 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Potential Field: Online Trajectory Optimization in Presence of Moving Obstacles
Oct 09, 2024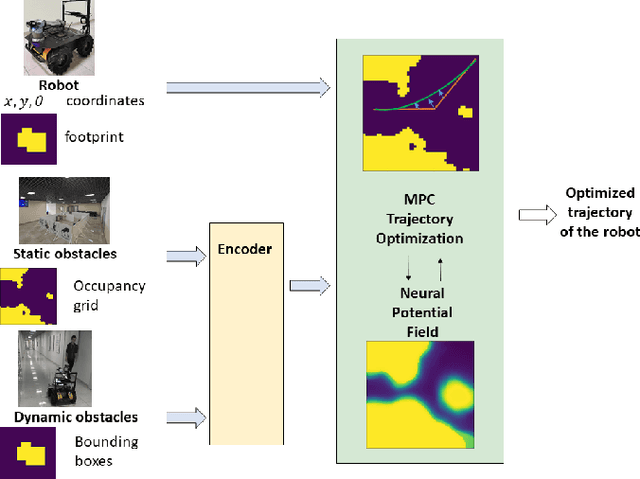
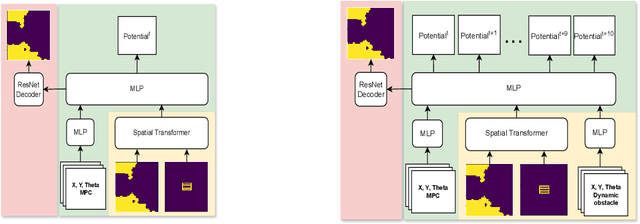
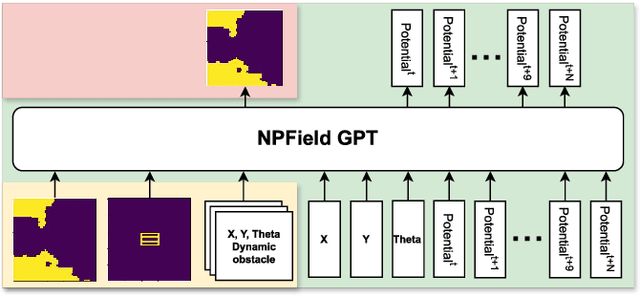
We address a task of local trajectory planning for the mobile robot in the presence of static and dynamic obstacles. Local trajectory is obtained as a numerical solution of the Model Predictive Control (MPC) problem. Collision avoidance may be provided by adding repulsive potential of the obstacles to the cost function of MPC. We develop an approach, where repulsive potential is estimated by the neural model. We propose and explore three possible strategies of handling dynamic obstacles. First, environment with dynamic obstacles is considered as a sequence of static environments. Second, the neural model predict a sequence of repulsive potential at once. Third, the neural model predict future repulsive potential step by step in autoregressive mode. We implement these strategies and compare it with CIAO* and MPPI using BenchMR framework. First two strategies showed higher performance than CIAO* and MPPI while preserving safety constraints. The third strategy was a bit slower, however it still satisfy time limits. We deploy our approach on Husky UGV mobile platform, which move through the office corridors under proposed MPC local trajectory planner. The code and trained models are available at \url{https://github.com/CognitiveAISystems/Dynamic-Neural-Potential-Field}.
Neural Potential Field for Obstacle-Aware Local Motion Planning
Oct 25, 2023



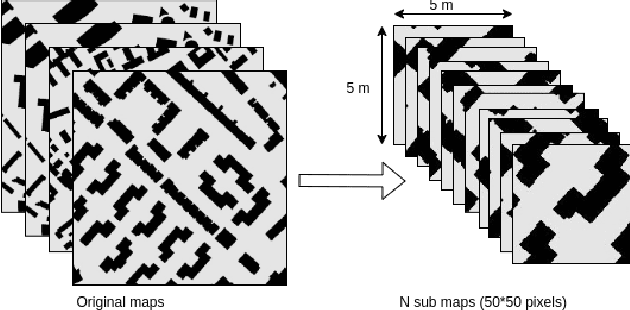
Model predictive control (MPC) may provide local motion planning for mobile robotic platforms. The challenging aspect is the analytic representation of collision cost for the case when both the obstacle map and robot footprint are arbitrary. We propose a Neural Potential Field: a neural network model that returns a differentiable collision cost based on robot pose, obstacle map, and robot footprint. The differentiability of our model allows its usage within the MPC solver. It is computationally hard to solve problems with a very high number of parameters. Therefore, our architecture includes neural image encoders, which transform obstacle maps and robot footprints into embeddings, which reduce problem dimensionality by two orders of magnitude. The reference data for network training are generated based on algorithmic calculation of a signed distance function. Comparative experiments showed that the proposed approach is comparable with existing local planners: it provides trajectories with outperforming smoothness, comparable path length, and safe distance from obstacles. Experiment on Husky UGV mobile robot showed that our approach allows real-time and safe local planning. The code for our approach is presented at https://github.com/cog-isa/NPField together with demo video.
Landmark Policy Optimization for Object Navigation Task
Sep 17, 2021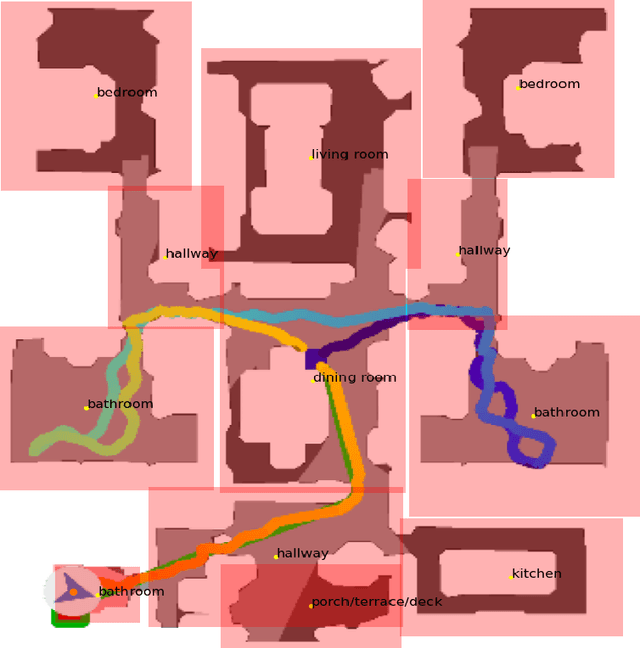
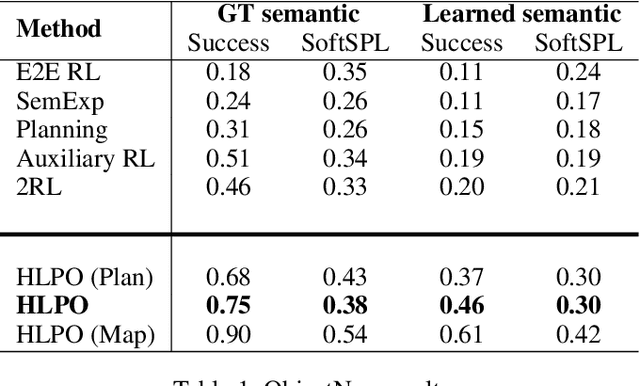


