 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Faetar Benchmark: Speech Recognition in a Very Under-Resourced Language
Sep 12, 2024
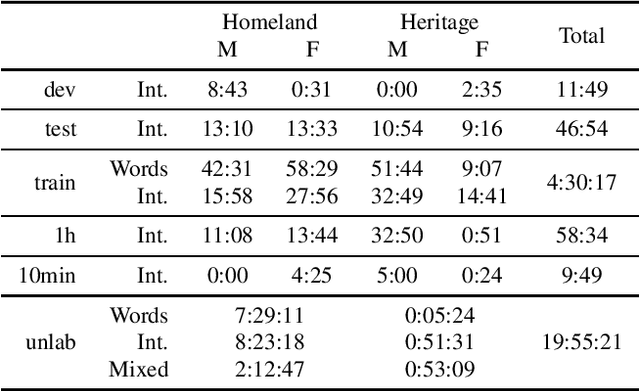
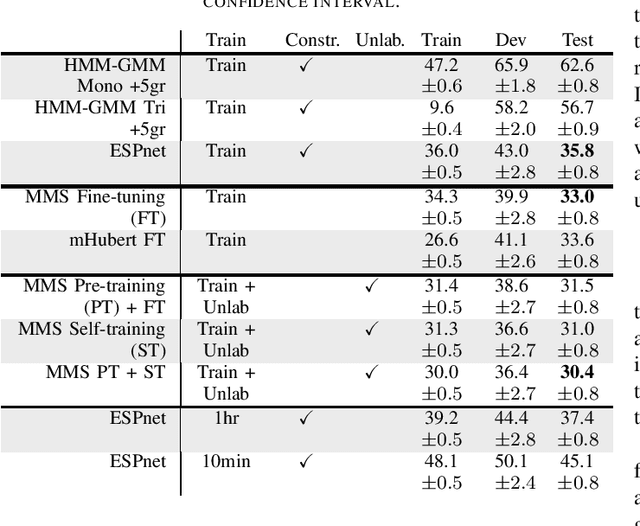
We introduce the Faetar Automatic Speech Recognition Benchmark, a benchmark corpus designed to push the limits of current approaches to low-resource speech recognition. Faetar, a Franco-Proven\c{c}al variety spoken primarily in Italy, has no standard orthography, has virtually no existing textual or speech resources other than what is included in the benchmark, and is quite different from other forms of Franco-Proven\c{c}al. The corpus comes from field recordings, most of which are noisy, for which only 5 hrs have matching transcriptions, and for which forced alignment is of variable quality. The corpus contains an additional 20 hrs of unlabelled speech. We report baseline results from state-of-the-art multilingual speech foundation models with a best phone error rate of 30.4%, using a pipeline that continues pre-training on the foundation model using the unlabelled set.
Evaluating context-invariance in unsupervised speech representations
Oct 27, 2022



Unsupervised speech representations have taken off, with benchmarks (SUPERB, ZeroSpeech) demonstrating major progress on semi-supervised speech recognition, speech synthesis, and speech-only language modelling. Inspiration comes from the promise of ``discovering the phonemes'' of a language or a similar low-bitrate encoding. However, one of the critical properties of phoneme transcriptions is context-invariance: the phonetic context of a speech sound can have massive influence on the way it is pronounced, while the text remains stable. This is what allows tokens of the same word to have the same transcriptions -- key to language understanding. Current benchmarks do not measure context-invariance. We develop a new version of the ZeroSpeech ABX benchmark that measures context-invariance, and apply it to recent self-supervised representations. We demonstrate that the context-independence of representations is predictive of the stability of word-level representations. We suggest research concentrate on improving context-independence of self-supervised and unsupervised representations.