 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStartup success prediction and VC portfolio simulation using CrunchBase data
Sep 27, 2023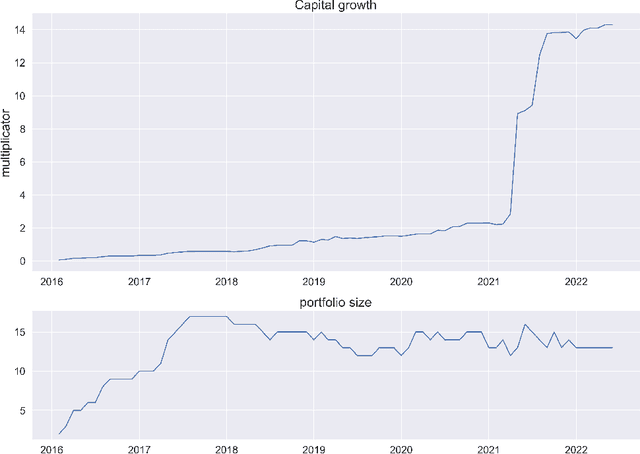
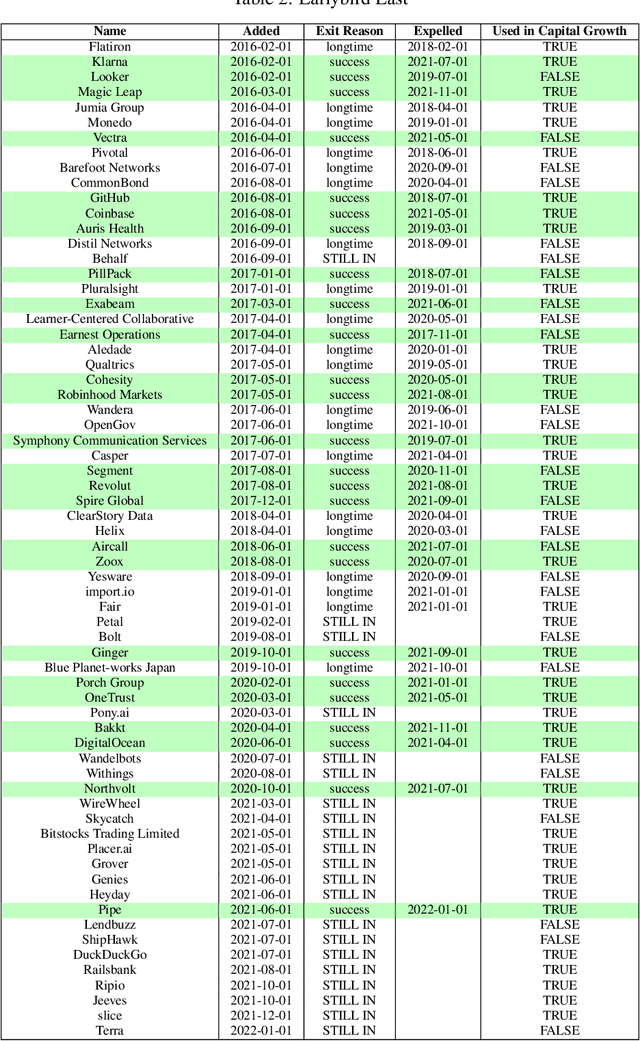
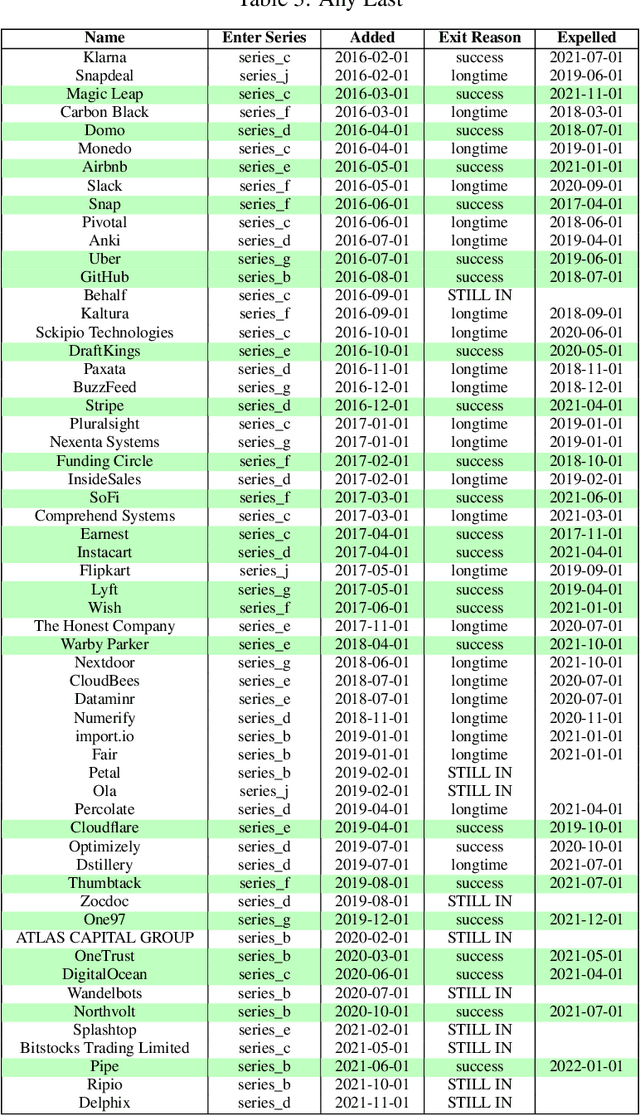
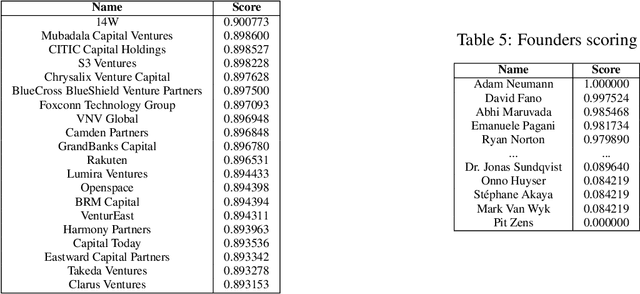
Predicting startup success presents a formidable challenge due to the inherently volatile landscape of the entrepreneurial ecosystem. The advent of extensive databases like Crunchbase jointly with available open data enables the application of machine learning and artificial intelligence for more accurate predictive analytics. This paper focuses on startups at their Series B and Series C investment stages, aiming to predict key success milestones such as achieving an Initial Public Offering (IPO), attaining unicorn status, or executing a successful Merger and Acquisition (M\&A). We introduce novel deep learning model for predicting startup success, integrating a variety of factors such as funding metrics, founder features, industry category. A distinctive feature of our research is the use of a comprehensive backtesting algorithm designed to simulate the venture capital investment process. This simulation allows for a robust evaluation of our model's performance against historical data, providing actionable insights into its practical utility in real-world investment contexts. Evaluating our model on Crunchbase's, we achieved a 14 times capital growth and successfully identified on B round high-potential startups including Revolut, DigitalOcean, Klarna, Github and others. Our empirical findings illuminate the importance of incorporating diverse feature sets in enhancing the model's predictive accuracy. In summary, our work demonstrates the considerable promise of deep learning models and alternative unstructured data in predicting startup success and sets the stage for future advancements in this research area.
