 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Policy Exploration Improvement via Subgoals
Aug 25, 2024Reinforcement learning is a widely used approach to autonomous navigation, showing potential in various tasks and robotic setups. Still, it often struggles to reach distant goals when safety constraints are imposed (e.g., the wheeled robot is prohibited from moving close to the obstacles). One of the main reasons for poor performance in such setups, which is common in practice, is that the need to respect the safety constraints degrades the exploration capabilities of an RL agent. To this end, we introduce a novel learnable algorithm that is based on decomposing the initial problem into smaller sub-problems via intermediate goals, on the one hand, and respects the limit of the cumulative safety constraints, on the other hand -- SPEIS(Safe Policy Exploration Improvement via Subgoals). It comprises the two coupled policies trained end-to-end: subgoal and safe. The subgoal policy is trained to generate the subgoal based on the transitions from the buffer of the safe (main) policy that helps the safe policy to reach distant goals. Simultaneously, the safe policy maximizes its rewards while attempting not to violate the limit of the cumulative safety constraints, thus providing a certain level of safety. We evaluate SPEIS in a wide range of challenging (simulated) environments that involve different types of robots in two different environments: autonomous vehicles from the POLAMP environment and car, point, doggo, and sweep from the safety-gym environment. We demonstrate that our method consistently outperforms state-of-the-art competitors and can significantly reduce the collision rate while maintaining high success rates (higher by 80% compared to the best-performing methods).
Evaluation of Safety Constraints in Autonomous Navigation with Deep Reinforcement Learning
Jul 27, 2023

While reinforcement learning algorithms have had great success in the field of autonomous navigation, they cannot be straightforwardly applied to the real autonomous systems without considering the safety constraints. The later are crucial to avoid unsafe behaviors of the autonomous vehicle on the road. To highlight the importance of these constraints, in this study, we compare two learnable navigation policies: safe and unsafe. The safe policy takes the constraints into account, while the other does not. We show that the safe policy is able to generate trajectories with more clearance (distance to the obstacles) and makes less collisions while training without sacrificing the overall performance.
Policy Optimization to Learn Adaptive Motion Primitives in Path Planning with Dynamic Obstacles
Dec 29, 2022



This paper addresses the kinodynamic motion planning for non-holonomic robots in dynamic environments with both static and dynamic obstacles -- a challenging problem that lacks a universal solution yet. One of the promising approaches to solve it is decomposing the problem into the smaller sub problems and combining the local solutions into the global one. The crux of any planning method for non-holonomic robots is the generation of motion primitives that generates solutions to local planning sub-problems. In this work we introduce a novel learnable steering function (policy), which takes into account kinodynamic constraints of the robot and both static and dynamic obstacles. This policy is efficiently trained via the policy optimization. Empirically, we show that our steering function generalizes well to unseen problems. We then plug in the trained policy into the sampling-based and lattice-based planners, and evaluate the resultant POLAMP algorithm (Policy Optimization that Learns Adaptive Motion Primitives) in a range of challenging setups that involve a car-like robot operating in the obstacle-rich parking-lot environments. We show that POLAMP is able to plan collision-free kinodynamic trajectories with success rates higher than 92%, when 50 simultaneously moving obstacles populate the environment showing better performance than the state-of-the-art competitors.
