 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Two Language Models Think Alike?
Paper and Code
Jun 24, 2024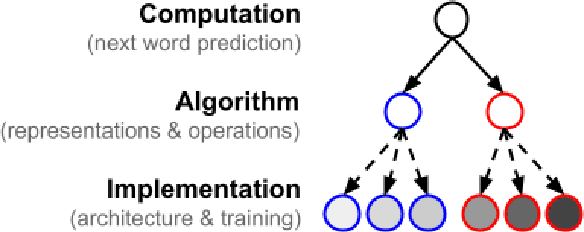



Do architectural differences significantly affect the way models represent and process language? We propose a new approach, based on metric-learning encoding models (MLEMs), as a first step to answer this question. The approach provides a feature-based comparison of how any two layers of any two models represent linguistic information. We apply the method to BERT, GPT-2 and Mamba. Unlike previous methods, MLEMs offer a transparent comparison, by identifying the specific linguistic features responsible for similarities and differences. More generally, the method uses formal, symbolic descriptions of a domain, and use these to compare neural representations. As such, the approach can straightforwardly be extended to other domains, such as speech and vision, and to other neural systems, including human brains.