 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeft-right asymmetry in predicting brain activity from LLMs' representations emerges with their formal linguistic competence
Feb 13, 2026When humans and large language models (LLMs) process the same text, activations in the LLMs correlate with brain activity measured, e.g., with functional magnetic resonance imaging (fMRI). Moreover, it has been shown that, as the training of an LLM progresses, the performance in predicting brain activity from its internal activations improves more in the left hemisphere than in the right one. The aim of the present work is to understand which kind of competence acquired by the LLMs underlies the emergence of this left-right asymmetry. Using the OLMo-2 7B language model at various training checkpoints and fMRI data from English participants, we compare the evolution of the left-right asymmetry in brain scores alongside performance on several benchmarks. We observe that the asymmetry co-emerges with the formal linguistic abilities of the LLM. These abilities are demonstrated in two ways: by the model's capacity to assign a higher probability to an acceptable sentence than to a grammatically unacceptable one within a minimal contrasting pair, or its ability to produce well-formed text. On the opposite, the left-right asymmetry does not correlate with the performance on arithmetic or Dyck language tasks; nor with text-based tasks involving world knowledge and reasoning. We generalize these results to another family of LLMs (Pythia) and another language, namely French. Our observations indicate that the left-right asymmetry in brain predictivity matches the progress in formal linguistic competence (knowledge of linguistic patterns).
Category learning in deep neural networks: Information content and geometry of internal representations
Oct 21, 2025In animals, category learning enhances discrimination between stimuli close to the category boundary. This phenomenon, called categorical perception, was also empirically observed in artificial neural networks trained on classification tasks. In previous modeling works based on neuroscience data, we show that this expansion/compression is a necessary outcome of efficient learning. Here we extend our theoretical framework to artificial networks. We show that minimizing the Bayes cost (mean of the cross-entropy loss) implies maximizing the mutual information between the set of categories and the neural activities prior to the decision layer. Considering structured data with an underlying feature space of small dimension, we show that maximizing the mutual information implies (i) finding an appropriate projection space, and, (ii) building a neural representation with the appropriate metric. The latter is based on a Fisher information matrix measuring the sensitivity of the neural activity to changes in the projection space. Optimal learning makes this neural Fisher information follow a category-specific Fisher information, measuring the sensitivity of the category membership. Category learning thus induces an expansion of neural space near decision boundaries. We characterize the properties of the categorical Fisher information, showing that its eigenvectors give the most discriminant directions at each point of the projection space. We find that, unexpectedly, its maxima are in general not exactly at, but near, the class boundaries. Considering toy models and the MNIST dataset, we numerically illustrate how after learning the two Fisher information matrices match, and essentially align with the category boundaries. Finally, we relate our approach to the Information Bottleneck one, and we exhibit a bias-variance decomposition of the Bayes cost, of interest on its own.
fMRI predictors based on language models of increasing complexity recover brain left lateralization
May 28, 2024



Over the past decade, studies of naturalistic language processing where participants are scanned while listening to continuous text have flourished. Using word embeddings at first, then large language models, researchers have created encoding models to analyze the brain signals. Presenting these models with the same text as the participants allows to identify brain areas where there is a significant correlation between the functional magnetic resonance imaging (fMRI) time series and the ones predicted by the models' artificial neurons. One intriguing finding from these studies is that they have revealed highly symmetric bilateral activation patterns, somewhat at odds with the well-known left lateralization of language processing. Here, we report analyses of an fMRI dataset where we manipulate the complexity of large language models, testing 28 pretrained models from 8 different families, ranging from 124M to 14.2B parameters. First, we observe that the performance of models in predicting brain responses follows a scaling law, where the fit with brain activity increases linearly with the logarithm of the number of parameters of the model (and its performance on natural language processing tasks). Second, we show that a left-right asymmetry gradually appears as model size increases, and that the difference in left-right brain correlations also follows a scaling law. Whereas the smallest models show no asymmetry, larger models fit better and better left hemispheric activations than right hemispheric ones. This finding reconciles computational analyses of brain activity using large language models with the classic observation from aphasic patients showing left hemisphere dominance for language.
