 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Manipulation Using Multi-Task Reinforcement Learning
Mar 25, 2026This paper introduces Knowledge Graph based Massively Multi-task Model-based Policy Optimization (KG-M3PO), a framework for multi-task robotic manipulation in partially observable settings that unifies Perception, Knowledge, and Policy. The method augments egocentric vision with an online 3D scene graph that grounds open-vocabulary detections into a metric, relational representation. A dynamic-relation mechanism updates spatial, containment, and affordance edges at every step, and a graph neural encoder is trained end-to-end through the RL objective so that relational features are shaped directly by control performance. Multiple observation modalities (visual, proprioceptive, linguistic, and graph-based) are encoded into a shared latent space, upon which the RL agent operates to drive the control loop. The policy conditions on lightweight graph queries alongside visual and proprioceptive inputs, yielding a compact, semantically informed state for decision making. Experiments on a suite of manipulation tasks with occlusions, distractors, and layout shifts demonstrate consistent gains over strong baselines: the knowledge-conditioned agent achieves higher success rates, improved sample efficiency, and stronger generalization to novel objects and unseen scene configurations. These results support the premise that structured, continuously maintained world knowledge is a powerful inductive bias for scalable, generalizable manipulation: when the knowledge module participates in the RL computation graph, relational representations align with control, enabling robust long-horizon behavior under partial observability.
FocusGraph: Graph-Structured Frame Selection for Embodied Long Video Question Answering
Mar 04, 2026The ability to understand long videos is vital for embodied intelligent agents, because their effectiveness depends on how well they can accumulate, organize, and leverage long-horizon perceptual memories. Recently, multimodal LLMs have been gaining popularity for solving the long video understanding task due to their general ability to understand natural language and to leverage world knowledge. However, as the number of frames provided to an MLLM increases, the quality of its responses tends to degrade, and inference time grows. Therefore, when using MLLMs for long video understanding, a crucial step is selecting key frames from the video to answer user queries. In this work, we develop FocusGraph, a framework for keyframe selection for question answering over long egocentric videos. It leverages a lightweight trainable Scene-Caption LLM Selector that selects query-relevant clips based on their graph-based captions, and a training-free method for selecting keyframes from these clips. Unlike existing methods, the proposed Scene-Caption LLM Selector does not rely on the original sequence of low-resolution frames; instead, it operates on a compact textual representation of the scene. We then design a training-free Patch-wise Sparse-Flow Retention (PSFR) method to select keyframes from the resulting sequence of clips, which are fed into an MLLM to produce the final answer. Together, these components enable FocusGraph to achieve state-of-the-art results on challenging egocentric long-video question answering benchmarks, including FindingDory and HourVideo, while significantly reducing inference time relative to baseline approaches.
M3DMap: Object-aware Multimodal 3D Mapping for Dynamic Environments
Aug 23, 20253D mapping in dynamic environments poses a challenge for modern researchers in robotics and autonomous transportation. There are no universal representations for dynamic 3D scenes that incorporate multimodal data such as images, point clouds, and text. This article takes a step toward solving this problem. It proposes a taxonomy of methods for constructing multimodal 3D maps, classifying contemporary approaches based on scene types and representations, learning methods, and practical applications. Using this taxonomy, a brief structured analysis of recent methods is provided. The article also describes an original modular method called M3DMap, designed for object-aware construction of multimodal 3D maps for both static and dynamic scenes. It consists of several interconnected components: a neural multimodal object segmentation and tracking module; an odometry estimation module, including trainable algorithms; a module for 3D map construction and updating with various implementations depending on the desired scene representation; and a multimodal data retrieval module. The article highlights original implementations of these modules and their advantages in solving various practical tasks, from 3D object grounding to mobile manipulation. Additionally, it presents theoretical propositions demonstrating the positive effect of using multimodal data and modern foundational models in 3D mapping methods. Details of the taxonomy and method implementation are available at https://yuddim.github.io/M3DMap.
