 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory learning in deep neural networks: Information content and geometry of internal representations
Oct 21, 2025In animals, category learning enhances discrimination between stimuli close to the category boundary. This phenomenon, called categorical perception, was also empirically observed in artificial neural networks trained on classification tasks. In previous modeling works based on neuroscience data, we show that this expansion/compression is a necessary outcome of efficient learning. Here we extend our theoretical framework to artificial networks. We show that minimizing the Bayes cost (mean of the cross-entropy loss) implies maximizing the mutual information between the set of categories and the neural activities prior to the decision layer. Considering structured data with an underlying feature space of small dimension, we show that maximizing the mutual information implies (i) finding an appropriate projection space, and, (ii) building a neural representation with the appropriate metric. The latter is based on a Fisher information matrix measuring the sensitivity of the neural activity to changes in the projection space. Optimal learning makes this neural Fisher information follow a category-specific Fisher information, measuring the sensitivity of the category membership. Category learning thus induces an expansion of neural space near decision boundaries. We characterize the properties of the categorical Fisher information, showing that its eigenvectors give the most discriminant directions at each point of the projection space. We find that, unexpectedly, its maxima are in general not exactly at, but near, the class boundaries. Considering toy models and the MNIST dataset, we numerically illustrate how after learning the two Fisher information matrices match, and essentially align with the category boundaries. Finally, we relate our approach to the Information Bottleneck one, and we exhibit a bias-variance decomposition of the Bayes cost, of interest on its own.
Uncovering Social Network Activity Using Joint User and Topic Interaction
Jun 15, 2025The emergence of online social platforms, such as social networks and social media, has drastically affected the way people apprehend the information flows to which they are exposed. In such platforms, various information cascades spreading among users is the main force creating complex dynamics of opinion formation, each user being characterized by their own behavior adoption mechanism. Moreover, the spread of multiple pieces of information or beliefs in a networked population is rarely uncorrelated. In this paper, we introduce the Mixture of Interacting Cascades (MIC), a model of marked multidimensional Hawkes processes with the capacity to model jointly non-trivial interaction between cascades and users. We emphasize on the interplay between information cascades and user activity, and use a mixture of temporal point processes to build a coupled user/cascade point process model. Experiments on synthetic and real data highlight the benefits of this approach and demonstrate that MIC achieves superior performance to existing methods in modeling the spread of information cascades. Finally, we demonstrate how MIC can provide, through its learned parameters, insightful bi-layered visualizations of real social network activity data.
Information theoretic study of the neural geometry induced by category learning
Nov 27, 2023

Categorization is an important topic both for biological and artificial neural networks. Here, we take an information theoretic approach to assess the efficiency of the representations induced by category learning. We show that one can decompose the relevant Bayesian cost into two components, one for the coding part and one for the decoding part. Minimizing the coding cost implies maximizing the mutual information between the set of categories and the neural activities. We analytically show that this mutual information can be written as the sum of two terms that can be interpreted as (i) finding an appropriate representation space, and, (ii) building a representation with the appropriate metrics, based on the neural Fisher information on this space. One main consequence is that category learning induces an expansion of neural space near decision boundaries. Finally, we provide numerical illustrations that show how Fisher information of the coding neural population aligns with the boundaries between categories.
Categorical Perception: A Groundwork for Deep Learning
Dec 10, 2020


