 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembles for Uncertainty Estimation: Benefits of Prior Functions and Bootstrapping
Paper and Code

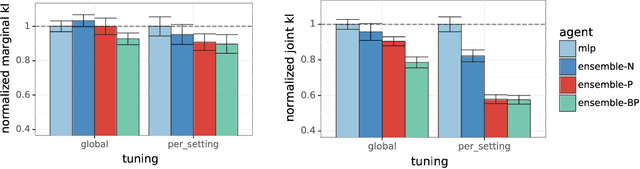


In machine learning, an agent needs to estimate uncertainty to efficiently explore and adapt and to make effective decisions. A common approach to uncertainty estimation maintains an ensemble of models. In recent years, several approaches have been proposed for training ensembles, and conflicting views prevail with regards to the importance of various ingredients of these approaches. In this paper, we aim to address the benefits of two ingredients -- prior functions and bootstrapping -- which have come into question. We show that prior functions can significantly improve an ensemble agent's joint predictions across inputs and that bootstrapping affords additional benefits if the signal-to-noise ratio varies across inputs. Our claims are justified by both theoretical and experimental results.