 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical thematic classification of major conference proceedings
Jun 21, 2024



In this paper, we develop a decision support system for the hierarchical text classification. We consider text collections with a fixed hierarchical structure of topics given by experts in the form of a tree. The system sorts the topics by relevance to a given document. The experts choose one of the most relevant topics to finish the classification. We propose a weighted hierarchical similarity function to calculate topic relevance. The function calculates the similarity of a document and a tree branch. The weights in this function determine word importance. We use the entropy of words to estimate the weights. The proposed hierarchical similarity function formulates a joint hierarchical thematic classification probability model of the document topics, parameters, and hyperparameters. The variational Bayesian inference gives a closed-form EM algorithm. The EM algorithm estimates the parameters and calculates the probability of a topic for a given document. Compared to hierarchical multiclass SVM, hierarchical PLSA with adaptive regularization, and hierarchical naive Bayes, the weighted hierarchical similarity function has better improvement in ranking accuracy in an abstract collection of a major conference EURO and a website collection of industrial companies.
Additive regularization schedule for neural architecture search
Jun 18, 2024Neural network structures have a critical impact on the accuracy and stability of forecasting. Neural architecture search procedures help design an optimal neural network according to some loss function, which represents a set of quality criteria. This paper investigates the problem of neural network structure optimization. It proposes a way to construct a loss function, which contains a set of additive elements. Each element is called the regularizer. It corresponds to some part of the neural network structure and represents a criterion to optimize. The optimization procedure changes the structure in iterations. To optimize various parts of the structure, the procedure changes the set of regularizers according to some schedule. The authors propose a way to construct the additive regularization schedule. By comparing regularized models with non-regularized ones for a collection of datasets the computational experiments show that the proposed method finds efficient neural network structure and delivers accurate networks of low complexity.
Position-based Content Attention for Time Series Forecasting with Sequence-to-sequence RNNs
Aug 21, 2017
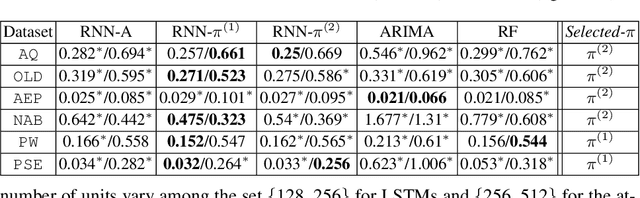
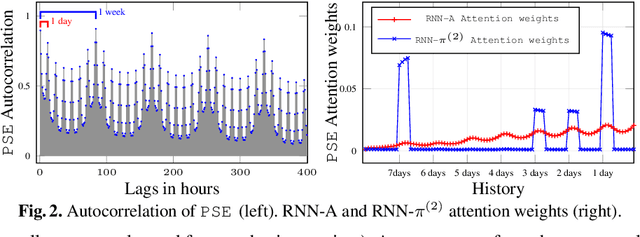

We propose here an extended attention model for sequence-to-sequence recurrent neural networks (RNNs) designed to capture (pseudo-)periods in time series. This extended attention model can be deployed on top of any RNN and is shown to yield state-of-the-art performance for time series forecasting on several univariate and multivariate time series.