 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNNAbacus: Toward Accurate Computational Cost Prediction for Deep Neural Networks
May 24, 2022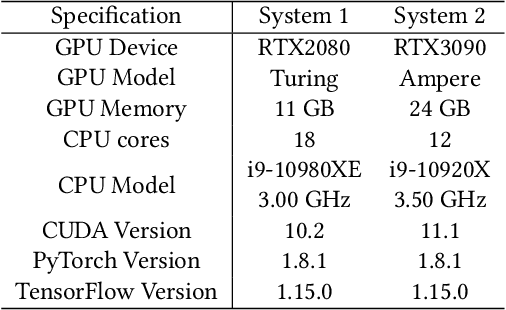
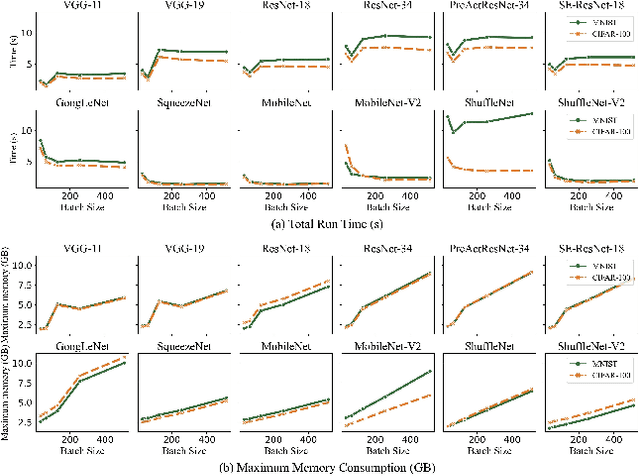
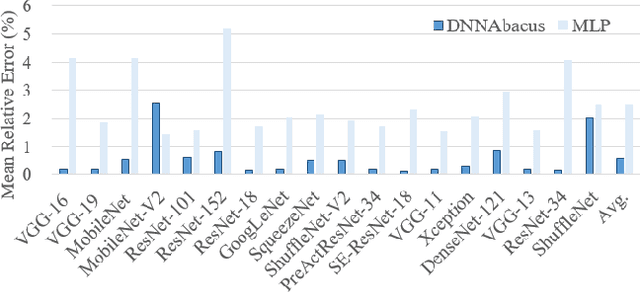
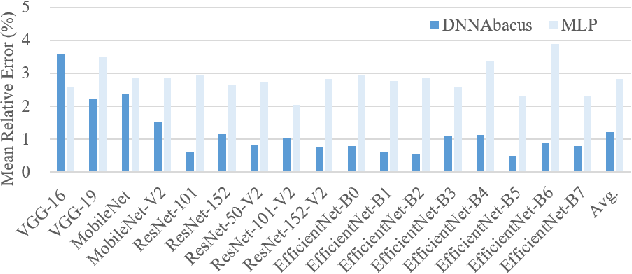
Deep learning is attracting interest across a variety of domains, including natural language processing, speech recognition, and computer vision. However, model training is time-consuming and requires huge computational resources. Existing works on the performance prediction of deep neural networks, which mostly focus on the training time prediction of a few models, rely on analytical models and result in high relative errors. %Optimizing task scheduling and reducing job failures in data centers are essential to improve resource utilization and reduce carbon emissions. This paper investigates the computational resource demands of 29 classical deep neural networks and builds accurate models for predicting computational costs. We first analyze the profiling results of typical networks and demonstrate that the computational resource demands of models with different inputs and hyperparameters are not obvious and intuitive. We then propose a lightweight prediction approach DNNAbacus with a novel network structural matrix for network representation. DNNAbacus can accurately predict both memory and time cost for PyTorch and TensorFlow models, which is also generalized to different hardware architectures and can have zero-shot capability for unseen networks. Our experimental results show that the mean relative error (MRE) is 0.9% with respect to time and 2.8% with respect to memory for 29 classic models, which is much lower than the state-of-the-art works.
Topology-based Clusterwise Regression for User Segmentation and Demand Forecasting
Sep 08, 2020
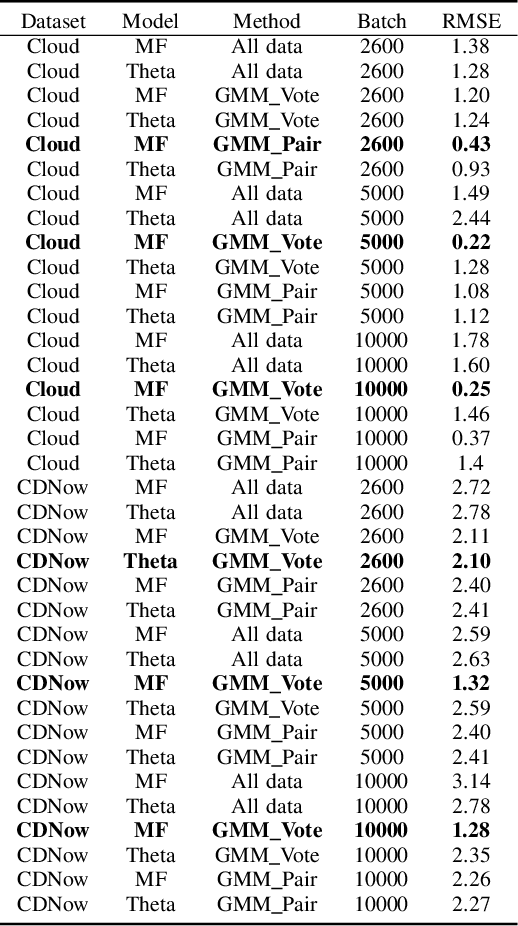

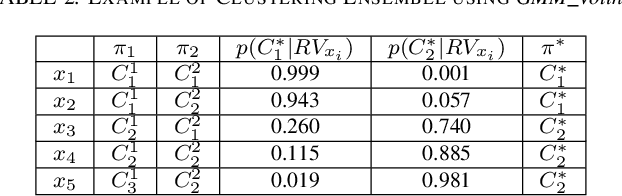
Topological Data Analysis (TDA) is a recent approach to analyze data sets from the perspective of their topological structure. Its use for time series data has been limited. In this work, a system developed for a leading provider of cloud computing combining both user segmentation and demand forecasting is presented. It consists of a TDA-based clustering method for time series inspired by a popular managerial framework for customer segmentation and extended to the case of clusterwise regression using matrix factorization methods to forecast demand. Increasing customer loyalty and producing accurate forecasts remain active topics of discussion both for researchers and managers. Using a public and a novel proprietary data set of commercial data, this research shows that the proposed system enables analysts to both cluster their user base and plan demand at a granular level with significantly higher accuracy than a state of the art baseline. This work thus seeks to introduce TDA-based clustering of time series and clusterwise regression with matrix factorization methods as viable tools for the practitioner.