MapFM: Foundation Model-Driven HD Mapping with Multi-Task Contextual Learning
Jun 18, 2025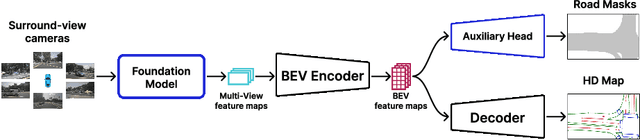
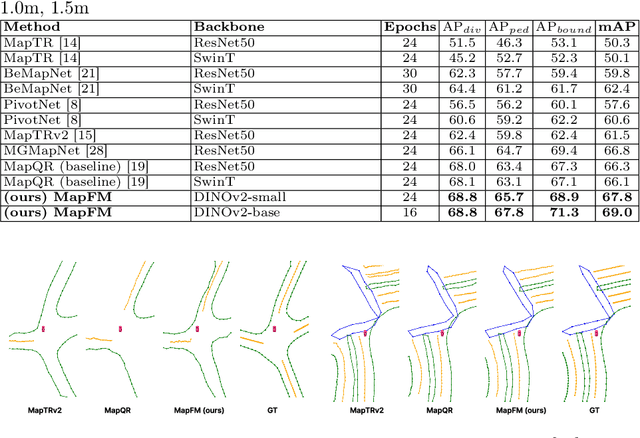
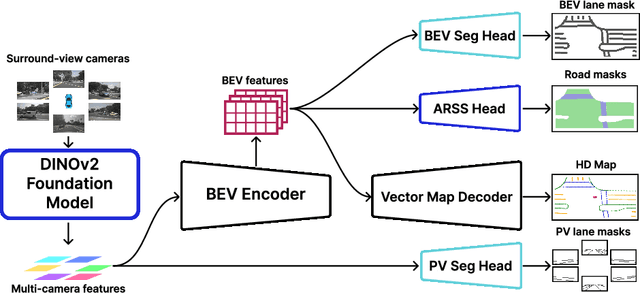

In autonomous driving, high-definition (HD) maps and semantic maps in bird's-eye view (BEV) are essential for accurate localization, planning, and decision-making. This paper introduces an enhanced End-to-End model named MapFM for online vectorized HD map generation. We show significantly boost feature representation quality by incorporating powerful foundation model for encoding camera images. To further enrich the model's understanding of the environment and improve prediction quality, we integrate auxiliary prediction heads for semantic segmentation in the BEV representation. This multi-task learning approach provides richer contextual supervision, leading to a more comprehensive scene representation and ultimately resulting in higher accuracy and improved quality of the predicted vectorized HD maps. The source code is available at https://github.com/LIvanoff/MapFM.
SGN-CIRL: Scene Graph-based Navigation with Curriculum, Imitation, and Reinforcement Learning
Jun 04, 2025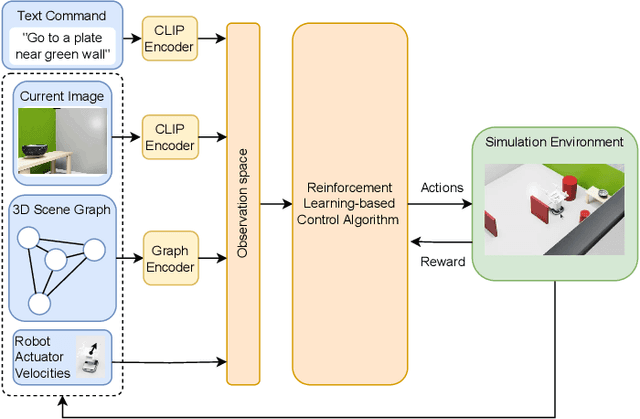
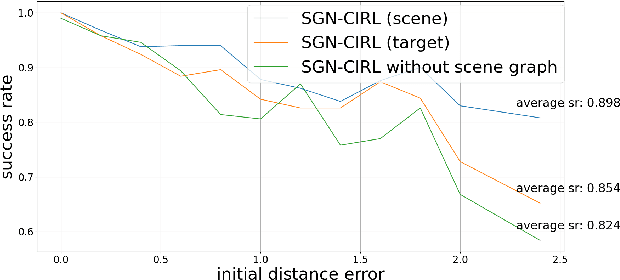

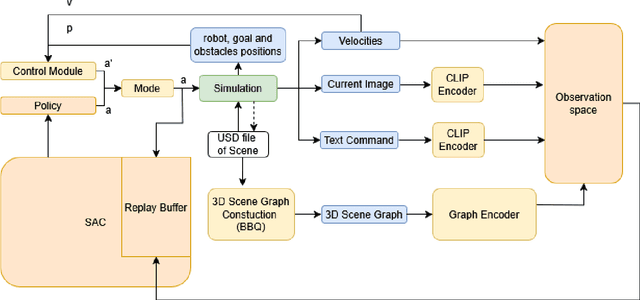
The 3D scene graph models spatial relationships between objects, enabling the agent to efficiently navigate in a partially observable environment and predict the location of the target object.This paper proposes an original framework named SGN-CIRL (3D Scene Graph-Based Reinforcement Learning Navigation) for mapless reinforcement learning-based robot navigation with learnable representation of open-vocabulary 3D scene graph. To accelerate and stabilize the training of reinforcement learning-based algorithms, the framework also employs imitation learning and curriculum learning. The first one enables the agent to learn from demonstrations, while the second one structures the training process by gradually increasing task complexity from simple to more advanced scenarios. Numerical experiments conducted in the Isaac Sim environment showed that using a 3D scene graph for reinforcement learning significantly increased the success rate in difficult navigation cases. The code is open-sourced and available at: https://github.com/Xisonik/Aloha\_graph.
DyGEnc: Encoding a Sequence of Textual Scene Graphs to Reason and Answer Questions in Dynamic Scenes
