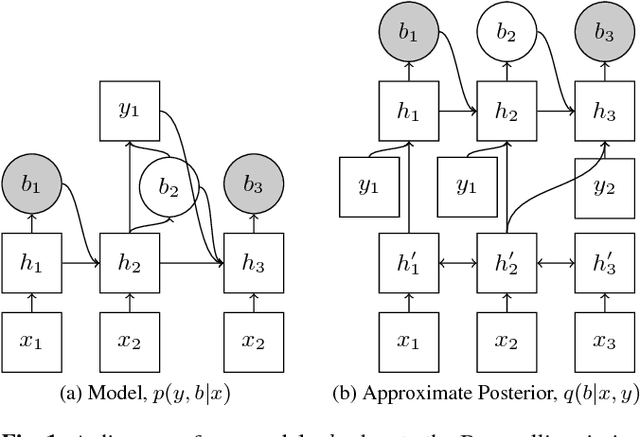
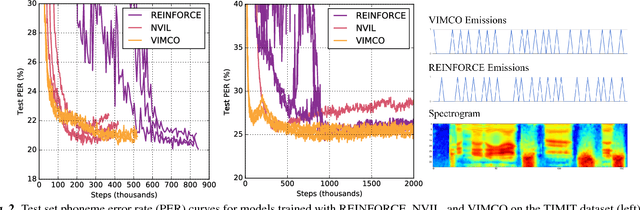
There has recently been significant interest in hard attention models for tasks such as object recognition, visual captioning and speech recognition. Hard attention can offer benefits over soft attention such as decreased computational cost, but training hard attention models can be difficult because of the discrete latent variables they introduce. Previous work used REINFORCE and Q-learning to approach these issues, but those methods can provide high-variance gradient estimates and be slow to train. In this paper, we tackle the problem of learning hard attention for a sequential task using variational inference methods, specifically the recently introduced VIMCO and NVIL. Furthermore, we propose a novel baseline that adapts VIMCO to this setting. We demonstrate our method on a phoneme recognition task in clean and noisy environments and show that our method outperforms REINFORCE, with the difference being greater for a more complicated task.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017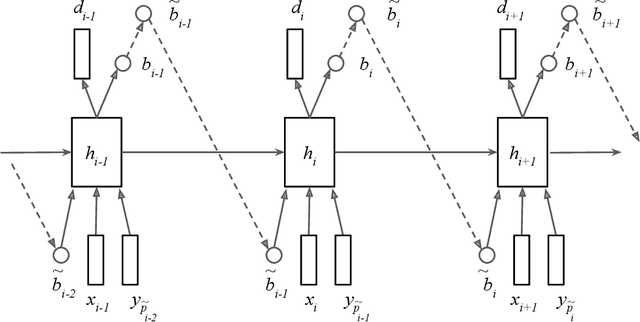
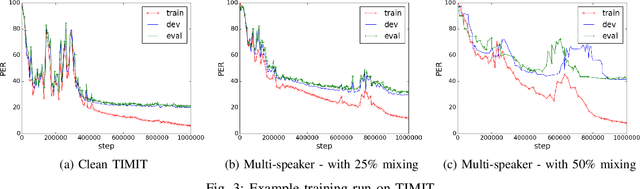
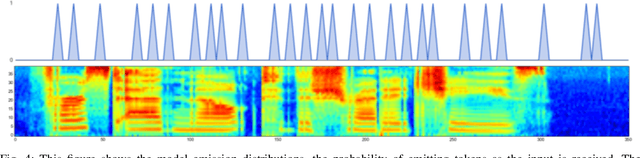
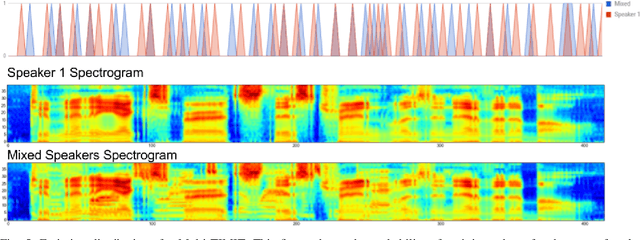
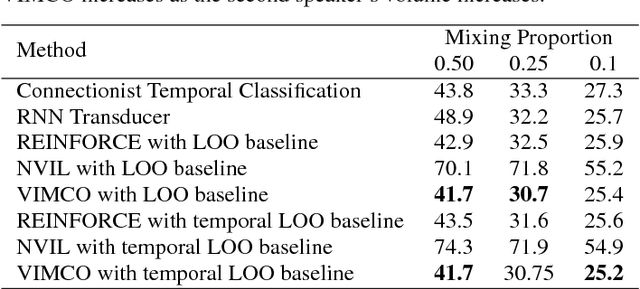
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.
Training a Subsampling Mechanism in Expectation
Apr 08, 2017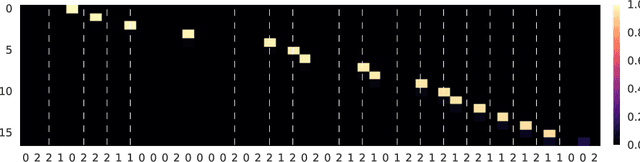
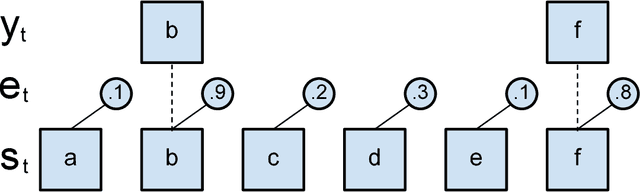
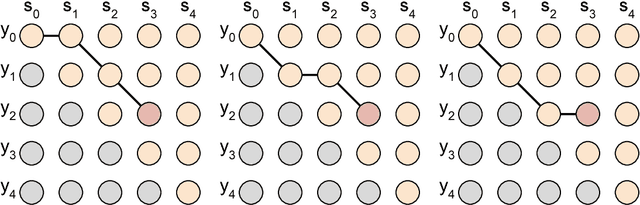
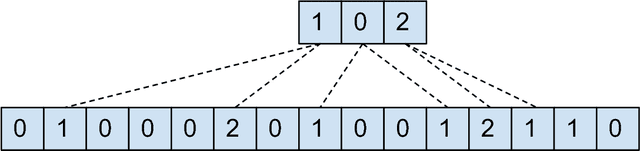
We describe a mechanism for subsampling sequences and show how to compute its expected output so that it can be trained with standard backpropagation. We test this approach on a simple toy problem and discuss its shortcomings.