 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETROcode: Leveraging a Code Database for Improved Natural Language to Code Generation
Apr 09, 2025As text and code resources have expanded, large-scale pre-trained models have shown promising capabilities in code generation tasks, typically employing supervised fine-tuning with problem statement-program pairs. However, increasing model size and data volume for performance gains also raises computational demands and risks of overfitting. Addressing these challenges, we present RETROcode, a novel adaptation of the RETRO architecture \cite{RETRO} for sequence-to-sequence models, utilizing a large code database as an auxiliary scaling method. This approach, diverging from simply enlarging model and dataset sizes, allows RETROcode to leverage a vast code database for prediction, enhancing the model's efficiency by integrating extensive memory. Our findings indicate that RETROcode not only outperforms similar-sized traditional architectures on test sets but also approaches the effectiveness of the much larger Codex model, despite being trained from scratch on a substantially smaller dataset.
Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning
Feb 10, 2025



The ability to achieve long-term goals is a key challenge in the current development of large language models (LLMs). To address this, pre-trained LLMs can be fine-tuned with reinforcement learning (RL) to explore solutions that optimize a given goal. However, exploration with LLMs is difficult, as a balance has to be struck between discovering new solutions and staying close enough to the pre-trained model, so as not to degrade basic capabilities. This is typically controlled with a Kullback-Leibler (KL) penalty. In this paper, we investigate the exploration dynamics of a small language model on a simple arithmetic task. We show how varying degrees of pre-training influence exploration and demonstrate the importance of "critical tokens" which have a dramatic impact on the final outcome. Consequently, we introduce a simple modification to the KL penalty that favors exploration on critical tokens, increasing the efficiency of the RL fine-tuning stage.
CodeInsight: A Curated Dataset of Practical Coding Solutions from Stack Overflow
Sep 25, 2024



We introduce a novel dataset tailored for code generation, aimed at aiding developers in common tasks. Our dataset provides examples that include a clarified intent, code snippets associated, and an average of three related unit tests. It encompasses a range of libraries such as \texttt{Pandas}, \texttt{Numpy}, and \texttt{Regex}, along with more than 70 standard libraries in Python code derived from Stack Overflow. Comprising 3,409 crafted examples by Python experts, our dataset is designed for both model finetuning and standalone evaluation. To complete unit tests evaluation, we categorize examples in order to get more fine grained analysis, enhancing the understanding of models' strengths and weaknesses in specific coding tasks. The examples have been refined to reduce data contamination, a process confirmed by the performance of three leading models: Mistral 7B, CodeLLaMa 13B, and Starcoder 15B. We further investigate data-contamination testing GPT-4 performance on a part of our dataset. The benchmark can be accessed at \url{https://github.com/NathanaelBeau/CodeInsight}.
The impact of lexical and grammatical processing on generating code from natural language
Mar 16, 2022
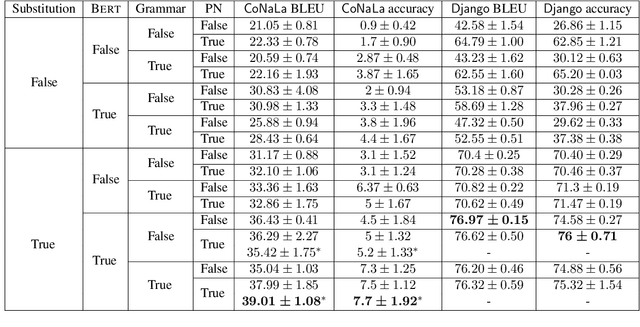

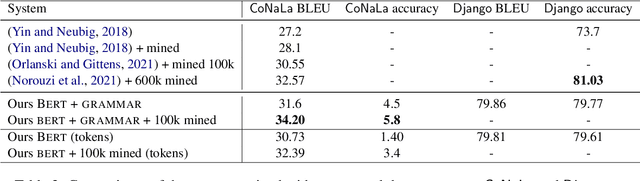
Considering the seq2seq architecture of TranX for natural language to code translation, we identify four key components of importance: grammatical constraints, lexical preprocessing, input representations, and copy mechanisms. To study the impact of these components, we use a state-of-the-art architecture that relies on BERT encoder and a grammar-based decoder for which a formalization is provided. The paper highlights the importance of the lexical substitution component in the current natural language to code systems.