 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty Search for Deep Reinforcement Learning Policy Network Weights by Action Sequence Edit Metric Distance
Paper and Code
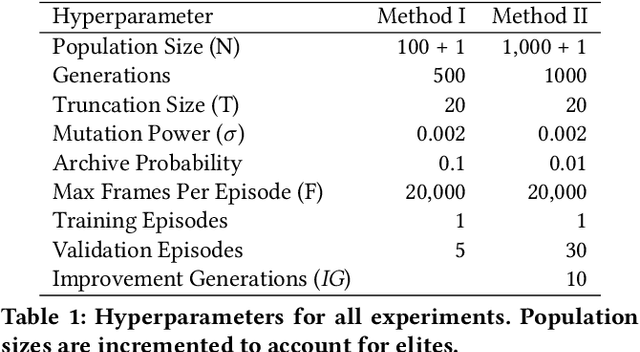


Reinforcement learning (RL) problems often feature deceptive local optima, and learning methods that optimize purely for reward signal often fail to learn strategies for overcoming them. Deep neuroevolution and novelty search have been proposed as effective alternatives to gradient-based methods for learning RL policies directly from pixels. In this paper, we introduce and evaluate the use of novelty search over agent action sequences by string edit metric distance as a means for promoting innovation. We also introduce a method for stagnation detection and population resampling inspired by recent developments in the RL community that uses the same mechanisms as novelty search to promote and develop innovative policies. Our methods extend a state-of-the-art method for deep neuroevolution using a simple-yet-effective genetic algorithm (GA) designed to efficiently learn deep RL policy network weights. Experiments using four games from the Atari 2600 benchmark were conducted. Results provide further evidence that GAs are competitive with gradient-based algorithms for deep RL. Results also demonstrate that novelty search over action sequences is an effective source of selection pressure that can be integrated into existing evolutionary algorithms for deep RL.