 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscoding compositionally: using attention to find more generalizable solutions
Jun 06, 2019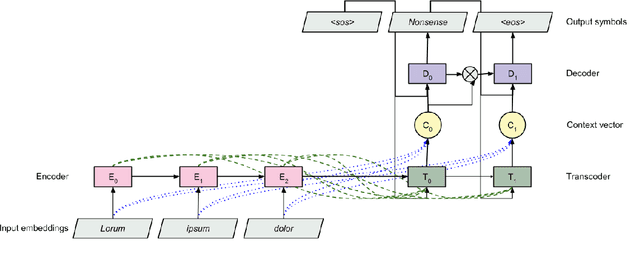
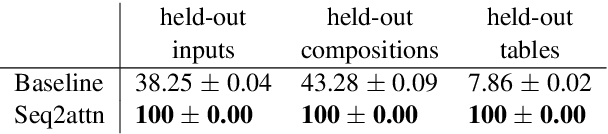


While sequence-to-sequence models have shown remarkable generalization power across several natural language tasks, their construct of solutions are argued to be less compositional than human-like generalization. In this paper, we present seq2attn, a new architecture that is specifically designed to exploit attention to find compositional patterns in the input. In seq2attn, the two standard components of an encoder-decoder model are connected via a transcoder, that modulates the information flow between them. We show that seq2attn can successfully generalize, without requiring any additional supervision, on two tasks which are specifically constructed to challenge the compositional skills of neural networks. The solutions found by the model are highly interpretable, allowing easy analysis of both the types of solutions that are found and potential causes for mistakes. We exploit this opportunity to introduce a new paradigm to test compositionality that studies the extent to which a model overgeneralizes when confronted with exceptions. We show that seq2attn exhibits such overgeneralization to a larger degree than a standard sequence-to-sequence model.
Learning compositionally through attentive guidance
Sep 10, 2018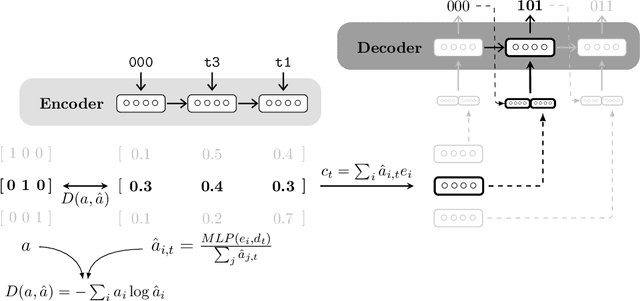

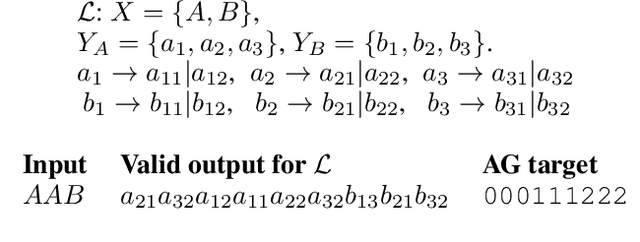
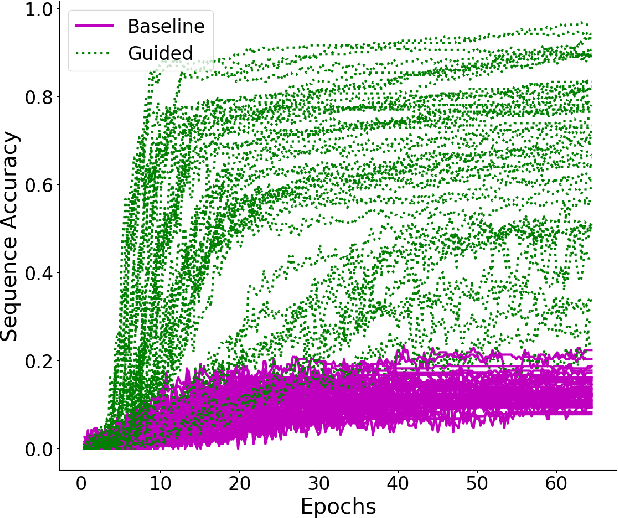
While neural network models have been successfully applied to domains that require substantial generalisation skills, recent studies have implied that they struggle when solving the task they are trained on requires inferring its underlying compositional structure. In this paper, we introduce Attentive Guidance, a mechanism to direct a sequence to sequence model equipped with attention to find more compositional solutions. We test it on two tasks, devised precisely to assess the compositional capabilities of neural models, and we show that vanilla sequence to sequence models with attention overfit the training distribution, while the guided versions come up with compositional solutions that fit the training and testing distributions almost equally well. Moreover, the learned solutions generalise even in cases where the training and testing distributions strongly diverge. In this way, we demonstrate that sequence to sequence models are capable of finding compositional solutions without requiring extra components. These results helps to disentangle the causes for the lack of systematic compositionality in neural networks, which can in turn fuel future work.