 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGFN: Double Generative Flow Networks
Nov 06, 2023



Deep learning is emerging as an effective tool in drug discovery, with potential applications in both predictive and generative models. Generative Flow Networks (GFlowNets/GFNs) are a recently introduced method recognized for the ability to generate diverse candidates, in particular in small molecule generation tasks. In this work, we introduce double GFlowNets (DGFNs). Drawing inspiration from reinforcement learning and Double Deep Q-Learning, we introduce a target network used to sample trajectories, while updating the main network with these sampled trajectories. Empirical results confirm that DGFNs effectively enhance exploration in sparse reward domains and high-dimensional state spaces, both challenging aspects of de-novo design in drug discovery.
An Empirical Study of the Effectiveness of Using a Replay Buffer on Mode Discovery in GFlowNets
Jul 18, 2023
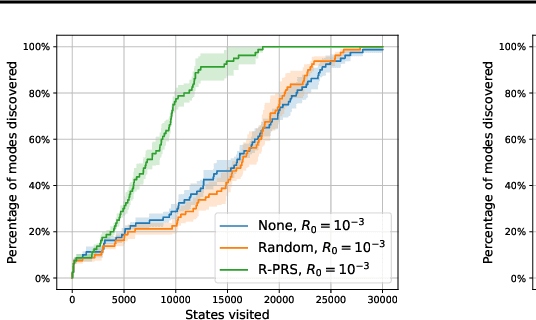


Reinforcement Learning (RL) algorithms aim to learn an optimal policy by iteratively sampling actions to learn how to maximize the total expected return, $R(x)$. GFlowNets are a special class of algorithms designed to generate diverse candidates, $x$, from a discrete set, by learning a policy that approximates the proportional sampling of $R(x)$. GFlowNets exhibit improved mode discovery compared to conventional RL algorithms, which is very useful for applications such as drug discovery and combinatorial search. However, since GFlowNets are a relatively recent class of algorithms, many techniques which are useful in RL have not yet been associated with them. In this paper, we study the utilization of a replay buffer for GFlowNets. We explore empirically various replay buffer sampling techniques and assess the impact on the speed of mode discovery and the quality of the modes discovered. Our experimental results in the Hypergrid toy domain and a molecule synthesis environment demonstrate significant improvements in mode discovery when training with a replay buffer, compared to training only with trajectories generated on-policy.