DetIE: Multilingual Open Information Extraction Inspired by Object Detection
Jun 24, 2022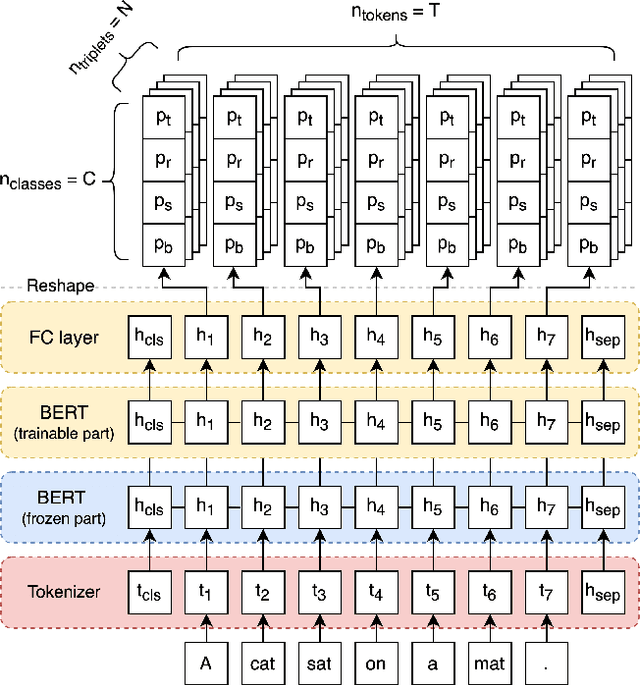
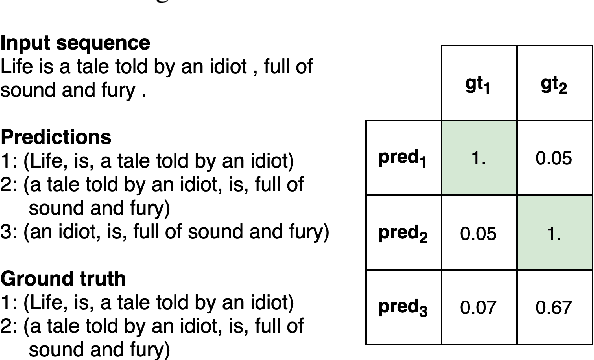

State of the art neural methods for open information extraction (OpenIE) usually extract triplets (or tuples) iteratively in an autoregressive or predicate-based manner in order not to produce duplicates. In this work, we propose a different approach to the problem that can be equally or more successful. Namely, we present a novel single-pass method for OpenIE inspired by object detection algorithms from computer vision. We use an order-agnostic loss based on bipartite matching that forces unique predictions and a Transformer-based encoder-only architecture for sequence labeling. The proposed approach is faster and shows superior or similar performance in comparison with state of the art models on standard benchmarks in terms of both quality metrics and inference time. Our model sets the new state of the art performance of 67.7% F1 on CaRB evaluated as OIE2016 while being 3.35x faster at inference than previous state of the art. We also evaluate the multilingual version of our model in the zero-shot setting for two languages and introduce a strategy for generating synthetic multilingual data to fine-tune the model for each specific language. In this setting, we show performance improvement 15% on multilingual Re-OIE2016, reaching 75% F1 for both Portuguese and Spanish languages. Code and models are available at https://github.com/sberbank-ai/DetIE.