May 06, 2025The analysis of events in dynamic environments poses a fundamental challenge in the development of intelligent agents and robots capable of interacting with humans. Current approaches predominantly utilize visual models. However, these methods often capture information implicitly from images, lacking interpretable spatial-temporal object representations. To address this issue we introduce DyGEnc - a novel method for Encoding a Dynamic Graph. This method integrates compressed spatial-temporal structural observation representation with the cognitive capabilities of large language models. The purpose of this integration is to enable advanced question answering based on a sequence of textual scene graphs. Extended evaluations on the STAR and AGQA datasets indicate that DyGEnc outperforms existing visual methods by a large margin of 15-25% in addressing queries regarding the history of human-to-object interactions. Furthermore, the proposed method can be seamlessly extended to process raw input images utilizing foundational models for extracting explicit textual scene graphs, as substantiated by the results of a robotic experiment conducted with a wheeled manipulator platform. We hope that these findings will contribute to the implementation of robust and compressed graph-based robotic memory for long-horizon reasoning. Code is available at github.com/linukc/DyGEnc.
3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding
Dec 24, 2024A 3D scene graph represents a compact scene model, storing information about the objects and the semantic relationships between them, making its use promising for robotic tasks. When interacting with a user, an embodied intelligent agent should be capable of responding to various queries about the scene formulated in natural language. Large Language Models (LLMs) are beneficial solutions for user-robot interaction due to their natural language understanding and reasoning abilities. Recent methods for creating learnable representations of 3D scenes have demonstrated the potential to improve the quality of LLMs responses by adapting to the 3D world. However, the existing methods do not explicitly utilize information about the semantic relationships between objects, limiting themselves to information about their coordinates. In this work, we propose a method 3DGraphLLM for constructing a learnable representation of a 3D scene graph. The learnable representation is used as input for LLMs to perform 3D vision-language tasks. In our experiments on popular ScanRefer, RIORefer, Multi3DRefer, ScanQA, Sqa3D, and Scan2cap datasets, we demonstrate the advantage of this approach over baseline methods that do not use information about the semantic relationships between objects. The code is publicly available at https://github.com/CognitiveAISystems/3DGraphLLM.