This work studies object goal navigation task, which involves navigating to the closest object related to the given semantic category in unseen environments. Recent works have shown significant achievements both in the end-to-end Reinforcement Learning approach and modular systems, but need a big step forward to be robust and optimal. We propose a hierarchical method that incorporates standard task formulation and additional area knowledge as landmarks, with a way to extract these landmarks. In a hierarchy, a low level consists of separately trained algorithms to the most intuitive skills, and a high level decides which skill is needed at this moment. With all proposed solutions, we achieve a 0.75 success rate in a realistic Habitat simulator. After a small stage of additional model training in a reconstructed virtual area at a simulator, we successfully confirmed our results in a real-world case.
Forgetful Experience Replay in Hierarchical Reinforcement Learning from Demonstrations
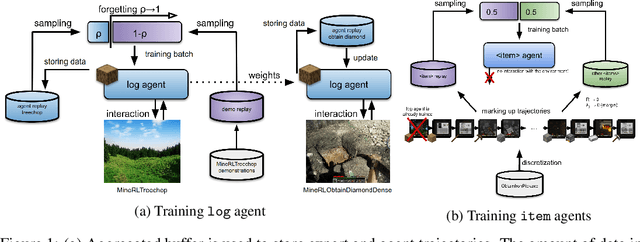
Jun 17, 2020Currently, deep reinforcement learning (RL) shows impressive results in complex gaming and robotic environments. Often these results are achieved at the expense of huge computational costs and require an incredible number of episodes of interaction between the agent and the environment. There are two main approaches to improving the sample efficiency of reinforcement learning methods - using hierarchical methods and expert demonstrations. In this paper, we propose a combination of these approaches that allow the agent to use low-quality demonstrations in complex vision-based environments with multiple related goals. Our forgetful experience replay (ForgER) algorithm effectively handles errors in expert data and reduces quality losses when adapting the action space and states representation to the agent's capabilities. Our proposed goal-oriented structuring of replay buffer allows the agent to automatically highlight sub-goals for solving complex hierarchical tasks in demonstrations. Our method is universal and can be integrated into various off-policy methods. It surpasses all known existing state-of-the-art RL methods using expert demonstrations on various model environments. The solution based on our algorithm beats all the solutions for the famous MineRL competition and allows the agent to mine a diamond in the Minecraft environment.
Hierarchical Deep Q-Network from Imperfect Demonstrations in Minecraft
Feb 10, 2020

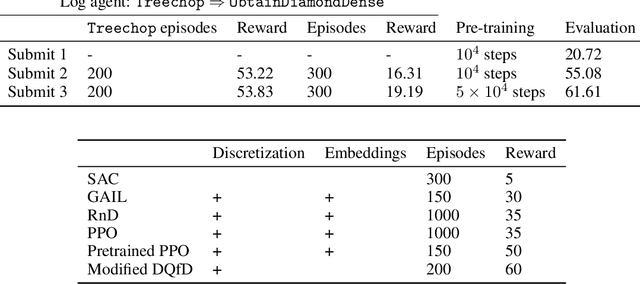
We present hierarchical Deep Q-Network with Forgetting (HDQF) that took first place in MineRL competition. HDQF works on imperfect demonstrations utilize hierarchical structure of expert trajectories extracting effective sequence of meta-actions and subgoals. We introduce structured task dependent replay buffer and forgetting technique that allow the HDQF agent to gradually erase poor-quality expert data from the buffer. In this paper we present the details of the HDQF algorithm and give the experimental results in Minecraft domain.