 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Difference Learning Using Distributed Error Signals
Nov 06, 2024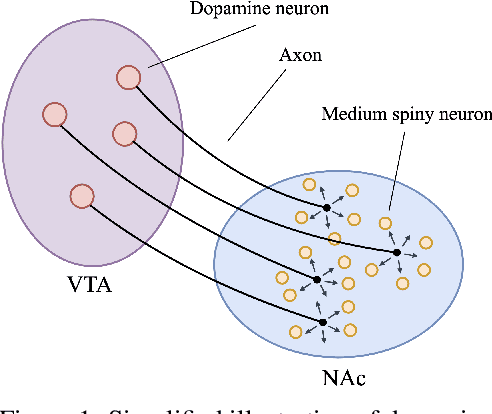
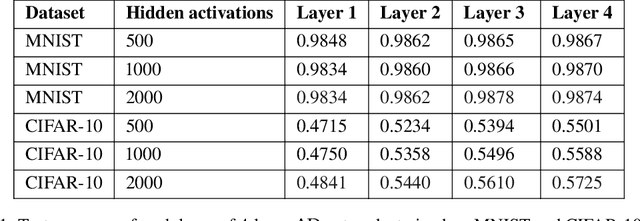

A computational problem in biological reward-based learning is how credit assignment is performed in the nucleus accumbens (NAc). Much research suggests that NAc dopamine encodes temporal-difference (TD) errors for learning value predictions. However, dopamine is synchronously distributed in regionally homogeneous concentrations, which does not support explicit credit assignment (like used by backpropagation). It is unclear whether distributed errors alone are sufficient for synapses to make coordinated updates to learn complex, nonlinear reward-based learning tasks. We design a new deep Q-learning algorithm, Artificial Dopamine, to computationally demonstrate that synchronously distributed, per-layer TD errors may be sufficient to learn surprisingly complex RL tasks. We empirically evaluate our algorithm on MinAtar, the DeepMind Control Suite, and classic control tasks, and show it often achieves comparable performance to deep RL algorithms that use backpropagation.
Novelty Search for Deep Reinforcement Learning Policy Network Weights by Action Sequence Edit Metric Distance
Feb 08, 2019


Reinforcement learning (RL) problems often feature deceptive local optima, and learning methods that optimize purely for reward signal often fail to learn strategies for overcoming them. Deep neuroevolution and novelty search have been proposed as effective alternatives to gradient-based methods for learning RL policies directly from pixels. In this paper, we introduce and evaluate the use of novelty search over agent action sequences by string edit metric distance as a means for promoting innovation. We also introduce a method for stagnation detection and population resampling inspired by recent developments in the RL community that uses the same mechanisms as novelty search to promote and develop innovative policies. Our methods extend a state-of-the-art method for deep neuroevolution using a simple-yet-effective genetic algorithm (GA) designed to efficiently learn deep RL policy network weights. Experiments using four games from the Atari 2600 benchmark were conducted. Results provide further evidence that GAs are competitive with gradient-based algorithms for deep RL. Results also demonstrate that novelty search over action sequences is an effective source of selection pressure that can be integrated into existing evolutionary algorithms for deep RL.
On the Generalizability of Linear and Non-Linear Region of Interest-Based Multivariate Regression Models for fMRI Data
Feb 03, 2018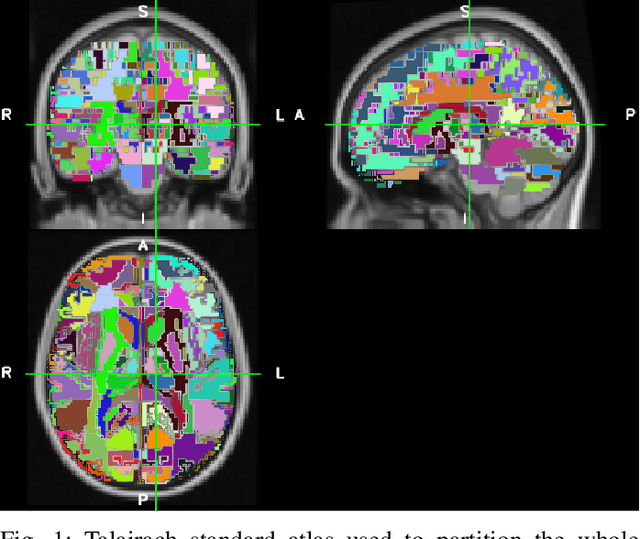

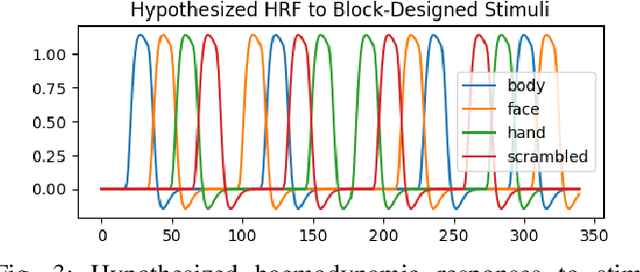
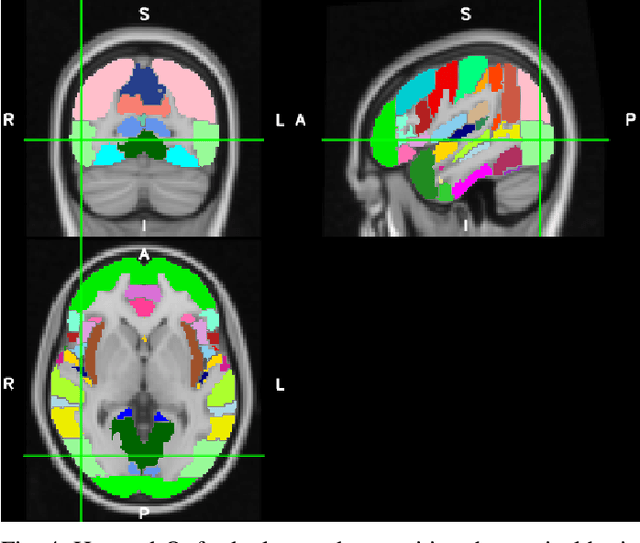
In contrast to conventional, univariate analysis, various types of multivariate analysis have been applied to functional magnetic resonance imaging (fMRI) data. In this paper, we compare two contemporary approaches for multivariate regression on task-based fMRI data: linear regression with ridge regularization and non-linear symbolic regression using genetic programming. The data for this project is representative of a contemporary fMRI experimental design for visual stimuli. Linear and non-linear models were generated for 10 subjects, with another 4 withheld for validation. Model quality is evaluated by comparing $R$ scores (Pearson product-moment correlation) in various contexts, including single run self-fit, within-subject generalization, and between-subject generalization. Propensity for modelling strategies to overfit is estimated using a separate resting state scan. Results suggest that neither method is objectively or inherently better than the other.