RuCLIP -- new models and experiments: a technical report
Feb 22, 2022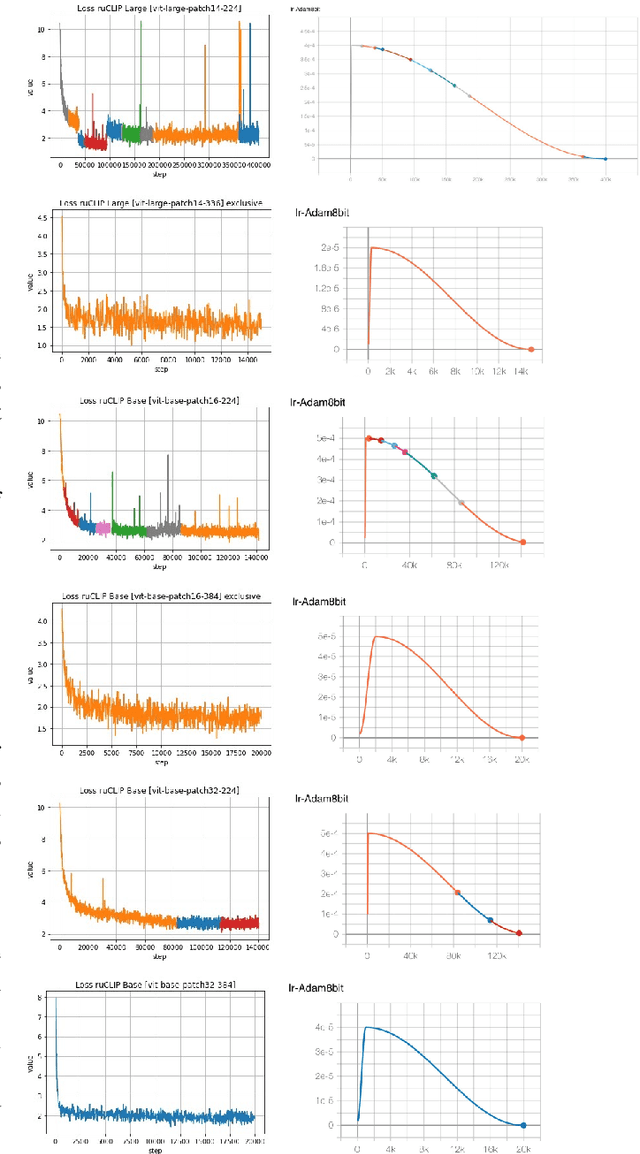
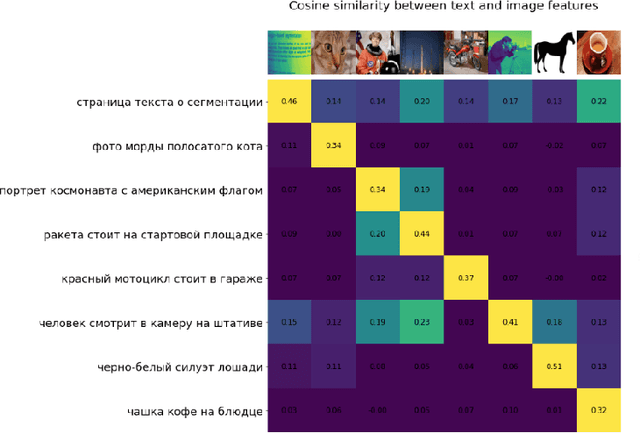
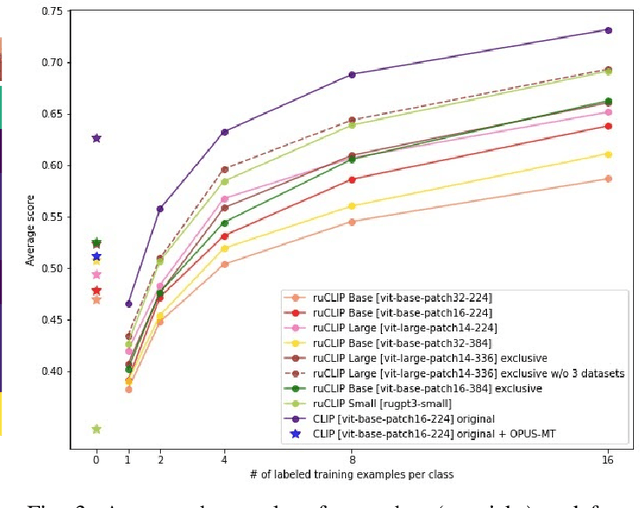
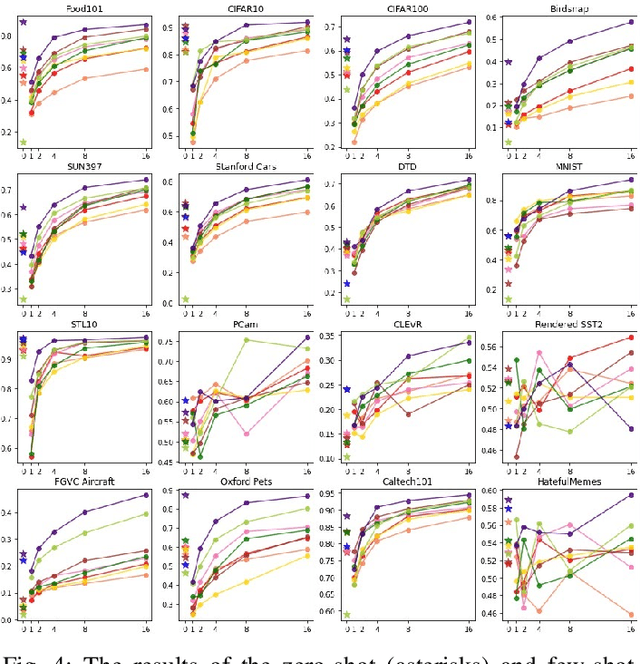
In the report we propose six new implementations of ruCLIP model trained on our 240M pairs. The accuracy results are compared with original CLIP model with Ru-En translation (OPUS-MT) on 16 datasets from different domains. Our best implementations outperform CLIP + OPUS-MT solution on most of the datasets in few-show and zero-shot tasks. In the report we briefly describe the implementations and concentrate on the conducted experiments. Inference execution time comparison is also presented in the report.
Handwritten text generation and strikethrough characters augmentation
Dec 14, 2021

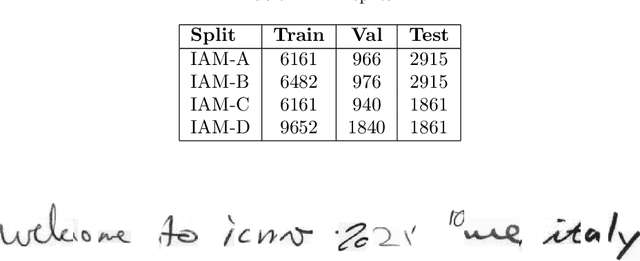
We introduce two data augmentation techniques, which, used with a Resnet-BiLSTM-CTC network, significantly reduce Word Error Rate (WER) and Character Error Rate (CER) beyond best-reported results on handwriting text