 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Conditional Language Models with Distributional Policy Gradients
Dec 01, 2021
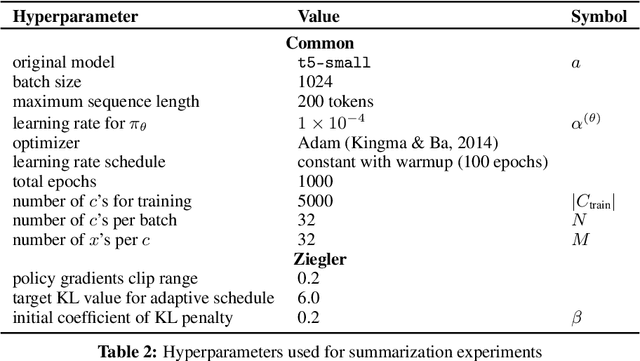
Machine learning is shifting towards general-purpose pretrained generative models, trained in a self-supervised manner on large amounts of data, which can then be applied to solve a large number of tasks. However, due to their generic training methodology, these models often fail to meet some of the downstream requirements (e.g. hallucination in abstractive summarization or wrong format in automatic code generation). This raises an important question on how to adapt pre-trained generative models to a new task without destroying its capabilities. Recent work has suggested to solve this problem by representing task-specific requirements through energy-based models (EBMs) and approximating these EBMs using distributional policy gradients (DPG). Unfortunately, this approach is limited to unconditional distributions, represented by unconditional EBMs. In this paper, we extend this approach to conditional tasks by proposing Conditional DPG (CDPG). We evaluate CDPG on three different control objectives across two tasks: summarization with T5 and code generation with GPT-Neo. Our results show that fine-tuning using CDPG robustly moves these pretrained models closer towards meeting control objectives and -- in contrast with baseline approaches -- does not result in catastrophic forgetting.
The emergence of number and syntax units in LSTM language models
Apr 02, 2019
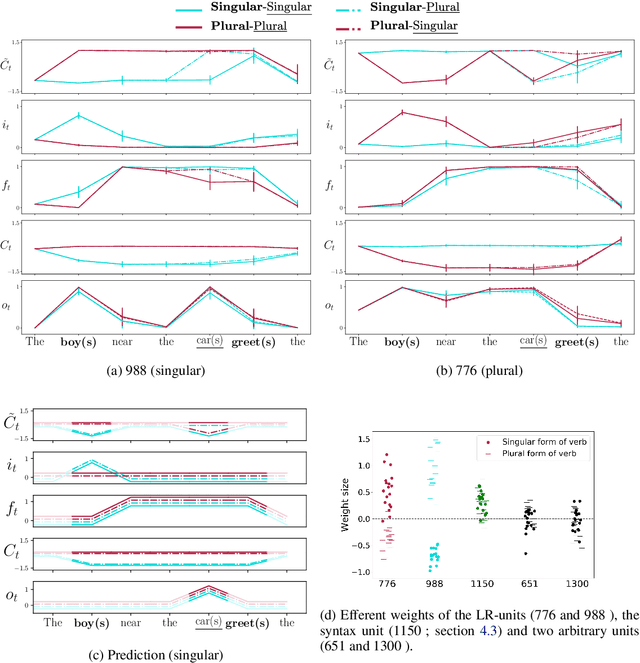
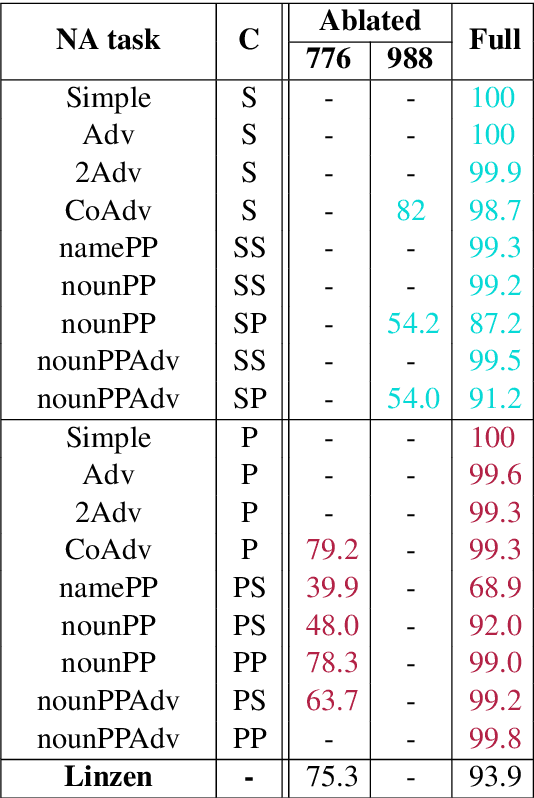
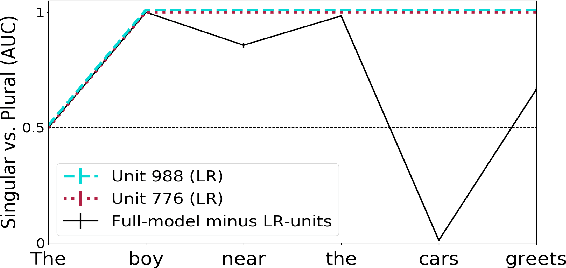
