 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric-Learning Encoding Models Identify Processing Profiles of Linguistic Features in BERT's Representations
Feb 18, 2024
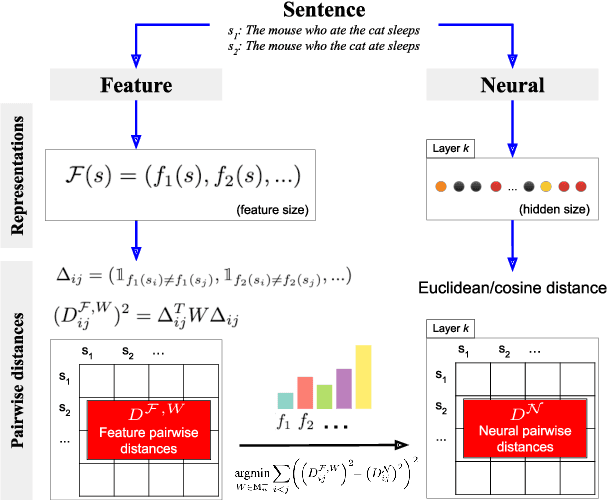
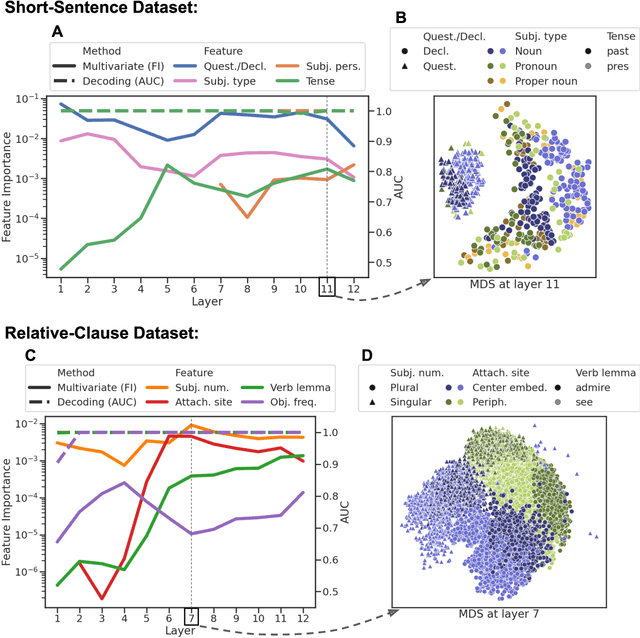
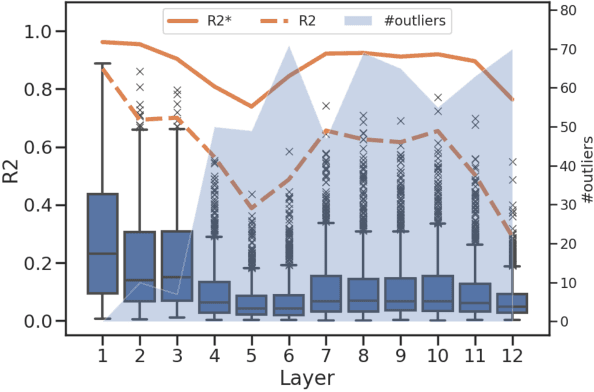
We introduce Metric-Learning Encoding Models (MLEMs) as a new approach to understand how neural systems represent the theoretical features of the objects they process. As a proof-of-concept, we apply MLEMs to neural representations extracted from BERT, and track a wide variety of linguistic features (e.g., tense, subject person, clause type, clause embedding). We find that: (1) linguistic features are ordered: they separate representations of sentences to different degrees in different layers; (2) neural representations are organized hierarchically: in some layers, we find clusters of representations nested within larger clusters, following successively important linguistic features; (3) linguistic features are disentangled in middle layers: distinct, selective units are activated by distinct linguistic features. Methodologically, MLEMs are superior (4) to multivariate decoding methods, being more robust to type-I errors, and (5) to univariate encoding methods, in being able to predict both local and distributed representations. Together, this demonstrates the utility of Metric-Learning Encoding Methods for studying how linguistic features are neurally encoded in language models and the advantage of MLEMs over traditional methods. MLEMs can be extended to other domains (e.g. vision) and to other neural systems, such as the human brain.