 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Resource Code-switched Speech Benchmark Using Speech Utterance Pairs For Multiple Spoken Languages
Paper and Code

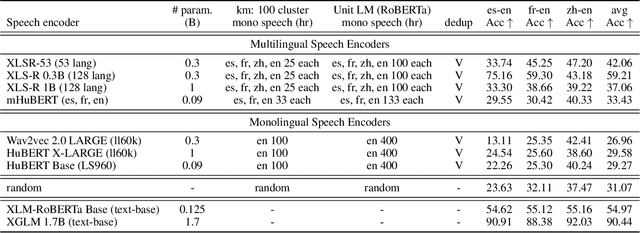
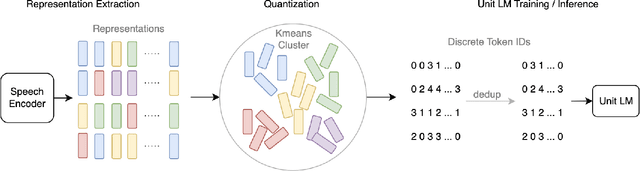
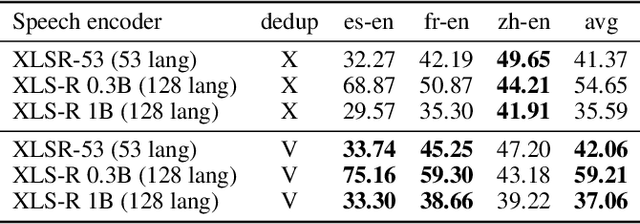
We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance. Notably, though our results demonstrate that speech encoders with multilingual pre-training, exemplified by XLSR, outperform monolingual variants (Wav2vec 2.0, HuBERT) in code-switching scenarios, there is still substantial room for improvement in their code-switching linguistic abilities.