Augmenting GRIPS with Heuristic Sampling for Planning Feasible Trajectories of a Car-Like Robot
Aug 15, 2021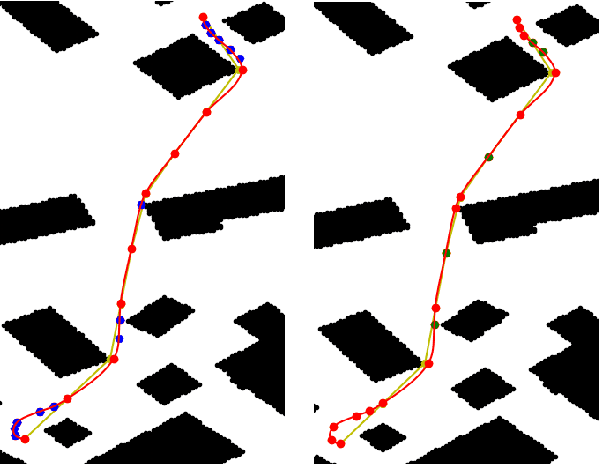
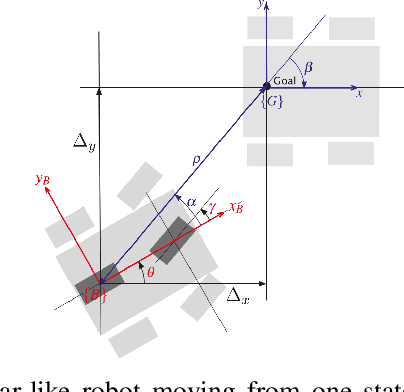
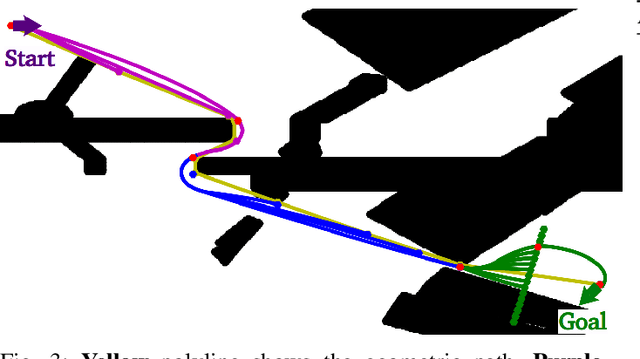
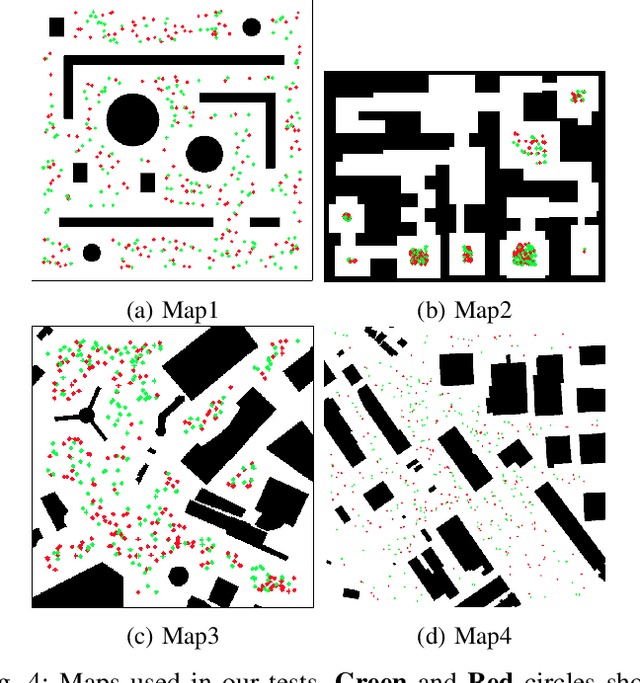
Kinodynamic motion planning for non-holomonic mobile robots is a challenging problem that is lacking a universal solution. One of the computationally efficient ways to solve it is to build a geometric path first and then transform this path into a kinematically feasible one. Gradient-informed Path Smoothing (GRIPS) is a recently introduced method for such transformation. GRIPS iteratively deforms the path and adds/deletes the waypoints while trying to connect each consecutive pair of them via the provided steering function that respects the kinematic constraints. The algorithm is relatively fast but, unfortunately, does not provide any guarantees that it will succeed. In practice, it often fails to produce feasible trajectories for car-like robots with large turning radius. In this work, we introduce a range of modifications that are aimed at increasing the success rate of GRIPS for car-like robots. The main enhancement is adding the additional step that heuristically samples waypoints along the bottleneck parts of the geometric paths (such as sharp turns). The results of the experimental evaluation provide a clear evidence that the success rate of the suggested algorithm is up to 40% higher compared to the original GRIPS and hits the bar of 90%, while its runtime is lower.