Acoustic characterization of speech rhythm: going beyond metrics with recurrent neural networks
Jan 22, 2024Languages have long been described according to their perceived rhythmic attributes. The associated typologies are of interest in psycholinguistics as they partly predict newborns' abilities to discriminate between languages and provide insights into how adult listeners process non-native languages. Despite the relative success of rhythm metrics in supporting the existence of linguistic rhythmic classes, quantitative studies have yet to capture the full complexity of temporal regularities associated with speech rhythm. We argue that deep learning offers a powerful pattern-recognition approach to advance the characterization of the acoustic bases of speech rhythm. To explore this hypothesis, we trained a medium-sized recurrent neural network on a language identification task over a large database of speech recordings in 21 languages. The network had access to the amplitude envelopes and a variable identifying the voiced segments, assuming that this signal would poorly convey phonetic information but preserve prosodic features. The network was able to identify the language of 10-second recordings in 40% of the cases, and the language was in the top-3 guesses in two-thirds of the cases. Visualization methods show that representations built from the network activations are consistent with speech rhythm typologies, although the resulting maps are more complex than two separated clusters between stress and syllable-timed languages. We further analyzed the model by identifying correlations between network activations and known speech rhythm metrics. The findings illustrate the potential of deep learning tools to advance our understanding of speech rhythm through the identification and exploration of linguistically relevant acoustic feature spaces.
Information theoretic study of the neural geometry induced by category learning
Nov 27, 2023

Categorization is an important topic both for biological and artificial neural networks. Here, we take an information theoretic approach to assess the efficiency of the representations induced by category learning. We show that one can decompose the relevant Bayesian cost into two components, one for the coding part and one for the decoding part. Minimizing the coding cost implies maximizing the mutual information between the set of categories and the neural activities. We analytically show that this mutual information can be written as the sum of two terms that can be interpreted as (i) finding an appropriate representation space, and, (ii) building a representation with the appropriate metrics, based on the neural Fisher information on this space. One main consequence is that category learning induces an expansion of neural space near decision boundaries. Finally, we provide numerical illustrations that show how Fisher information of the coding neural population aligns with the boundaries between categories.
Interpolation, extrapolation, and local generalization in common neural networks
Jul 18, 2022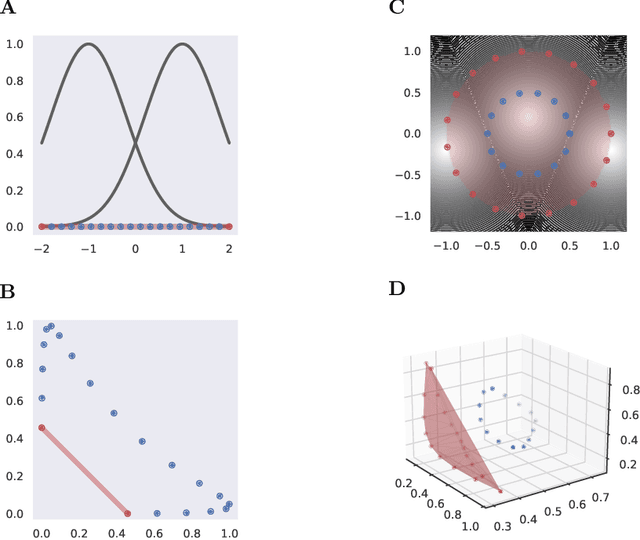
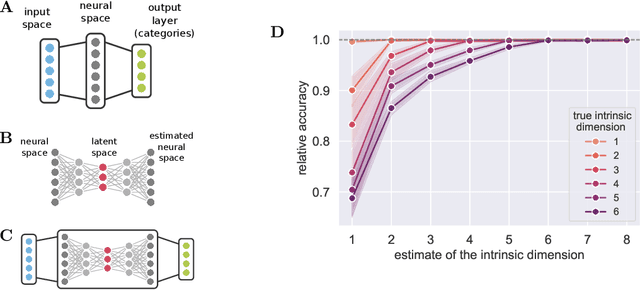

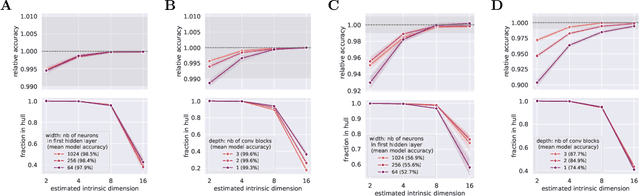