Recent work has shown that LSTMs trained on a generic language modeling objective capture syntax-sensitive generalizations such as long-distance number agreement. We have however no mechanistic understanding of how they accomplish this remarkable feat. Some have conjectured it depends on heuristics that do not truly take hierarchical structure into account. We present here a detailed study of the inner mechanics of number tracking in LSTMs at the single neuron level. We discover that long-distance number information is largely managed by two `number units'. Importantly, the behaviour of these units is partially controlled by other units independently shown to track syntactic structure. We conclude that LSTMs are, to some extent, implementing genuinely syntactic processing mechanisms, paving the way to a more general understanding of grammatical encoding in LSTMs.
Learning compositionally through attentive guidance
Sep 10, 2018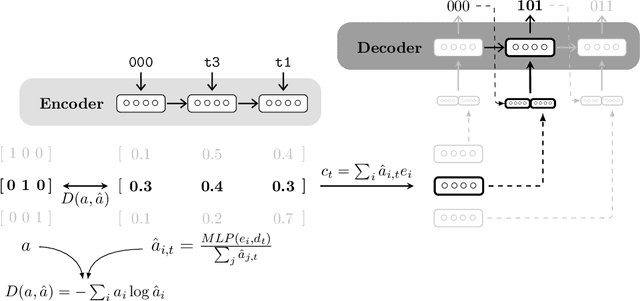

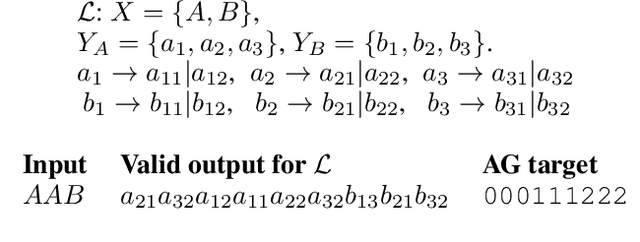
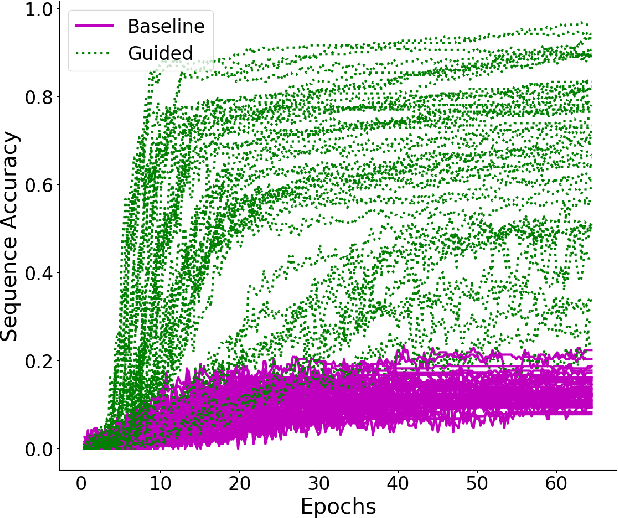
While neural network models have been successfully applied to domains that require substantial generalisation skills, recent studies have implied that they struggle when solving the task they are trained on requires inferring its underlying compositional structure. In this paper, we introduce Attentive Guidance, a mechanism to direct a sequence to sequence model equipped with attention to find more compositional solutions. We test it on two tasks, devised precisely to assess the compositional capabilities of neural models, and we show that vanilla sequence to sequence models with attention overfit the training distribution, while the guided versions come up with compositional solutions that fit the training and testing distributions almost equally well. Moreover, the learned solutions generalise even in cases where the training and testing distributions strongly diverge. In this way, we demonstrate that sequence to sequence models are capable of finding compositional solutions without requiring extra components. These results helps to disentangle the causes for the lack of systematic compositionality in neural networks, which can in turn fuel future work.