MSSPlace: Multi-Sensor Place Recognition with Visual and Text Semantics
Jul 22, 2024



Place recognition is a challenging task in computer vision, crucial for enabling autonomous vehicles and robots to navigate previously visited environments. While significant progress has been made in learnable multimodal methods that combine onboard camera images and LiDAR point clouds, the full potential of these methods remains largely unexplored in localization applications. In this paper, we study the impact of leveraging a multi-camera setup and integrating diverse data sources for multimodal place recognition, incorporating explicit visual semantics and text descriptions. Our proposed method named MSSPlace utilizes images from multiple cameras, LiDAR point clouds, semantic segmentation masks, and text annotations to generate comprehensive place descriptors. We employ a late fusion approach to integrate these modalities, providing a unified representation. Through extensive experiments on the Oxford RobotCar and NCLT datasets, we systematically analyze the impact of each data source on the overall quality of place descriptors. Our experiments demonstrate that combining data from multiple sensors significantly improves place recognition model performance compared to single modality approaches and leads to state-of-the-art quality. We also show that separate usage of visual or textual semantics (which are more compact representations of sensory data) can achieve promising results in place recognition. The code for our method is publicly available: https://github.com/alexmelekhin/MSSPlace
Beyond Bare Queries: Open-Vocabulary Object Retrieval with 3D Scene Graph
Jun 11, 2024



Locating objects referred to in natural language poses a significant challenge for autonomous agents. Existing CLIP-based open-vocabulary methods successfully perform 3D object retrieval with simple (bare) queries but cannot cope with ambiguous descriptions that demand an understanding of object relations. To tackle this problem, we propose a modular approach called BBQ (Beyond Bare Queries), which constructs 3D scene spatial graph representation with metric edges and utilizes a large language model as a human-to-agent interface through our deductive scene reasoning algorithm. BBQ employs robust DINO-powered associations to form 3D objects, an advanced raycasting algorithm to project them to 2D, and a vision-language model to describe them as graph nodes. On Replica and ScanNet datasets, we show that the designed method accurately constructs 3D object-centric maps. We have demonstrated that their quality takes a leading place for open-vocabulary 3D semantic segmentation against other zero-shot methods. Also, we show that leveraging spatial relations is especially effective for scenes containing multiple entities of the same semantic class. On Sr3D and Nr3D benchmarks, our deductive approach demonstrates a significant improvement, enabling retrieving objects by complex queries compared to other state-of-the-art methods. Considering our design solutions, we achieved a processing speed approximately x3 times faster than the closest analog. This promising performance enables our approach for usage in applied intelligent robotics projects. We make the code publicly available at linukc.github.io/bbq/.
OFMPNet: Deep End-to-End Model for Occupancy and Flow Prediction in Urban Environment
Apr 02, 2024The task of motion prediction is pivotal for autonomous driving systems, providing crucial data to choose a vehicle behavior strategy within its surroundings. Existing motion prediction techniques primarily focus on predicting the future trajectory of each agent in the scene individually, utilizing its past trajectory data. In this paper, we introduce an end-to-end neural network methodology designed to predict the future behaviors of all dynamic objects in the environment. This approach leverages the occupancy map and the scene's motion flow. We are investigatin various alternatives for constructing a deep encoder-decoder model called OFMPNet. This model uses a sequence of bird's-eye-view road images, occupancy grid, and prior motion flow as input data. The encoder of the model can incorporate transformer, attention-based, or convolutional units. The decoder considers the use of both convolutional modules and recurrent blocks. Additionally, we propose a novel time-weighted motion flow loss, whose application has shown a substantial decrease in end-point error. Our approach has achieved state-of-the-art results on the Waymo Occupancy and Flow Prediction benchmark, with a Soft IoU of 52.1% and an AUC of 76.75% on Flow-Grounded Occupancy.