There has been a long history of works showing that neural networks have hard time extrapolating beyond the training set. A recent study by Balestriero et al. (2021) challenges this view: defining interpolation as the state of belonging to the convex hull of the training set, they show that the test set, either in input or neural space, cannot lie for the most part in this convex hull, due to the high dimensionality of the data, invoking the well known curse of dimensionality. Neural networks are then assumed to necessarily work in extrapolative mode. We here study the neural activities of the last hidden layer of typical neural networks. Using an autoencoder to uncover the intrinsic space underlying the neural activities, we show that this space is actually low-dimensional, and that the better the model, the lower the dimensionality of this intrinsic space. In this space, most samples of the test set actually lie in the convex hull of the training set: under the convex hull definition, the models thus happen to work in interpolation regime. Moreover, we show that belonging to the convex hull does not seem to be the relevant criteria. Different measures of proximity to the training set are actually better related to performance accuracy. Thus, typical neural networks do seem to operate in interpolation regime. Good generalization performances are linked to the ability of a neural network to operate well in such a regime.
Categorical Perception: A Groundwork for Deep Learning
Dec 10, 2020


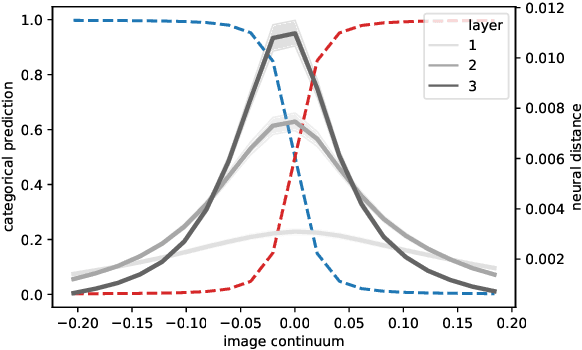
Classification is one of the major tasks that deep learning is successfully tackling. Categorization is also a fundamental cognitive ability. A well-known perceptual consequence of categorization in humans and other animals, called categorical perception, is characterized by a within-category compression and a between-category separation: two items, close in input space, are perceived closer if they belong to the same category than if they belong to different categories. Elaborating on experimental and theoretical results in cognitive science, here we study categorical effects in artificial neural networks. Our formal and numerical analysis provides insights into the geometry of the neural representation in deep layers, with expansion of space near category boundaries and contraction far from category boundaries. We investigate categorical representation by using two complementary approaches: one mimics experiments in psychophysics and cognitive neuroscience by means of morphed continua between stimuli of different categories, while the other introduces a categoricality index that quantifies the separability of the classes at the population level (a given layer in the neural network). We show on both shallow and deep neural networks that category learning automatically induces categorical perception. We further show that the deeper a layer, the stronger the categorical effects. An important outcome of our analysis is to provide a coherent and unifying view of the efficacy of different heuristic practices of the dropout regularization technique. Our views, which find echoes in the neuroscience literature, insist on the differential role of noise as a function of the level of representation and in the course of learning: noise injected in the hidden layers gets structured according to the organization of the categories, more variability being allowed within a category than across classes.