recognition (HTR) tasks. We apply a novel augmentation that simulates strikethrough text (HandWritten Blots) and a handwritten text generation method based on printed text (StackMix), which proved to be very effective in HTR tasks. StackMix uses weakly-supervised framework to get character boundaries. Because these data augmentation techniques are independent of the network used, they could also be applied to enhance the performance of other networks and approaches to HTR. Extensive experiments on ten handwritten text datasets show that HandWritten Blots augmentation and StackMix significantly improve the quality of HTR models
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021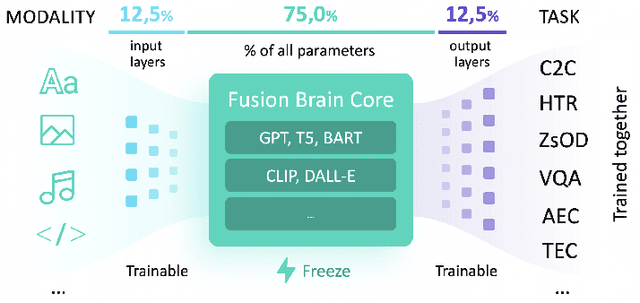
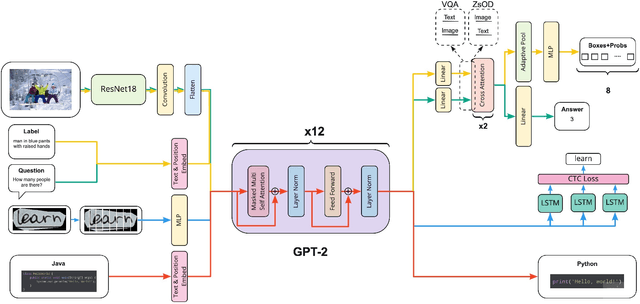
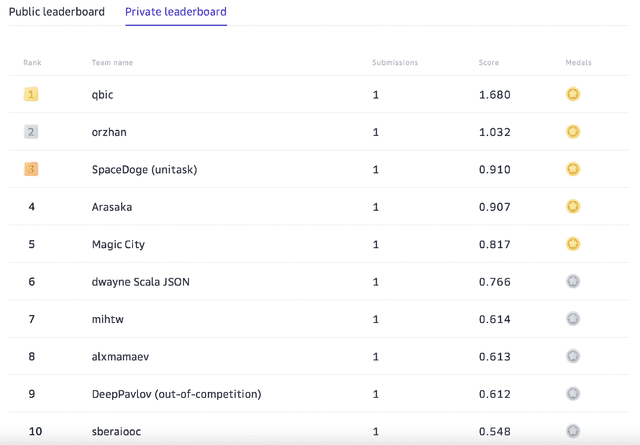
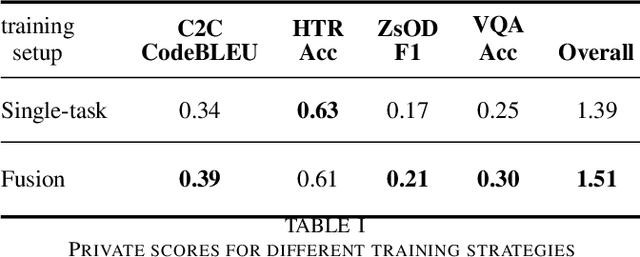
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
Hybrid Graph Embedding Techniques in Estimated Time of Arrival Task
Oct 08, 2021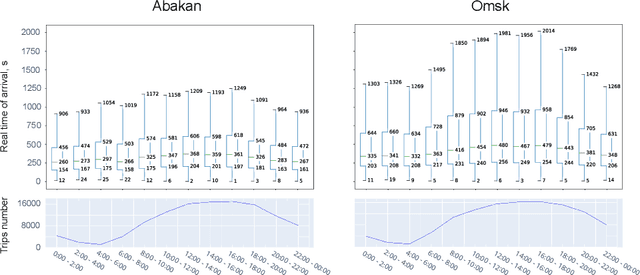
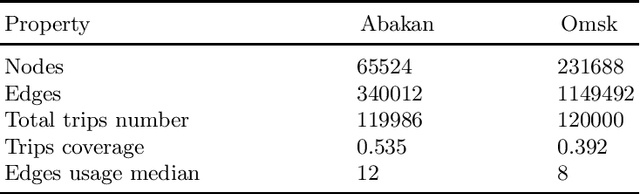