What you can cram into a single vector: Probing sentence embeddings for linguistic properties
Jul 08, 2018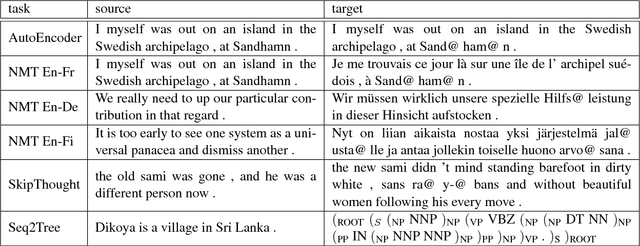
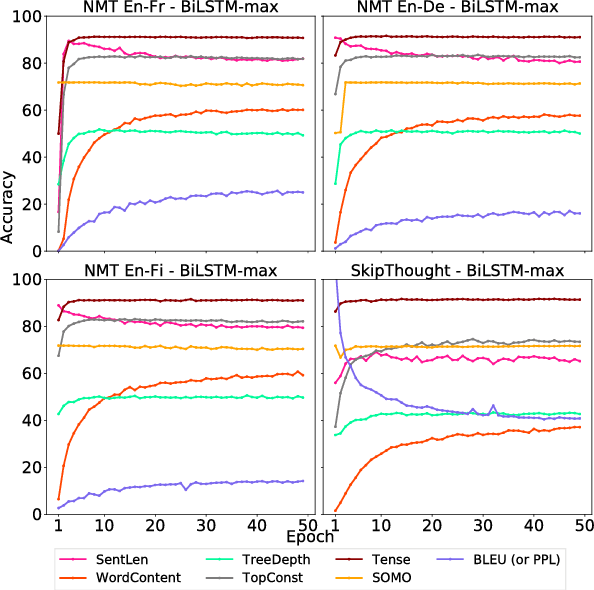
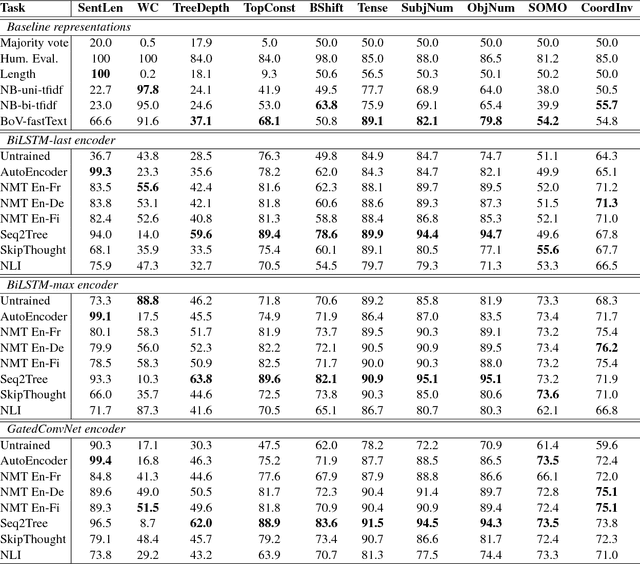
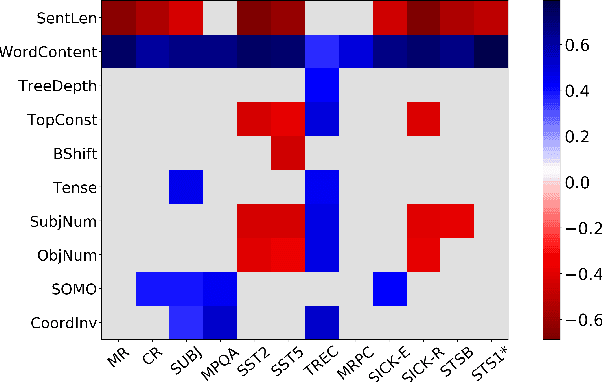
Although much effort has recently been devoted to training high-quality sentence embeddings, we still have a poor understanding of what they are capturing. "Downstream" tasks, often based on sentence classification, are commonly used to evaluate the quality of sentence representations. The complexity of the tasks makes it however difficult to infer what kind of information is present in the representations. We introduce here 10 probing tasks designed to capture simple linguistic features of sentences, and we use them to study embeddings generated by three different encoders trained in eight distinct ways, uncovering intriguing properties of both encoders and training methods.