 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten text generation and strikethrough characters augmentation
Dec 14, 2021

We introduce two data augmentation techniques, which, used with a Resnet-BiLSTM-CTC network, significantly reduce Word Error Rate (WER) and Character Error Rate (CER) beyond best-reported results on handwriting text recognition (HTR) tasks. We apply a novel augmentation that simulates strikethrough text (HandWritten Blots) and a handwritten text generation method based on printed text (StackMix), which proved to be very effective in HTR tasks. StackMix uses weakly-supervised framework to get character boundaries. Because these data augmentation techniques are independent of the network used, they could also be applied to enhance the performance of other networks and approaches to HTR. Extensive experiments on ten handwritten text datasets show that HandWritten Blots augmentation and StackMix significantly improve the quality of HTR models
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021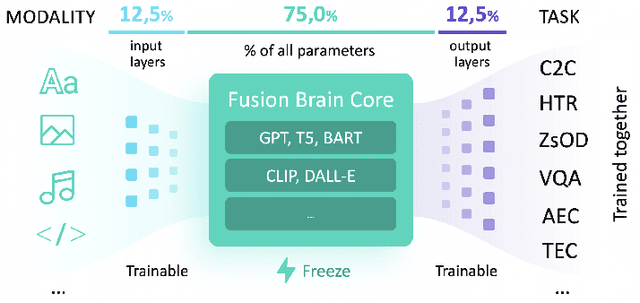
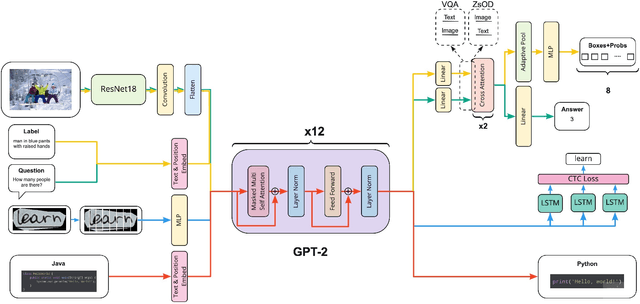
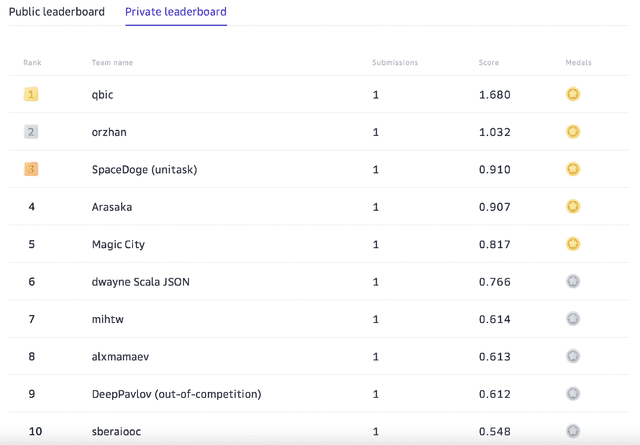
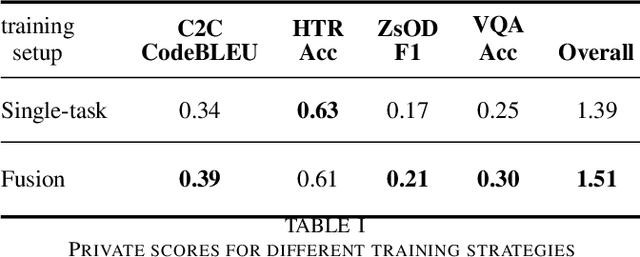
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
StackMix and Blot Augmentations for Handwritten Text Recognition
Aug 26, 2021


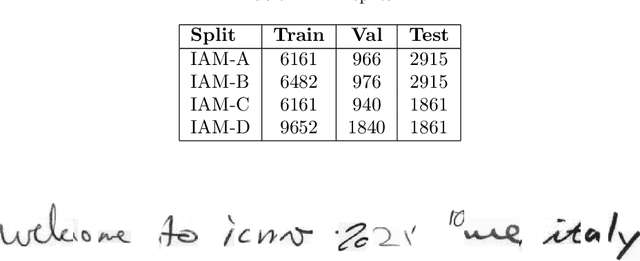
This paper proposes a handwritten text recognition(HTR) system that outperforms current state-of-the-artmethods. The comparison was carried out on three of themost frequently used in HTR task datasets, namely Ben-tham, IAM, and Saint Gall. In addition, the results on tworecently presented datasets, Peter the Greats manuscriptsand HKR Dataset, are provided.The paper describes the architecture of the neural net-work and two ways of increasing the volume of train-ing data: augmentation that simulates strikethrough text(HandWritten Blots) and a new text generation method(StackMix), which proved to be very effective in HTR tasks.StackMix can also be applied to the standalone task of gen-erating handwritten text based on printed text.
Digital Peter: Dataset, Competition and Handwriting Recognition Methods
Mar 16, 2021


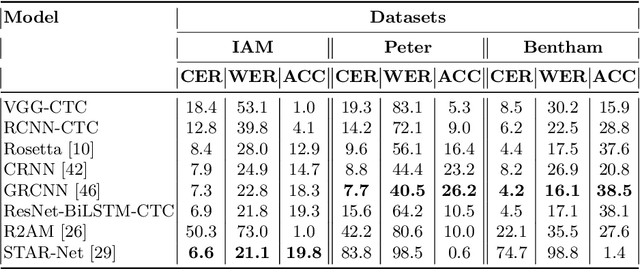
This paper presents a new dataset of Peter the Great's manuscripts and describes a segmentation procedure that converts initial images of documents into the lines. The new dataset may be useful for researchers to train handwriting text recognition models as a benchmark for comparing different models. It consists of 9 694 images and text files corresponding to lines in historical documents. The open machine learning competition Digital Peter was held based on the considered dataset. The baseline solution for this competition as well as more advanced methods on handwritten text recognition are described in the article. Full dataset and all code are publicly available.