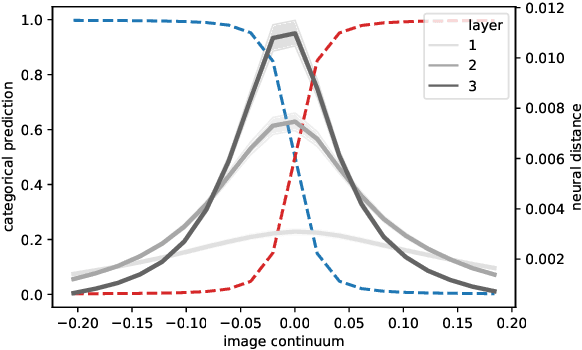
Classification is one of the major tasks that deep learning is successfully tackling. Categorization is also a fundamental cognitive ability. A well-known perceptual consequence of categorization in humans and other animals, called categorical perception, is characterized by a within-category compression and a between-category separation: two items, close in input space, are perceived closer if they belong to the same category than if they belong to different categories. Elaborating on experimental and theoretical results in cognitive science, here we study categorical effects in artificial neural networks. Our formal and numerical analysis provides insights into the geometry of the neural representation in deep layers, with expansion of space near category boundaries and contraction far from category boundaries. We investigate categorical representation by using two complementary approaches: one mimics experiments in psychophysics and cognitive neuroscience by means of morphed continua between stimuli of different categories, while the other introduces a categoricality index that quantifies the separability of the classes at the population level (a given layer in the neural network). We show on both shallow and deep neural networks that category learning automatically induces categorical perception. We further show that the deeper a layer, the stronger the categorical effects. An important outcome of our analysis is to provide a coherent and unifying view of the efficacy of different heuristic practices of the dropout regularization technique. Our views, which find echoes in the neuroscience literature, insist on the differential role of noise as a function of the level of representation and in the course of learning: noise injected in the hidden layers gets structured according to the organization of the categories, more variability being allowed within a category than across classes.
Frequency patterns of semantic change: Corpus-based evidence of a near-critical dynamics in language change
Nov 30, 2017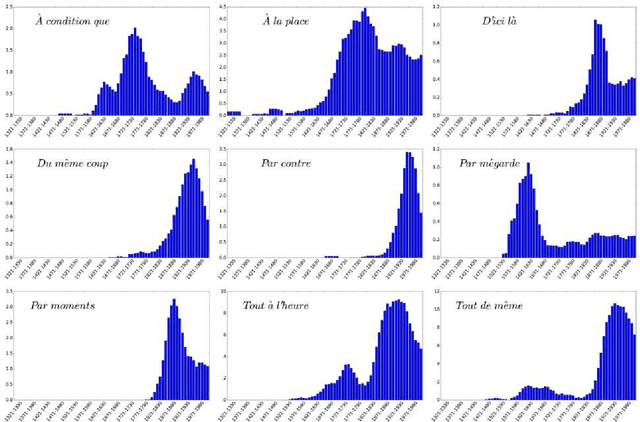
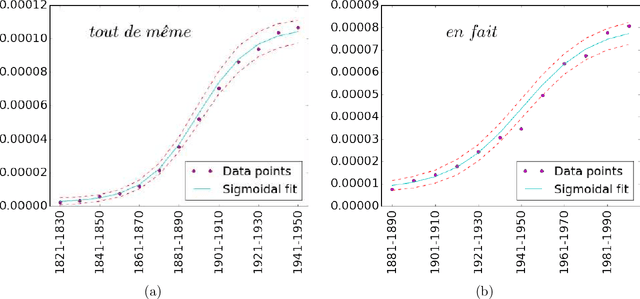
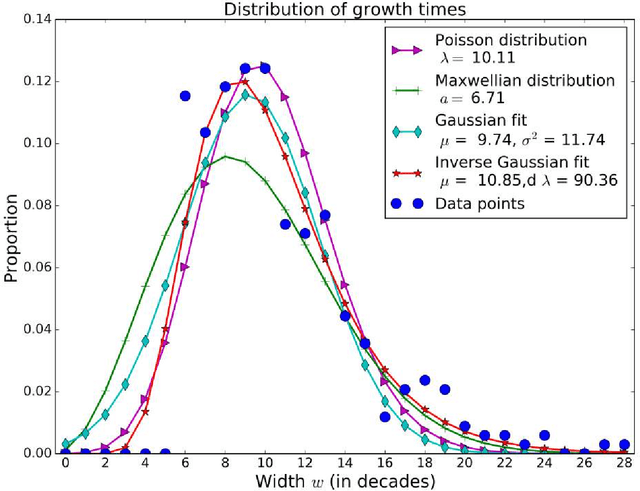

It is generally believed that, when a linguistic item acquires a new meaning, its overall frequency of use in the language rises with time with an S-shaped growth curve. Yet, this claim has only been supported by a limited number of case studies. In this paper, we provide the first corpus-based quantitative confirmation of the genericity of the S-curve in language change. Moreover, we uncover another generic pattern, a latency phase of variable duration preceding the S-growth, during which the frequency of use of the semantically expanding word remains low and more or less constant. We also propose a usage-based model of language change supported by cognitive considerations, which predicts that both phases, the latency and the fast S-growth, take place. The driving mechanism is a stochastic dynamics, a random walk in the space of frequency of use. The underlying deterministic dynamics highlights the role of a control parameter, the strength of the cognitive impetus governing the onset of change, which tunes the system at the vicinity of a saddle-node bifurcation. In the neighborhood of the critical point, the latency phase corresponds to the diffusion time over the critical region, and the S-growth to the fast convergence that follows. The duration of the two phases is computed as specific first passage times of the random walk process, leading to distributions that fit well the ones extracted from our dataset. We argue that our results are not specific to the studied corpus, but apply to semantic change in general.