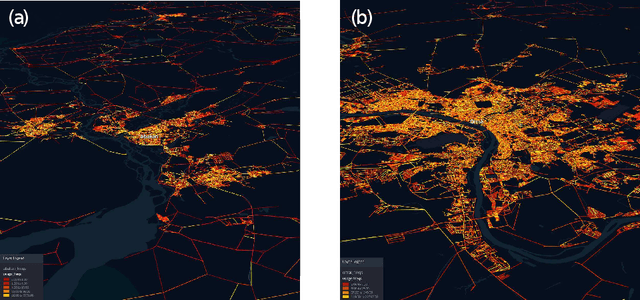
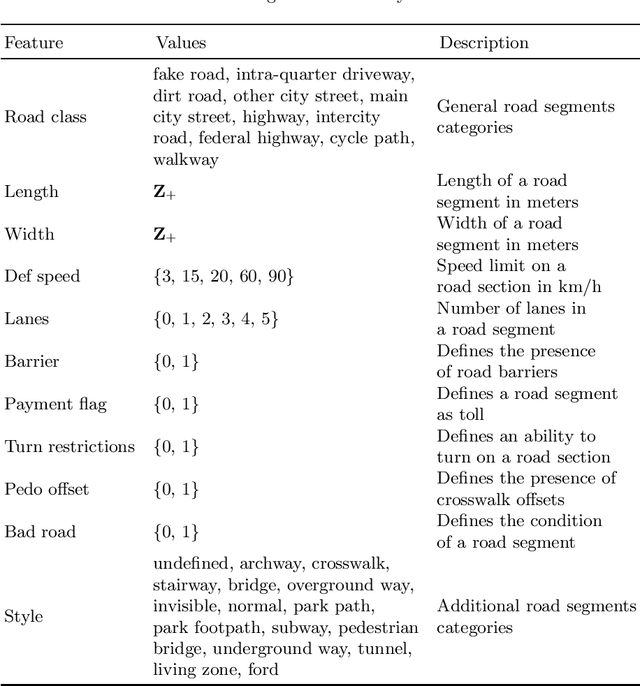
Recently, deep learning has achieved promising results in the calculation of Estimated Time of Arrival (ETA), which is considered as predicting the travel time from the start point to a certain place along a given path. ETA plays an essential role in intelligent taxi services or automotive navigation systems. A common practice is to use embedding vectors to represent the elements of a road network, such as road segments and crossroads. Road elements have their own attributes like length, presence of crosswalks, lanes number, etc. However, many links in the road network are traversed by too few floating cars even in large ride-hailing platforms and affected by the wide range of temporal events. As the primary goal of the research, we explore the generalization ability of different spatial embedding strategies and propose a two-stage approach to deal with such problems.
RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark
Nov 02, 2020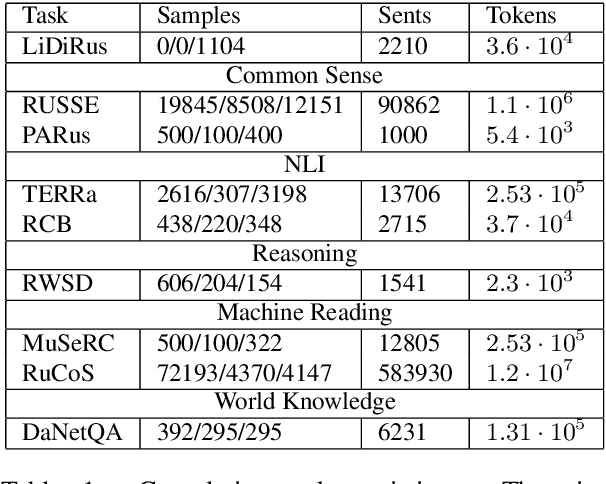

