 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGallery-Aware Uncertainty Estimation For Open-Set Face Recognition
Aug 26, 2024

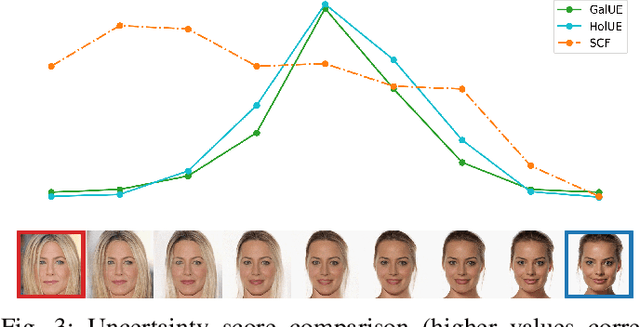
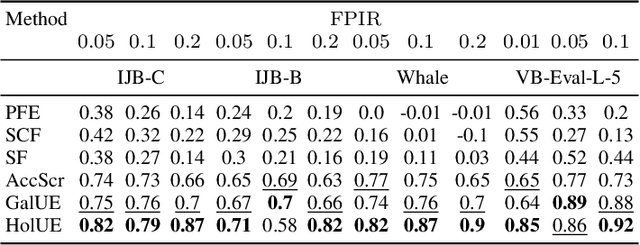
Accurately estimating image quality and model robustness improvement are critical challenges in unconstrained face recognition, which can be addressed through uncertainty estimation via probabilistic face embeddings. Previous research mainly focused on uncertainty estimation in face verification, leaving the open-set face recognition task underexplored. In open-set face recognition, one seeks to classify an image, which could also be unknown. Here, the low variance of probabilistic embedding does not imply a low error probability: an image embedding could be close to several classes in a gallery, thus yielding high uncertainty. We propose a method aware of two sources of ambiguity in the open-set recognition system: (1) the gallery uncertainty caused by overlapping classes and (2) the uncertainty of the face embeddings. To detect both types, we use a Bayesian probabilistic model of embedding distribution, which provides a principled uncertainty estimate. Challenging open-set face recognition datasets, such as IJB-C, serve as a testbed for our method. We also propose a new open-set recognition protocol for whale and dolphin identification. The proposed approach better identifies recognition errors than uncertainty estimation methods based solely on image quality.
Uncertainty estimation for time series forecasting via Gaussian process regression surrogates
Feb 06, 2023Machine learning models are widely used to solve real-world problems in science and industry. To build robust models, we should quantify the uncertainty of the model's predictions on new data. This study proposes a new method for uncertainty estimation based on the surrogate Gaussian process model. Our method can equip any base model with an accurate uncertainty estimate produced by a separate surrogate. Compared to other approaches, the estimate remains computationally effective with training only one additional model and doesn't rely on data-specific assumptions. The only requirement is the availability of the base model as a black box, which is typical. Experiments for challenging time-series forecasting data show that surrogate model-based methods provide more accurate confidence intervals than bootstrap-based methods in both medium and small-data regimes and different families of base models, including linear regression, ARIMA, and gradient boosting.
LSDNet: Trainable Modification of LSD Algorithm for Real-Time Line Segment Detection
Sep 10, 2022



As of today, the best accuracy in line segment detection (LSD) is achieved by algorithms based on convolutional neural networks - CNNs. Unfortunately, these methods utilize deep, heavy networks and are slower than traditional model-based detectors. In this paper we build an accurate yet fast CNN- based detector, LSDNet, by incorporating a lightweight CNN into a classical LSD detector. Specifically, we replace the first step of the original LSD algorithm - construction of line segments heatmap and tangent field from raw image gradients - with a lightweight CNN, which is able to calculate more complex and rich features. The second part of the LSD algorithm is used with only minor modifications. Compared with several modern line segment detectors on standard Wireframe dataset, the proposed LSDNet provides the highest speed (among CNN-based detectors) of 214 FPS with a competitive accuracy of 78 Fh . Although the best-reported accuracy is 83 Fh at 33 FPS, we speculate that the observed accuracy gap is caused by errors in annotations and the actual gap is significantly lower. We point out systematic inconsistencies in the annotations of popular line detection benchmarks - Wireframe and York Urban, carefully reannotate a subset of images and show that (i) existing detectors have improved quality on updated annotations without retraining, suggesting that new annotations correlate better with the notion of correct line segment detection; (ii) the gap between accuracies of our detector and others diminishes to negligible 0.2 Fh , with our method being the fastest.