Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQGFN: Controllable Greediness with Action Values
Paper and Code
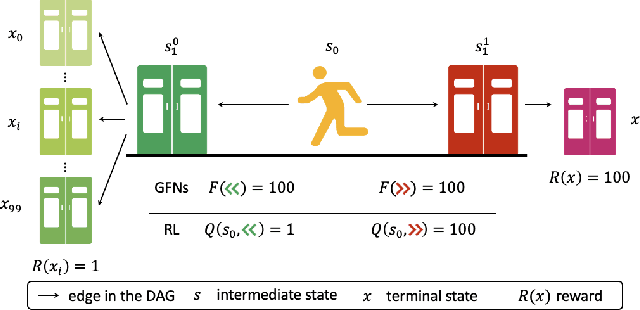

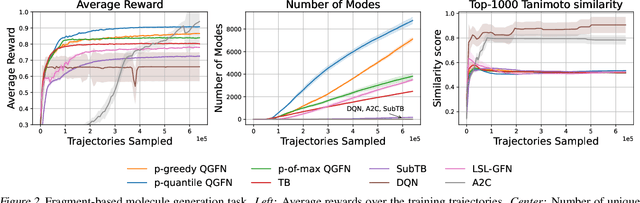
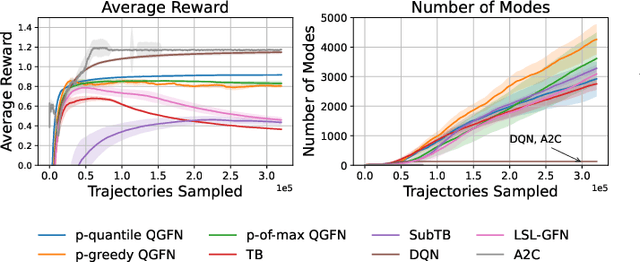
Generative Flow Networks (GFlowNets; GFNs) are a family of reward/energy-based generative methods for combinatorial objects, capable of generating diverse and high-utility samples. However, biasing GFNs towards producing high-utility samples is non-trivial. In this work, we leverage connections between GFNs and reinforcement learning (RL) and propose to combine the GFN policy with an action-value estimate, $Q$, to create greedier sampling policies which can be controlled by a mixing parameter. We show that several variants of the proposed method, QGFN, are able to improve on the number of high-reward samples generated in a variety of tasks without sacrificing diversity.
* Under review
View paper on