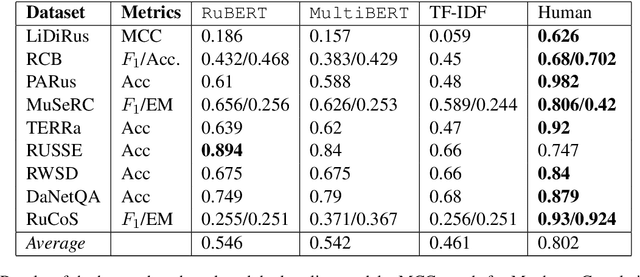

In this paper, we introduce an advanced Russian general language understanding evaluation benchmark -- RussianGLUE. Recent advances in the field of universal language models and transformers require the development of a methodology for their broad diagnostics and testing for general intellectual skills - detection of natural language inference, commonsense reasoning, ability to perform simple logical operations regardless of text subject or lexicon. For the first time, a benchmark of nine tasks, collected and organized analogically to the SuperGLUE methodology, was developed from scratch for the Russian language. We provide baselines, human level evaluation, an open-source framework for evaluating models (https://github.com/RussianNLP/RussianSuperGLUE), and an overall leaderboard of transformer models for the Russian language. Besides, we present the first results of comparing multilingual models in the adapted diagnostic test set and offer the first steps to further expanding or assessing state-of-the-art models independently of language.