 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning of sign language recognition models: a technical report
Feb 16, 2023



Sign Language Recognition (SLR) is an essential yet challenging task since sign language is performed with the fast and complex movement of hand gestures, body posture, and even facial expressions. %Skeleton Aware Multi-modal Sign Language Recognition In this work, we focused on investigating two questions: how fine-tuning on datasets from other sign languages helps improve sign recognition quality, and whether sign recognition is possible in real-time without using GPU. Three different languages datasets (American sign language WLASL, Turkish - AUTSL, Russian - RSL) have been used to validate the models. The average speed of this system has reached 3 predictions per second, which meets the requirements for the real-time scenario. This model (prototype) will benefit speech or hearing impaired people talk with other trough internet. We also investigated how the additional training of the model in another sign language affects the quality of recognition. The results show that further training of the model on the data of another sign language almost always leads to an improvement in the quality of gesture recognition. We also provide code for reproducing model training experiments, converting models to ONNX format, and inference for real-time gesture recognition.
StackMix and Blot Augmentations for Handwritten Text Recognition
Aug 26, 2021
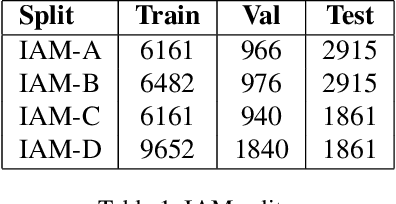


This paper proposes a handwritten text recognition(HTR) system that outperforms current state-of-the-artmethods. The comparison was carried out on three of themost frequently used in HTR task datasets, namely Ben-tham, IAM, and Saint Gall. In addition, the results on tworecently presented datasets, Peter the Greats manuscriptsand HKR Dataset, are provided.The paper describes the architecture of the neural net-work and two ways of increasing the volume of train-ing data: augmentation that simulates strikethrough text(HandWritten Blots) and a new text generation method(StackMix), which proved to be very effective in HTR tasks.StackMix can also be applied to the standalone task of gen-erating handwritten text based on printed text.
Digital Peter: Dataset, Competition and Handwriting Recognition Methods
Mar 16, 2021


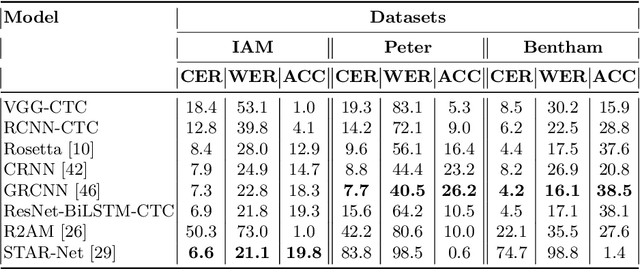
This paper presents a new dataset of Peter the Great's manuscripts and describes a segmentation procedure that converts initial images of documents into the lines. The new dataset may be useful for researchers to train handwriting text recognition models as a benchmark for comparing different models. It consists of 9 694 images and text files corresponding to lines in historical documents. The open machine learning competition Digital Peter was held based on the considered dataset. The baseline solution for this competition as well as more advanced methods on handwritten text recognition are described in the article. Full dataset and all code are publicly available.