KerCNNs: biologically inspired lateral connections for classification of corrupted images
Oct 18, 2019
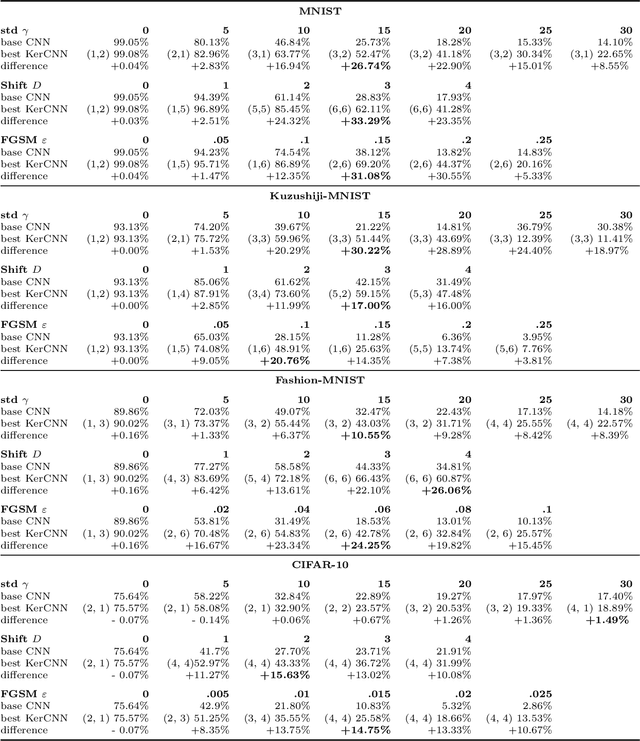
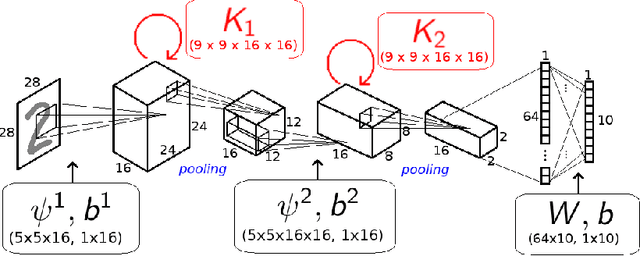
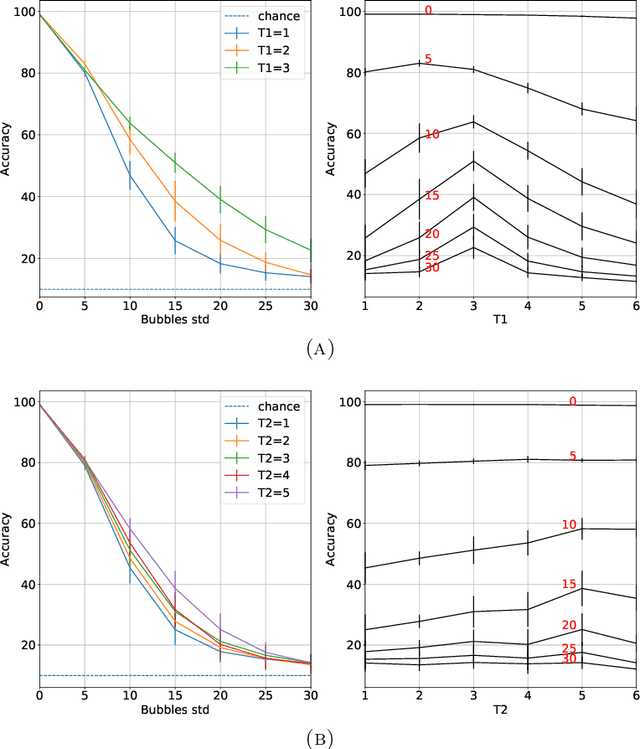
The state of the art in many computer vision tasks is represented by Convolutional Neural Networks (CNNs). Although their hierarchical organization and local feature extraction are inspired by the structure of primate visual systems, the lack of lateral connections in such architectures critically distinguishes their analysis from biological object processing. The idea of enriching CNNs with recurrent lateral connections of convolutional type has been put into practice in recent years, in the form of learned recurrent kernels with no geometrical constraints. In the present work, we introduce biologically plausible lateral kernels encoding a notion of correlation between the feedforward filters of a CNN: at each layer, the associated kernel acts as a transition kernel on the space of activations. The lateral kernels are defined in terms of the filters, thus providing a parameter-free approach to assess the geometry of horizontal connections based on the feedforward structure. We then test this new architecture, which we call KerCNN, on a generalization task related to global shape analysis and pattern completion: once trained for performing basic image classification, the network is evaluated on corrupted testing images. The image perturbations examined are designed to undermine the recognition of the images via local features, thus requiring an integration of context information - which in biological vision is critically linked to lateral connectivity. Our KerCNNs turn out to be far more stable than CNNs and recurrent CNNs to such degradations, thus validating this biologically inspired approach to reinforce object recognition under challenging conditions.